pandas 进阶
Posted 辰chen
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了pandas 进阶相关的知识,希望对你有一定的参考价值。
目录
前言
本文其实属于:Python的进阶之道【AIoT阶段一】的一部分内容,本篇把这部分内容单独截取出来,方便大家的观看,本文介绍 pandas 高级,读本文之前建议先修:pandas 入门,pandas 高级
1.数据重塑
🚩数据重塑其实就是行变列,列变行
1.1 一般数据
import numpy as np
import pandas as pd
df = pd.DataFrame(data = np.random.randint(0, 100, size = (10, 3)),
index = list('ABCDEFHIJK'),
columns = ['Python', 'Tensorflow', 'Keras'])
display(df)
# 转置
df.T

1.2 多层索引
df2 = pd.DataFrame(data = np.random.randint(0, 100, size = (20, 3)),
index = pd.MultiIndex.from_product([list('ABCDEFHIJK'),
['期中', '期末']]),#多层索引
columns = ['Python', 'Tensorflow', 'Keras'])
df2
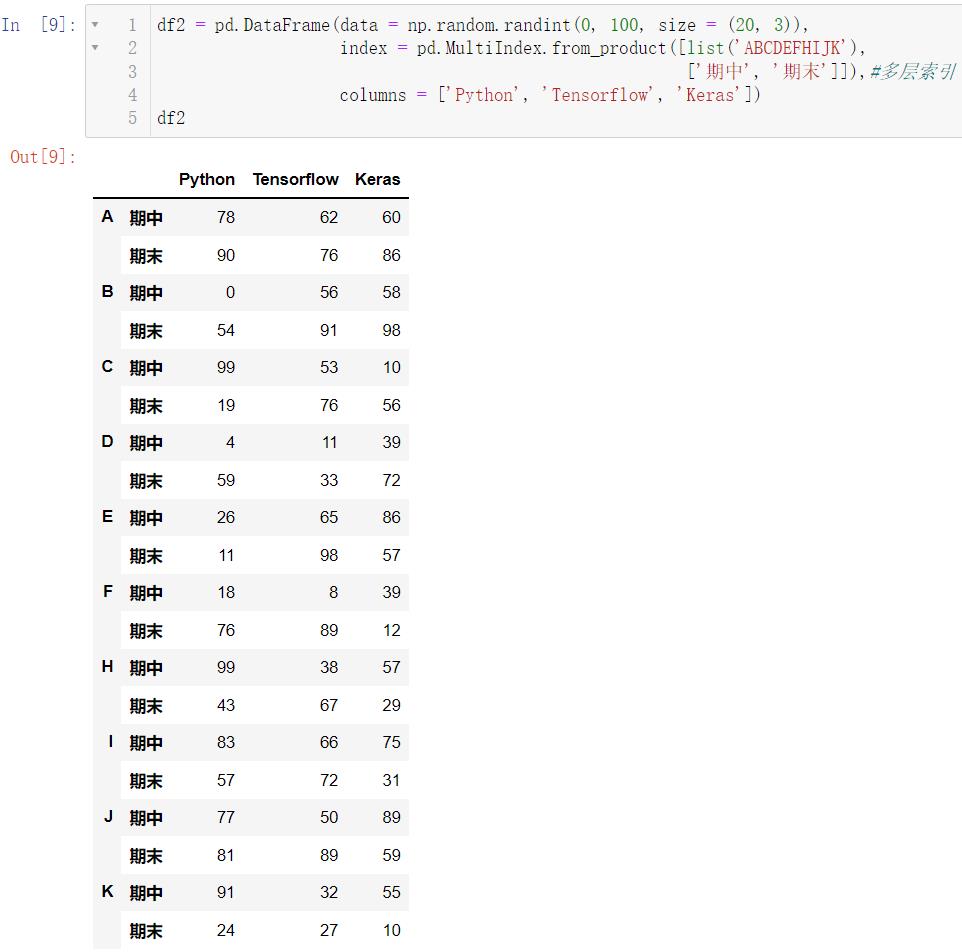
我们来解释一下这个复杂的代码:ndex = pd.MultiIndex.from_product([list('ABCDEFHIJK'), ['期中', '期末']]),我们的第一个参数:ABCDEFHIJK,共是
10
10
10 个字母,第二个参数是两个字符串,所以我们一共会有
20
20
20 行的数据,这正好对应了前面的代码size = (20, 3),读者自行理解下面这个代码:
df3 = pd.DataFrame(data = np.random.randint(0, 100, size = (10, 6)),
index = list('ABCDEFHIJK'),
columns = pd.MultiIndex.from_product([['Python', 'Math', 'English'],
['期中', '期末']]))
df3

