一周入门MySQL—3多表查询子查询常用函数
Posted SAP剑客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一周入门MySQL—3多表查询子查询常用函数相关的知识,希望对你有一定的参考价值。
多表查询、子查询、常用函数
一、多表查询
多表查询:通过不同表中具有相同意义的关键字段,将多个表进行连接,查询不同表中的字段信息。
对应关系
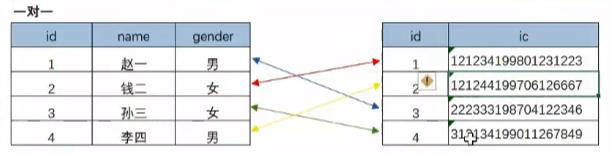
一对一:比如下图的人员信息表和人员身份证对应表,一个员工只会有一个身份证号码;
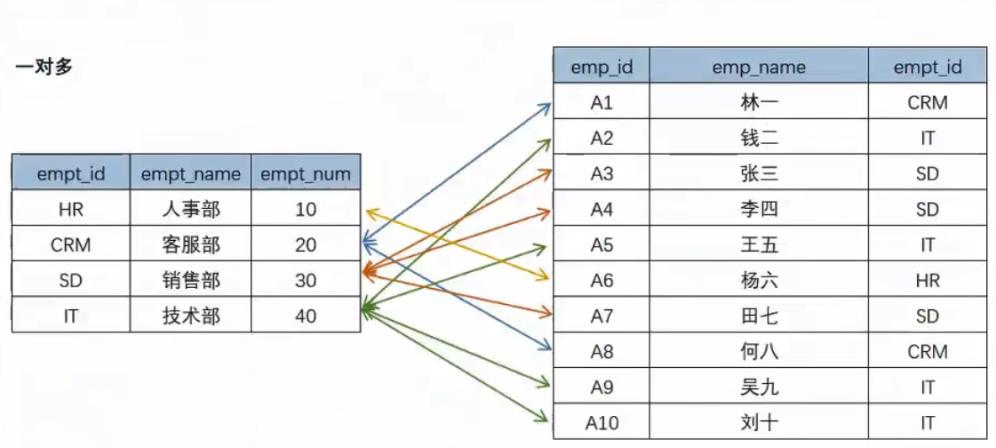
一对多:比如下图的部门信息表和部门人员表,一个部门可能会有多个员工存在;
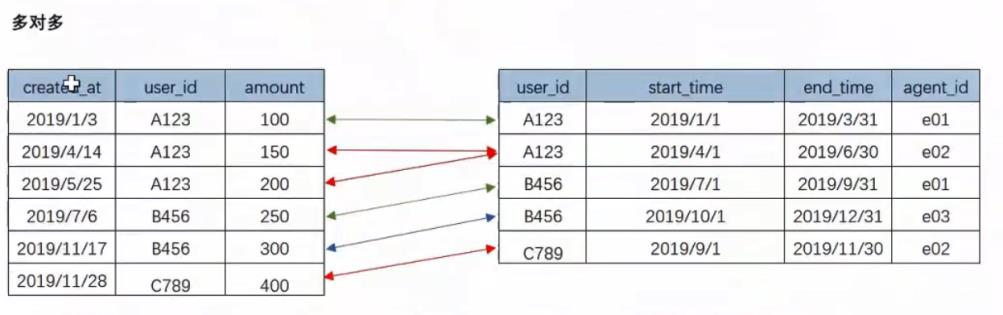
多对多:多对多的情况就比较复杂了,建议拆分表,这样可以节省存储空间,避免数据冗余;
连接方式
内连接和外连接(左外连接和右外连接)。
多表连接的结果通过三个属性决定
- 方向性:在外连接中写在前面的表为左表,写在后面的表为右表;
- 主附关系:主表要出所有的数据范围,附表与主表无匹配项时标记为null,内连接时无主附表之分;
- 对应关系:关键字段中有重复值的表为多表,没有重复值的表为一表;
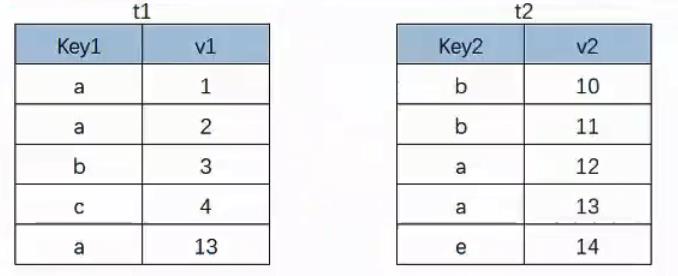
比如上图中的t1表和t2表:
若左外连接:t1是主表,t2是附表;
若右外连接:t2是主表,t1是附表;
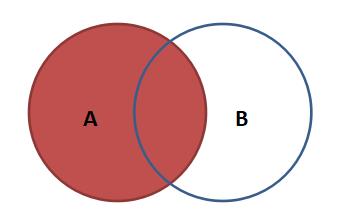
左连接:
结果中除了包括满足连接条件的行外,还包括左表的所有行。
select 字段1[,...] from表1 left join 表2 on 表1.key = 表2.key;
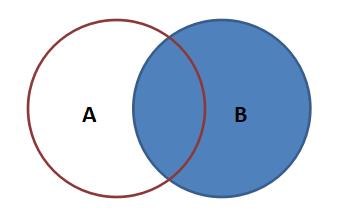
右连接:
结果中除了包括满足的连接条件的行外,还包括右边的所有行。
select 字段1[,...] from表1 right join 表2 on 表1.key = 表2.key;
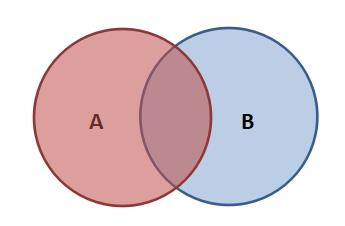
内连接:
按照连接条件合并两个表,返回满足条件的行。
没有主附关系,也没有方向性。
select 字段1[,...] from表1 [inner] join 表2 on 表1.key = 表2.key;
另外在其他工具中还有全连接、左反和右反连接(Power BI)。

-- 内连接
select * from t1 inner join t2 on t1.key1 = t2.key2;
-- 左连接
select * from t1 left join t2 on t1.key1 = t2.key2;
-- 右连接
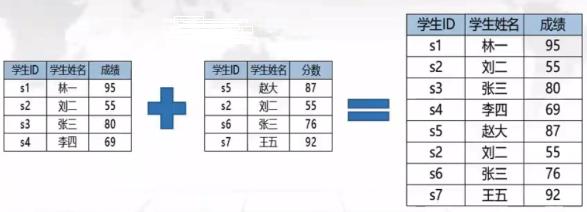
select * from t1 right join t2 on t1.key1 = t2.key2;纵向合并(联合查询):
把多条select语句查询的结果合并为一个结果集,即追加 / 增加记录。
指数据集的纵向合并,从数据集被合并到主数据集中。
注意 :
两张表必须拥有相同数量的字段;
两张表字段的顺序必须相同;
两张表独赢的字段的数据类型必须一致;
字段名可以不相同,选取主数据集中的字段名(第一个表)。
union 去重:select 字段1[,字段2,...] from 表名 union select 字段1[,字段2,...] from 表名;
union all不去重:select 字段1[,字段2,...] from 表名 union all select 字段1[,字段2,...] from 表名;
-- 合并查询
select * from t1
union all
select * from t2;
-- union去重
select * from t1
union
select * from t2;【测试题】
表a userid
表b userid
查询出现在a表,不在b表的userid。
思路:左反连接和右反连接
select *
from table_a
left join table_b
on table_a.userid = table_b.userid
where table_b.userid is null;order表:userid,endtime
求每个userid的最新结束时间
