一周入门MySQL—2单表查询
Posted SAP剑客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一周入门MySQL—2单表查询相关的知识,希望对你有一定的参考价值。
单表查询
数据查询语言DQL
单表查询的基本语法:
- 全表查询:select * from 表名;
- 查询指定列:select 字段1[,字段2] from 表名;
- 别名的设置:select 字段 [as] 列别名from 表名 [as] 表别名;
- 查询不重复的记录:select distinct 字段名 from 表名;
- 条件查询:select 字段1[,字段2] from 表名 where 查询条件;
- 空值查询:select 字段1[,字段2] from 表名 where 空值字段 is [not] null;
- 模糊查询:select 字段1[,字段2] from 表名 where 字符串字段 [not] like 通配符;
模糊查询通配符:
百分号(%) 通配符:匹配多个字符;
下划线(_) 通配符:匹配一个字符;
 查询结果为临时存在的虚拟结果集。
查询结果为临时存在的虚拟结果集。
--设置别名
select *,sal+1000 as 调薪 from emp;
select *,sal+1000 挑衅 from emp;其中as可以省略,如下面的查询语句。
select empno,ename,sal*12 年薪 from emp;
distinct 可以对一个字段或者多个字段去重。
distinct 多字段去重的时候位于第一个字段的前面。
运算符:
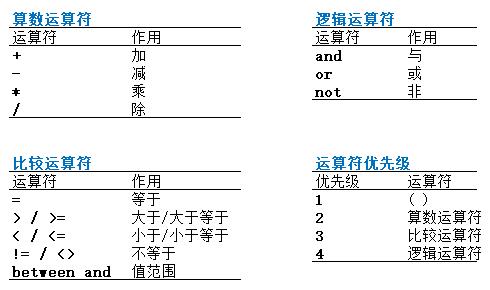
运算顺序:算数运算符 > 比较运算符 > 逻辑运算符
需要改变运算顺序,可以添加括号。
比较运算符:between and 表示闭区间,类似于 大于等于 XXX 小于等于 XXX
-- 条件查询 查询工资大于等于8000小于等于9000的记录
select * from emp where sal >= 8000 and sal <= 9000;
select * from emp where sal between 8000 and 9000;
-- 条件查询 查询部门是11和51且工资小于9000的记录
select * from emp where (deptno = 11 or deptno = 51) and sal < 9000;
-- 条件查询 查询岗位是业务员的姓名、雇佣日期、工资
select ename 姓名,hiredate 雇佣日期,sal 工资 from emp where job = '业务员';
-- 空值查询(null不能进行等值判断)
-- select * from emp where mgr = null;
select * from emp where mgr is null;
-- 模糊查询 查询姓张的员工信息(仅字符串类型字段)
select * from emp where ename like '张%';
-- 模糊查询 查询姓张且名字是三个字的员工信息
select * from emp where ename like '张__';
-- 模糊查询 查询姓名中包含龙字的员工信息
select * from emp where ename like '%龙%';
-- 模糊查询 查询姓名中不包含龙字的员工信息
select * from emp where ename not like '%龙%';查询结果控制:
查询结果排序:select 字段1[,字段2] from 表名 order by 字段1 [排序方向,字段2 排序方向......];
多个字段排序时,先按照第一个字段排序,第一个字段值相同时,再按照第二个字段排序;
排序方向:asc升序,desc降序,没有指定排序方向时,默认是升序;
限制查询结果数量:select 字段1[,字段2] from 表名 limit [偏移量,] 行数;
limit接受一个或者两个数字参数,参数必须是一个整数常量;
第一个参数指定第一个返回记录行的偏移量,第二个参数指定返回记录行的最大数目;
如果只给定一个参数,表示返回最大的记录行数目;
初始记录行的偏移量是0(切记不是1);
-- 所有的员工信息按照工资的降序排列
select * from emp order by sal desc;
-- 查询所有员工信息,先按照部门编号升序,再按照基本工资降序排列
select * from emp order by deptno asc,sal desc;
-- 限制查询,查询基本工资最高的前五位员工信息(相当于省略了偏移量0)