我们用 unstack() 完成多层索引行变列的数据重塑:
# 行索引变列索引,结构改变
# 默认情况下,最里层调整
df2.unstack()
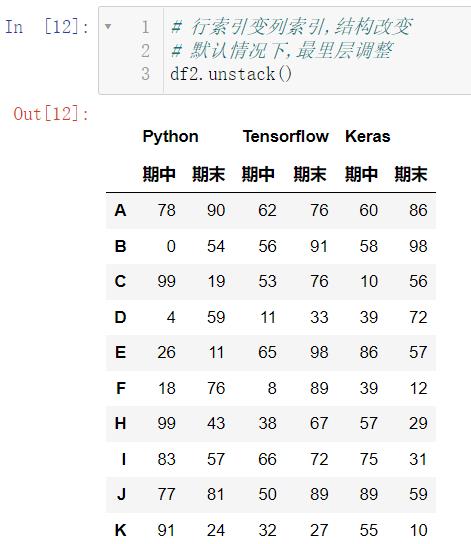
可以看出来,只是把行索引最里层的期中期末 移到了列索引的位置,我们也可以把行索引外层的 ABCDEFHIJK 移动至列索引的位置:
df2.unstack(level = 0)

我们用 stack() 完成多层索引列变行的数据重塑:
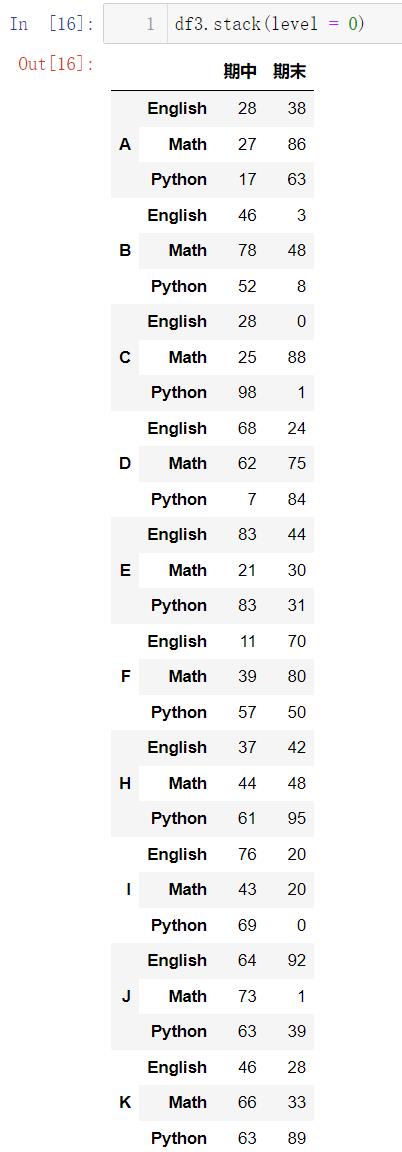
# 列索引变行索引,结构改变
# 默认情况下,最里层调整
df3.stack()

同样,我们通过调整参数可以实现使得列索引的最外层变成行索引:
df3.stack(level = 0)
1.3 多层索引的运算
sum() 求和运算:
df2.sum()