select userid,max(endtime)
from order
group by uderid;order表:userid,endtime
user表:userid,tel
找出用户结束时间在3月份的userid的tel
select order.userid, user.tel
from user right join order on user.userid = order.userid
where month(endtime) = 3;
select order.userid, user.tel
from user right join order on user.userid = order.userid
where endtime between ‘2021-03-01’ and ‘2021-03-31’;在一张表中查询出员工姓名和对应的领导姓名
-- 自连接:通过设置别名实现,将同一张表视为两张表
select t1.ename 员工姓名,t2.ename 领导姓名
from emp t1
left join emp t2 on t1.mgr = t2.empno;查询入职日期早于其直属领导的员工信息:empno、ename、dname(部门表)
select t1.empno 员工编号,t1.ename 员工姓名,t3.dname 部门名称
from emp t1
left join emp t2 on t1.mgr = t2.empno
inner join dept t3 on t1.deptno = t3.deptno
where t1.hiredate < t2.hiredate;二、子查询
子查询:在一个select语句中包含另一个或者多个完整的select语句。
子查询出现的位置
出现在where子句中:将子查询返回的结果作为主查询的条件;
出现在from子句中:将子查询返回的结果作为主查询的一个表;
子查询的分类
- 标量子查询:返回的结果是一个数据(单行单列);
- 行子查询:返回的结果是一行(单行多列);
- 列子查询:返回的结果是一列(多行单列);
- 表子查询:返回的结果是一张临时表(多行多列);
子查询的操作符:
- [NOT] IN:在【不在】其中
- ANY:其中任何一个
- ALL:全部(每个)
-- 子查询:标量子查询
-- 查询基本工资高于公司平均工资的员工信息(where子句中不能直接使用聚合函数)
select * from emp
where sal > (select avg(sal) from emp);
-- 查询与“张晓明”同一个领导的员工信息:empno、ename、job、mgr
select empno,ename,job,mgr
from emp
where mgr = (select mgr from emp where ename = '张晓明')
and ename <> '张晓明';-- 子查询:行子查询
-- 查询和“许飞龙”同部门同职位的员工信息:empno,ename,job,deptno
select empno,ename,job,deptno
from emp
where (deptno,job) = (select deptno,job from emp where ename = '许飞龙')
and ename <> '许飞龙';-- 子查询:列子查询
-- 查询普通员工的工资等级:empno,ename,sal,grade
select empno 员工号,ename 员工姓名,sal 基本工资,grade 工资等级
from emp
left join salgrade on sal between losal and hisal
where empno not in (select distinct mgr from emp where mgr is not null);
-- 查询员工数不少于3个人的部门所有员工信息:empno,ename,deptno
-- 思路:先查找出大于等于3人的部门编号
select empno,ename,deptno
from emp
where deptno in (select deptno from emp group by deptno having count(*) >= 3);
-- 查询基本工资高于51部门任意员工的员工信息
select *
from emp
where sal > any (select sal from emp where deptno = 51)