select * from emp order by sal desc limit 5;
-- 限制查询,查询基本工资排在6-8名的员工信息(limit需要两个参数,即偏移量和条目数)
-- 偏移量从0开始计算
select * from emp order by sal desc limit 5,2;
-- 查询最后入职的5名员工
select * from emp order by hiredate desc limit 5;聚合函数
- avg():列的平均值
- count():列的行数
- max():列中最大值
- min():列中最小值
- sum():列中值的和
所有聚合函数都忽略空值null,仅对非空数值进行计算。
其中count()可以对所有字段进行计数。
维度和度量
维度:用来分组的分类字段,包括无序分类字段(姓名、性别、血型等字段)和有序分类字段(学历、职称、舱位等字段);
度量:用来聚合运算的数值字段(年龄、数量、金额等字段);
分组查询
分组查询:select 字段1[,字段2] from 表名 [where 查询条件] group by 分组字段1[,分组字段2......];
将查询结果按照一个或者多个字段进行分组,字段值相同的为一组,对每个组进行聚合计算;
分组后筛选:select 字段1[,字段2] from 表名 [where 查询条件] group by 分组字段1[,分组字段2......] having 筛选条件;
where 子句与having子句的区别:
where子句作用于表,having子句作用于组;
where条件查询的作用域是针对数据表进行筛选,而having条件查询则是对分组结果进行过滤;
where在分组和聚合计算之前筛选行,而having在分组和聚合之后筛选分组的行,因此where子句不能包含聚合函数;
select语句书写的顺序
| 子句顺序 | 说明 | 是否必须使用 |
| SELECT | 要返回的列或者表达式 | 是 |
| FROM | 从中检索数据的表或视图 | 仅从中检索数据时使用 |
| WHERE | 行级过滤 | 仅对记录进行筛选时使用 |
| GROUP BY | 分组字段 | 仅在分组聚合运算时使用 |
| HAVING | 组级过滤 | 仅对分组进行筛选时使用 |
| ORDER BY | 输出排序 | 仅对查询结果进行排序时使用 |
| LIMIT | 限制输出 | 仅对查询结果限制输出时使用 |
分组后只能显示分组字段和聚合字段。
where子句必须跟在from子句后面,而且不能使用聚合函数作为条件。
-- 查询emp表中员工总数、最高工资、最低工资、平均工资及工资总和
select count(*) 员工总数,max(sal) 最高工资,min(sal) 最低工资,avg(sal) 平均工资,sum(sal) 工资总和 from emp;
-- 按照部门号查询emp表中员工总数、最高工资、最低工资、平均工资及工资总和
select deptno 部门号,count(*) 员工总数,max(sal) 最高工资,min(sal) 最低工资,avg(sal) 平均工资,sum(sal) 工资总和
from emp
group by deptno;
-- 查询各部门不同岗位的平均工资
select deptno 部门号,job 职位,avg(sal) 平均工资 from emp
group by deptno,job
order by deptno,avg(sal);
-- 分组后筛选: 查询各部门业务员的平均工资
select deptno 部门号,job 职位,avg(sal) 平均工资 from emp
group by deptno,job
having job = '业务员'
order by deptno,avg(sal);
select deptno 部门号,job 职位,avg(sal) 平均工资 from emp
where job = '业务员'
group by deptno,job
order by deptno,avg(sal);
-- 查询平均工资大于8000的部门
select deptno 部门号,avg(sal) 平均工资
from emp
group by deptno
having avg(sal) > 8000;
# mysql5.7以后版本可以在having子句后使用select定义的别名作为条件
select deptno 部门号,avg(sal) 平均工资
from emp
group by deptno
having 平均工资 > 8000;
以上是关于一周入门MySQL—2单表查询的主要内容,如果未能解决你的问题,请参考以下文章