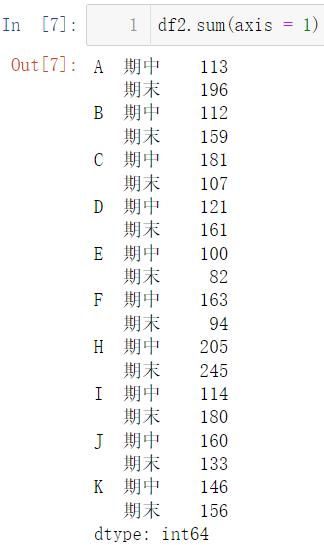
当然,这样的数据一般是没有意义的,我们一般想要求出每一位同学的总分,而不是每门科目的总分:
df2.sum(axis = 1)
# 期中,期末消失
# 计算的是每个人,期中期末的总分数
df2.sum(level = 0)

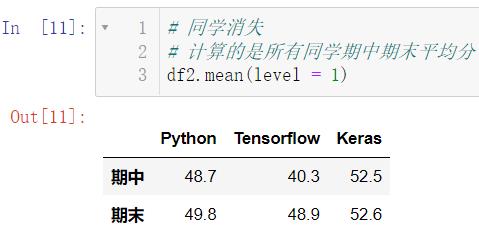
mean() 用来计算平均分:
# 同学消失
# 计算的是所有同学期中期末平均分
df2.mean(level = 1)
接下来简单介绍一下如何取数据:
# df3是多层列索引,可以直接使用[],根据层级关系取数据
# 取出 A 同学的 Python 科目的期中成绩
df3['Python', '期中']['A']

df2['Python']['A', '期中']

2.数学和统计方法
🚩pandas对象拥有一组常用的数学和统计方法。它们属于汇总统计,对Series汇总计算获取mean、max值或者对DataFrame行、列汇总计算返回一个Series。
2.1 简单统计指标
创建数据:
import numpy as np
import pandas as pd
df = pd.DataFrame(data = np.random.randint(0, 100,size = (20, 3)),
index = list('ABCDEFHIJKLMNOPQRSTU'),
columns = ['Python', 'Tensorflow', 'Keras'])
df
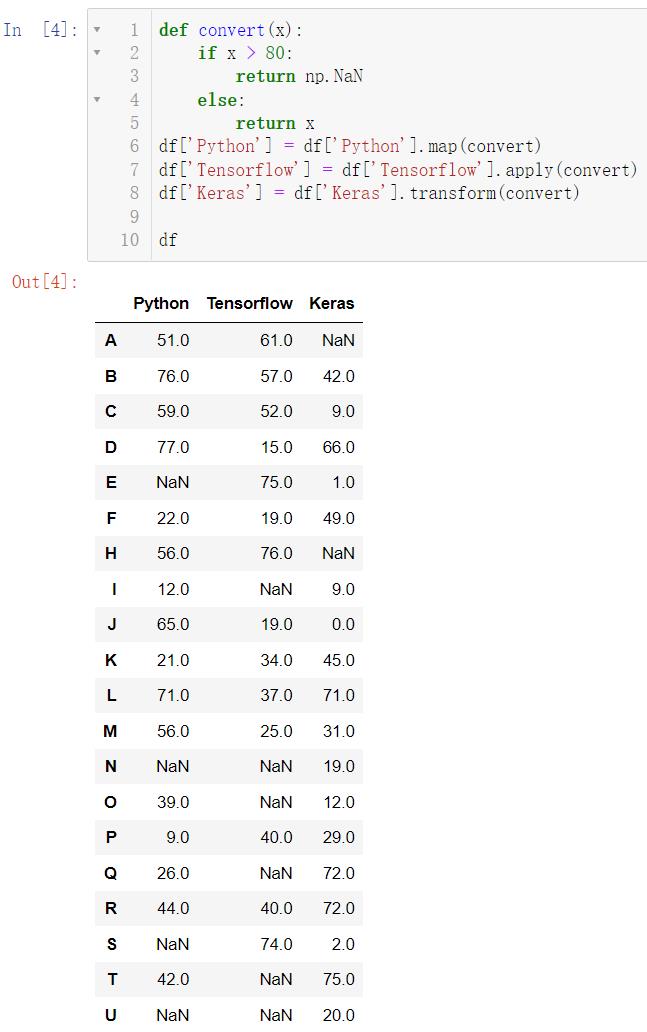
我们现在来把一部分数据设置为空:
def convert(x):
if x > 80:
return np.NaN
else:
return x
df['Python'] = df['Python'].map(convert)
df['Tensorflow'] = df['Tensorflow'].apply(convert)
df['Keras'] = df['Keras'].transform(convert)
df
现在我们想知道到底有多少个空数据,我们可以自己去数,但这显然是低效的方法,使用 count() 函数可以直接去统计有多少个非空数据:
df.count() # 统计非空数据的个数