and deptno <> 51;
select *
from emp
where sal > (select min(sal) from emp where deptno = 51)
and deptno <> 51;
-- 查询基本工资高于51部门所有员工的员工信息
select *
from emp
where sal > all (select sal from emp where deptno = 51)
and deptno <> 51;-- 子查询:from子查询
-- 查询各个部门最高工资的员工:empno,ename,sal,deptno
-- 表子查询必须设置别名
select empno,ename,sal,emp.deptno
from emp
left join (select deptno,max(sal) as 最高工资 from emp group by deptno) as t
on emp.deptno = t.deptno
where sal = 最高工资;三、函数
-- 字符串函数
select concat('My','Name','Is','Jack'); #MyNameIsJack
select concat('My','Name','Is',null); #null
select instr('ABCDE','C'); #3
select left('ABCDE',4); #ABCD
select right('ABCDE',4); #BCDE
select mid('ABCDEFG', 3, 4); #CDEF
select mid('ABCDEFG', 3); #CDEFG
select substring('ABCDEFG', 3, 4); #CDEF
select substring('ABCDEFG', 3); #CDEFG
select ltrim(' ABC'); #ABC
select rtrim('ABC '); #ABC
select trim(' ABC '); #ABC
select replace('ABCdeF','de','DE'); #ABCDEF
select repeat('Shit',3); #ShitShitShit
select reverse('ABCDE'); #EDCBA
select upper('abcde'); #ABCDE
select lower('ABCDE'); #abcde
-- 将员工表中姓名首字母大写,其他字母小写显示
select concat(upper(left(ename,1)),lower(mid(ename,2))) from emp;数学函数
例如:
abs() 绝对值
floor() 向下取整 – 地板
ceiling() 向上取整 – 天花板
round() 四舍五入,第二个参数为保留小数位数
rand() 返回一个0-1之间的随机小数
select rand(1); 输入的随机种子一样,得到的结果一样。
日期时间函数
date() 返回指定日期时间表达式的日期或者将文本字符串格式日期转换成标准的日期格式
select date('20200101'); #2020-01-01
select date('2020-01-01 11:11:11'); #2020-01-01
select week('2022-01-01'); #0
select month('2020-01-01 11:11:11'); #1
select quarter('2020-12-01 11:11:11'); #4
select year('2020-12-01 11:11:11'); #2020
select year('20-12-01'); #2020
select date_add('2022-01-01',interval 1 day); #2022-01-02
select date_add('2022-01-01',interval 1 year); #2023-01-01
select adddate('2022-01-01',interval 1 month); #2022-02-01
select date_sub('2022-01-01',interval 1 day); #2021-12-31
select date_sub('2022-01-01',interval 1 year); #2021-01-01
select subdate('2022-01-01',interval 1 month); #2021-12-01
