left join关联查询一对多数据重复问题解决方案
Posted 爱叨叨的程序狗
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了left join关联查询一对多数据重复问题解决方案相关的知识,希望对你有一定的参考价值。
写在前面:
使用准则:
在使用左右连接时,一定要保障主表与关联表的on条件是1:1的关系,以保障正常查询主表数据。
实例
# 车主表
create table owner
(
id int(10) auto_increment
primary key,
owner_name varchar(10) null,
brand_id int(10) null
);
# 车辆表
create table vehicle
(
id int(10) auto_increment
primary key,
brand_id int(10) null
);
# 车辆品牌表
create table brand
(
id int(10) auto_increment
primary key,
brand_name varchar(10) null
);
INSERT INTO `halodb`.`owner` (`id`, `owner_name`, `brand_id`) VALUES (1, 'debug', 1);
INSERT INTO `halodb`.`owner` (`id`, `owner_name`, `brand_id`) VALUES (2, 'Ltx', 2);
INSERT INTO `halodb`.`owner` (`id`, `owner_name`, `brand_id`) VALUES (3, 'Ltx', 1);
INSERT INTO `halodb`.`brand` (`id`, `brand_name`) VALUES (1, '比亚迪');
INSERT INTO `halodb`.`brand` (`id`, `brand_name`) VALUES (2, '大众');
INSERT INTO `halodb`.`vehicle` (`id`, `brand_id`) VALUES (1, 1);
INSERT INTO `halodb`.`vehicle` (`id`, `brand_id`) VALUES (2, 2);
INSERT INTO `halodb`.`vehicle` (`id`, `brand_id`) VALUES (3, 1);



需求1:展示列表车辆品牌信息、车主信息。
根据当前的表结构,那么很自然的我们可以使用brand表关联owner表。
select b.brand_id, b.brand_name, o.owner_name
from brand b
left join owner o on b.id = o.brand_id;
执行结果长这样:

需求2:展示列表车辆信息、车辆品牌信息、车主信息。
以车辆为主表,分别关联车辆品牌表和车主表
select v.id as vehicleId, b.id as brandId, b.brand_name as brandName, o.owner_name as ownerName
from vehicle v
left join brand b on v.brand_id = b.id
left join owner o on b.id = o.brand_id;
执行结果长这样:

可问题来了,主表brand只有两条数据,但是查出来了三条数据,vehicle表有三条数据,却查出来五条,并不能正确展示主表数据。
分析SQL
Q1:如果规定没人只有辆车的话,该SQL并没有问题,可实际业务中可能会出现一个人拥有多辆车的情况,也就是车牌与车主的关系是1:n,那么我们使用品牌id去关联车主表的brand_id则违反了我写在最前面的使用准则。
Q2:一辆车只有一个品牌,vehicle表与brand表是1:1关系,那么没有问题,但是使用车辆品牌表去关联车主表时,车辆品牌与车主是n:1的关系,当使用左右连接时,会显示主表全部数据和符合条件的关联表数据,所以第二条关联数据会导致主表数据重复。
解决方案
- 根据实际业务场景,可以更换关联条件
- 分别查询数据,在Java中循环补充另一个SQL中查询的字段,即分别使用vehicle表关联brand表,再使用vehicle关联owner表
举例中表设计并不允许这样做,方案仅提供思路。
分两次查询的数据是两个List,两层for循环赋值时间复杂度高,那么可以将其中一个List根据vehicleId转换成Map,循环第一个List,在循环中使用list中的vehicleId做key去getMap的value.
由于Map本身的数据结构,会导致占用内存比List大,那么这种方案就是用空间去换时间,若数据量比较大,需权衡时间复杂度与空间复杂度。
怪味道的方案
使用group by对重复数据进行过滤
select v.id as vehicleId,
b.id as brandId, b.brand_name as brandName,
o.owner_name as ownerName
from vehicle v
left join brand b on v.brand_id = b.id
left join owner o on b.id = o.brand_id
group by vehicleId;
❌这样显然是不对的。
报错: this is incompatible with sql_mode=only_full_group_by
原因就是在mysql 5.7.5以上版本后,要求group by 的字段需要查询的字段与group by的字段满足唯一性。也就是vehicleId有多个,MySQL不知道用哪个。所以在写SQL时保持一个习惯:唯一性的数据需要写在首位。
SQL 标准中不允许 SELECT 列表,HAVING 条件语句,或 ORDER BY 语句中出现 GROUP BY 中未列表的可聚合列。
建议
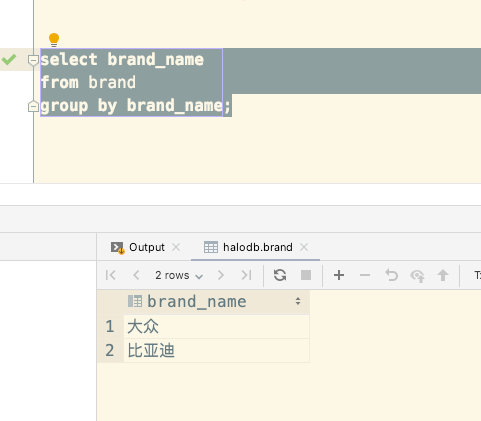
在使用group by时也需要注意,group by的该列一定是唯一的,如果group列出现数据重复数据时,仅会显示一条数据。
为测试该问题,在数据库新增一条重复数据

select brand_name from brand group by brand_name;
执行结果长这样:
以上是关于left join关联查询一对多数据重复问题解决方案的主要内容,如果未能解决你的问题,请参考以下文章