我们重新来构造数据:
import numpy as np
import pandas as pd
df = pd.DataFrame(data = np.random.randint(0, 100,size = (20, 3)),
index = list('ABCDEFHIJKLMNOPQRSTU'),
columns = ['Python', 'Tensorflow', 'Keras'])
df
使用 median() 可以计算数据的中位数:
df.median() # 中位数

display(df.quantile(q = 0.5)) # 返回位于数据 50% 位置的数
display(df.quantile(q = 0.8)) # 返回位于数据 80% 位置的数

我们也可以使用如下的方法实现同样的效果:
df.quantile(q = [0.5, 0.8])

2.2 索引标签、位置获取
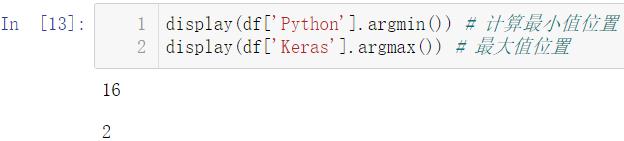
display(df['Python'].argmin()) # 计算最小值位置
display(df['Keras'].argmax()) # 最大值位置
display(df.idxmax()) # 最大值索引标签
display(df.idxmin()) # 最小值索引标签
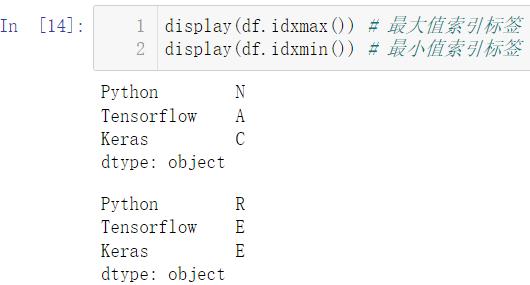
索引就是自然数,标签就是我们初始设置的 ABCD…,索引和标签是一一对应的,如 0 对应的就是 A
2.3 更多统计指标
创建数据:
import numpy as np
import pandas as pd
df = pd.DataFrame(data = np.random.randint(0, 5,size = (20, 3)),
index = list('ABCDEFHIJKLMNOPQRSTU'),
columns = ['Python', 'Tensorflow', 'Keras'])
df

使用 value_counts() 可以统计元素出现的次数:
# 统计元素出现次数
df['Python'].value_counts()

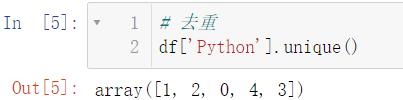
使用 unique() 可以实现去重:
# 去重
df['Python'].unique()
调用 cumsum() 实现累加,调用 cumprod() 实现累乘:
# 累加
display(df.cumsum())
# 累乘
display(df.cumprod())