select date_format('2022-01-06 15:05:20','%Y-%m-%d'); #2022-01-06
select date_format('2022-01-06 15:05:20','%Y-%m'); #2022-01
select date_format('2022-01-06 15:05:20','%m'); #01
select curdate(); #无参函数,当前电脑系统日期
select curtime(); #无参函数,当前电脑系统时间
select now(); #无参函数,当前电脑系统日期时间
select datediff('20220106','20211228'); #9 日期间隔天数
-- 计算员工表中每个员工的工龄
use test;
select ename 姓名,hiredate 入职日期,round(datediff(curdate(),hiredate)/365) 工龄
from emp;
select unix_timestamp(); #当前日期从1970-01-01 00:00:00开始到现在过了多少秒
select unix_timestamp('2022-01-06'); #1641398400
select from_unixtime(1641473220); #2022-01-06 20:47:00
-- 查询每个员工的试用截止日期(试用期三个月):ename,hiredate,试用截止日期
select ename,hiredate,adddate(hiredate,interval 3 month) 试用截止日期
from emp;分组合并函数 group_concat()
对文本字符串进行合并,跟group by结合使用,返回一个字符串结果。
平时我们group by之后只能对数值型进行聚合,不能对字符串数据聚合。
忽略空置null
-- 查询每个部门有哪些员工
select deptno,group_concat(ename)
from emp
group by deptno;
-- 查询每个部门有哪些员工(去重)
select deptno,group_concat(distinct ename)
from emp
group by deptno;
-- 查询每个部门有哪些员工(排序)
select deptno,group_concat(distinct ename order by sal desc)
from emp
group by deptno;
-- 查询每个部门有哪些员工(指定分隔符/)
select deptno,group_concat(distinct ename order by sal desc separator '/')
from emp
group by deptno;逻辑函数
ifnull()
-- 计算每位员工的实发工资:基本工资 + 提成
-- 思路:没有提成的null 需要用0代替
select ename,sal,ifnull(comm,0)+sal 实发工资
from emp;if()
-- 判断每位员工的工资级别
select ename,sal,if(sal>=15000,'高',if(sal<=9000,'低','中')) 工资级别
from emp;case when end
-- 判断每位员工的工资级别
select ename,sal,case when sal>=15000 then'高'
when sal<=9000 then'低'
else '中'
end 工资级别
from emp;开窗函数
mysql 8.0才支持。
开窗函数是在满足某种条件的记录集合上执行的特殊函数。
静态窗口 滑动窗口
本质还是聚合运算,但是使用灵活,在每一个记录行上来执行并返回计算结果。
语法:
开窗函数名称([<字段名>]) over([partition by <分组字段>] [order by<排序字段>[desc]] [<细分窗口>])
对于滑动窗口的范围指定,通常使用between frame_start and frame_end语法来表示行范围,rame_start 和frame_end可以支持如下关键字,来确定不同的动态行记录:
- current row 边界是当前行,一般和其他范围关键字一起使用;
- unbounded preceding 边界是分区中的第一行;
- unbounded following 边界是分区中的最后一行;
- expr preceding 边界是当前行减去expr的值;