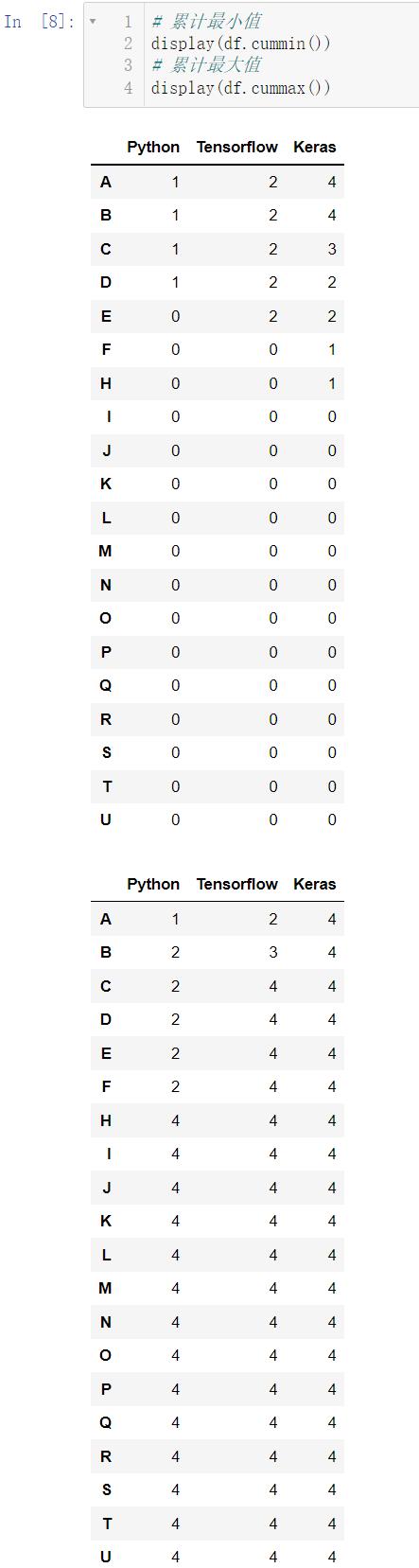
cummin() 的作用是累计最小值,即碰到更小的数后,该数往后所有数都变成这个更小的数,cummax() 的作用是累计最大值,即碰到更大的数后,该数往后所有的数都变成这个更大的数:
# 累计最小值
display(df.cummin())
# 累计最大值
display(df.cummax())
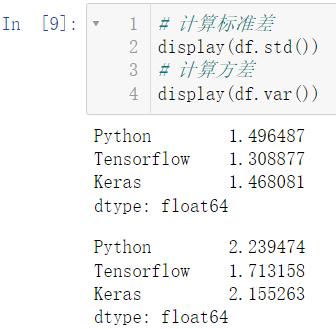
计算标准差调用 std(),计算方差调用 var()
# 计算标准差
display(df.std())
# 计算方差
display(df.var())
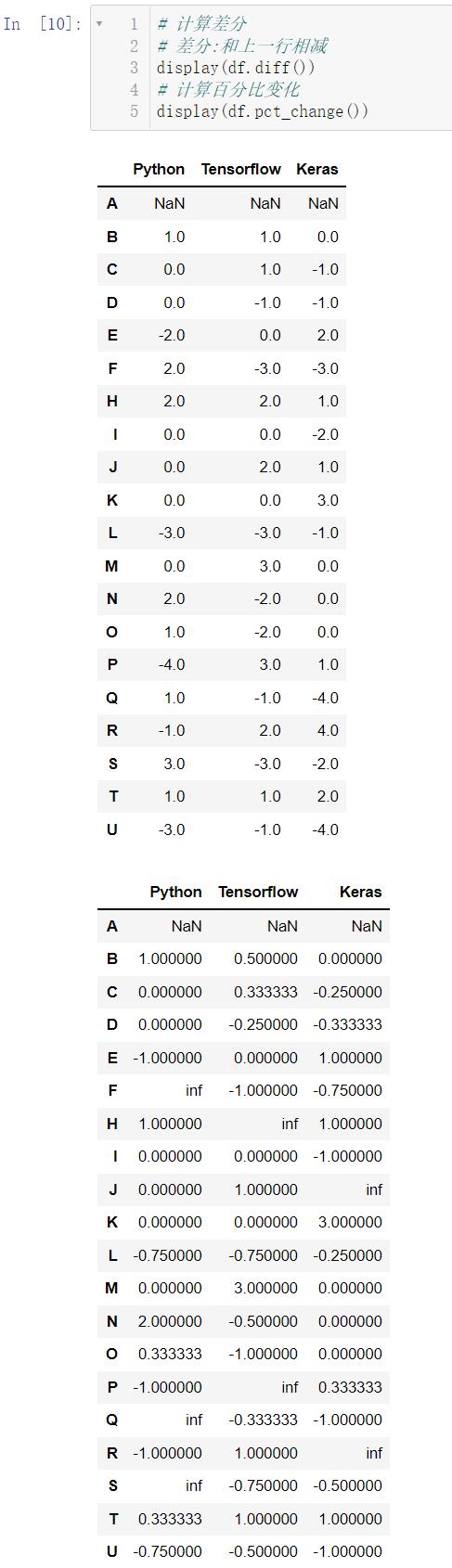
计算差分使用 diff(),差分就是这一行减上一行的结果,计算百分比的变化使用 pct_change():
# 计算差分
# 差分:和上一行相减
display(df.diff())
# 计算百分比变化
display(df.pct_change())
2.4 高级统计指标
我们使用 cov() 和 corr() 用来分别计算协方差和相关性系数:
协方差: C o v ( X , Y ) = ∑ 1 n ( X i − X ‾ ) ( Y i − Y ‾ ) n − 1 Cov(X,Y) = \\frac\\sum_1^n(X_i-\\overlineX)(Y_i-\\overlineY)n-1 Cov(X,Y)=n−1∑1n(Xi−X)(Yi−Y)
相关性系数: r ( X , Y ) = C o v ( X , Y ) V a r [ X ] V a r [ Y ] r(X,Y) = \\fracCov(X,Y)\\sqrtVar[X]Var[Y] r(X,Y)=Var[X]Var[Y]Cov(X,Y)
# 属性的协方差
display(df.cov())
# Python和Keras的协方差
display(df['Python'].cov(df['Keras']))

# 所有属性相关性系数
display(df.corr())
# 单一属性相关性系数
display(df.corrwith(df['Tensorflow']))

3.数据排序
创建数据
import numpy as np
import pandas as pd
df = pd.DataFrame(data = np.random.randint(0, 30, size = (30, 3)),
index = list('qwertyuioijhgfcasdcvbnerfghjcf'),
columns = ['Python', 'Keras', 'Pytorch'])
df

是一个看起来乱糟糟的数据,我们排序介绍三种方法
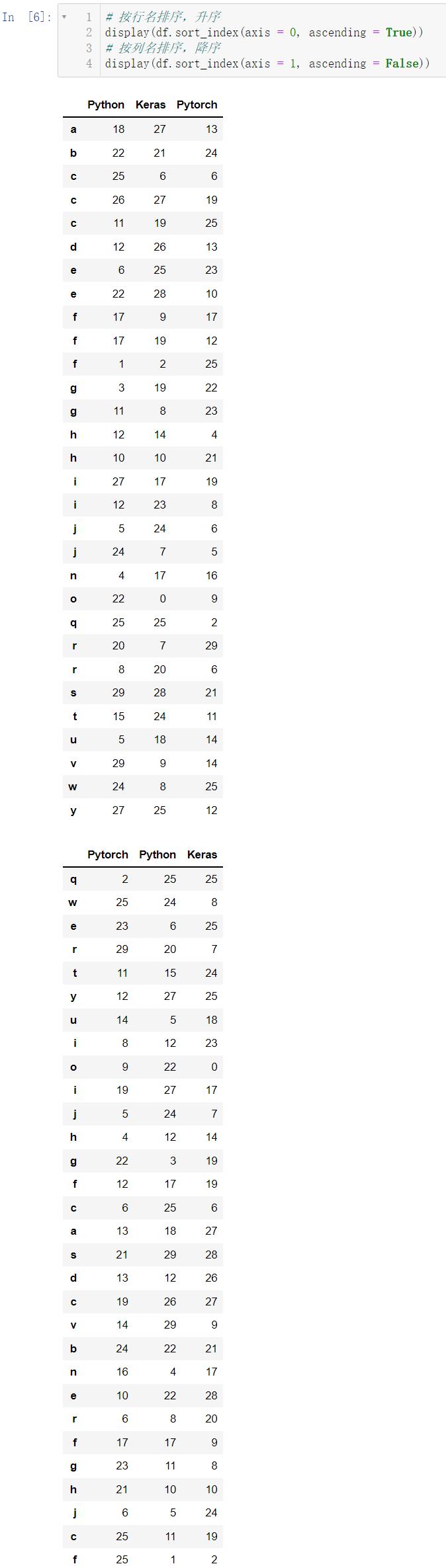
3.1 根据索引行列名进行排序
# 按行名排序,升序
display(df.sort_index(axis = 0, ascending = True))
# 按列名排序,降序
display(df.sort_index(axis = 1, ascending = False))
当然,按照索引行列名进行排序是不常用的,我们一般都是对数据进行排序
3.2 属性值排序
# 按Python属性值排序
display(df.sort_values(by = ['Python']))
# 先按Python,再按Keras排序
display(df.sort_values(by = ['Python', 'Keras']))