- expr following 边界是当前行加上expr的值;
比如,下面都是合法的范围:
rows between 1 preceding and 1 following 窗口范围是当前行、前一行、后一行一共三行记录;
rows unbounded preceding 窗口范围是当前行到分区的最后一行;
rows between unbounded preceding and unbounded following 窗口范围是当前分区中的所有行,等同于不写;
序号函数
- row_number():显示分区中不重复不间断的序号;
- dense_rank():显示分区中重复不间断的序号;
- rank():显示分区中重复间断的序号;
-- 开窗函数:聚合函数
-- 所有员工的平均工资
select avg(sal) avg_sal from emp; #得到一个值
select *,avg(sal) over() avg_sal from emp; #得到一列值(每个记录行)
-- 查询各个部门的平均工资
select deptno,avg(sal) avg_sal from emp group by deptno;
select *,avg(sal) over(partition by deptno) avg_sal from emp; #同一个部门的数据会分到一个区域
-- 各个部门按照入职日期计算累计工资
select *,sum(sal) over(partition by deptno order by hiredate asc) sum_sal from emp;
-- 按照入职日期计算各个部门当前行的前一行和后一行的平均工资
-- 例如:按照部门分组,按照入职日期升序排列,扫描第一条记录,计算其前一行+当前行+后一行的平均工资
select *,avg(sal) over(partition by deptno order by hiredate rows between 1 preceding and 1 following) avg_sal from emp;
-- 开窗函数:序号函数
-- 所有员工按照入职日期显示排名
select *,row_number() over(order by hiredate) as '排名' from emp; #在一个区内按照入职日期进行排序
-- 各个部门员工按照基本工资显示排名
select *,row_number() over(partition by deptno order by sal desc) as 'row_number排名' from emp;
select *,dense_rank() over(partition by deptno order by sal desc) as 'dense_rank排名' from emp;
select *,rank() over(partition by deptno order by sal desc) as 'rank排名' from emp;【练习题】
计算2017年每笔投资均大于50万元的用户
select user_id
from cmn_investment_request
where year(created_at)=2017
group by user_id
having min(invest_amount)>500000;计算2017年仅投资过CFH和AX产品的用户
select user_id,group_concat(distinct invest_item order by invest_item desc)
from cmn_investment_request
where year(created_at)=2017
group by user_id
having group_concat(distinct invest_item order by invest_item desc)=’CFH,AX’;计算归属于10002业务员的投资金额
select sum(invest_amount)
from dim_agent
left join cmn_investment_request
on cmn_investment_request.user_id=dim_agent.user_id
and created_at between start_date and end_date
where agent_id=’10002’;
以上是关于一周入门MySQL—3多表查询子查询常用函数的主要内容,如果未能解决你的问题,请参考以下文章