3.3 返回属性n大或者n小的值
# 根据属性Keras排序,返回最大3个数据
display(df.nlargest(3, columns = 'Keras'))
# 根据属性Python排序,返回最小5个数据
display(df.nsmallest(5, columns = 'Python'))

4.分箱操作
🚩分箱操作就是将连续数据转换为分类对应物的过程。比如将连续的身高数据划分为:矮中高。
分箱操作分为等距分箱和等频分箱。
分箱操作也叫面元划分或者离散化。
我们先来创建数据:
import numpy as np
import pandas as pd
df = pd.DataFrame(data = np.random.randint(0, 150, size = (100, 3)),
columns = ['Python', 'Tensorflow', 'Keras'])
df

4.1 等宽分箱
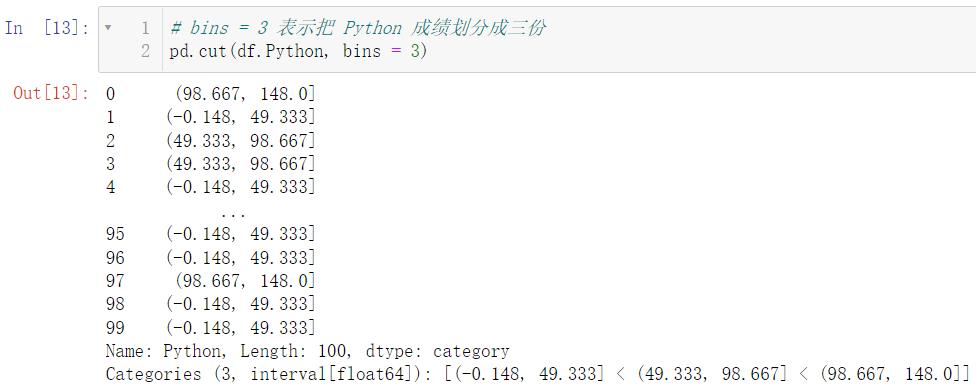
🚩等宽分箱在实际操作中意义不大,因为我们一般都会给一个特定的分类标准,比如高于 60 是及格,等分在生活中应用并不多
# bins = 3 表示把 Python 成绩划分成三份
pd.cut(df.Python, bins = 3)
4.2 指定宽度分箱
🚩下述代码就实现了自行定义宽度进行分箱操作,在下述带啊中,不及格是
[
0
,
60
)
[0,60)
[0,60),中等是
[
60
,
90
)
[60, 90)
[60,90),良好是
[
90
,
120
)
[90, 120)
[90,120),优秀是
[
120
,
150
)
[120, 150)
[120,150) 均为左闭右开,这个是由 right = False 设定的
pd.cut(df.Keras, #分箱数据
bins = [0, 60, 90, 120, 150], # 分箱断点
right = False, # 左闭右开
labels=['不及格'