数字图像处理课程设计基于非深度学习方法实现身份证定位与正反面识别
Posted helton_yann
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数字图像处理课程设计基于非深度学习方法实现身份证定位与正反面识别相关的知识,希望对你有一定的参考价值。
文章目录
基于透视矫正与区域特征匹配的身份证图像定位与正反面识别
摘要
本次课程设计基于Python 开源计算机视觉库OpenCV实现了一种通用的基于非深度学习的身份证定位与正反面识别算法pipeline,算法主要通过传统线检测技术定位身份证的四个角点,并基于四个角点进行透视矩阵变换,用于矫正由于拍摄角度导致的图像透视现象。紧接着,利用裁剪的矫正后的身份证区域与标准身份证模板进行特征检测与匹配,最终实现身份证检测与正反面识别二分类。本次设计提出的pipeline具有较强的可解释性,能够一定程度的适应拍照模糊以及高光反射。算法可以实现基于静态图像的检测与基于视频流的检测两种方向,具有较好的实时性能。
效果展示:

实现细节
1.总体流程

2.前景背景分割

3.身份证角点定位

4.透视变换

5.模板匹配
5.1 基于区域颜色匹配的国徽检测
国徽分割:

国徽区域匹配:

5.2 基于区域字符数统计的身份ID检测
流程:

利用间隔数间接统计ID数:

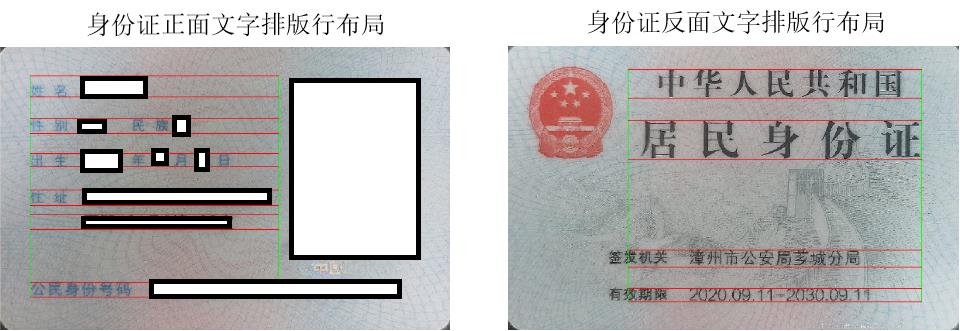
5.3 基于排版布局匹配的身份证正反面识别
事实上,上述的模板匹配算法都具有一定的局部局限性,由于匹配的区域较小,受到局部噪声干扰的影响也较大,其中一个致命的影响因素就是拍照时的局部反光,下图展示了一些基于局部反光的匹配失误的例子

因此,有必要扩大匹配的模板区域,以更为全局的视角进行特征的筛选。我们可以参照人类的视觉感知机制:人类在执行视觉识别任务时不仅会用到局部注意力,当局部注意力失效时,也会借助全局的信息辅助识别。当将身份证上的国徽以及人像信息抹去时,事实证明,我们还是能够根据保留的信息准确的判断出所属于身份证的哪一面。这是因为两者之间文字的排版有很大的差异,通过全局的排版特征进行模板匹配时,就能够有效的缓解局部噪声的影响。
通过标准的模板,我们可以得到身份证上文字排版的先验信息:
正面模板匹配率:
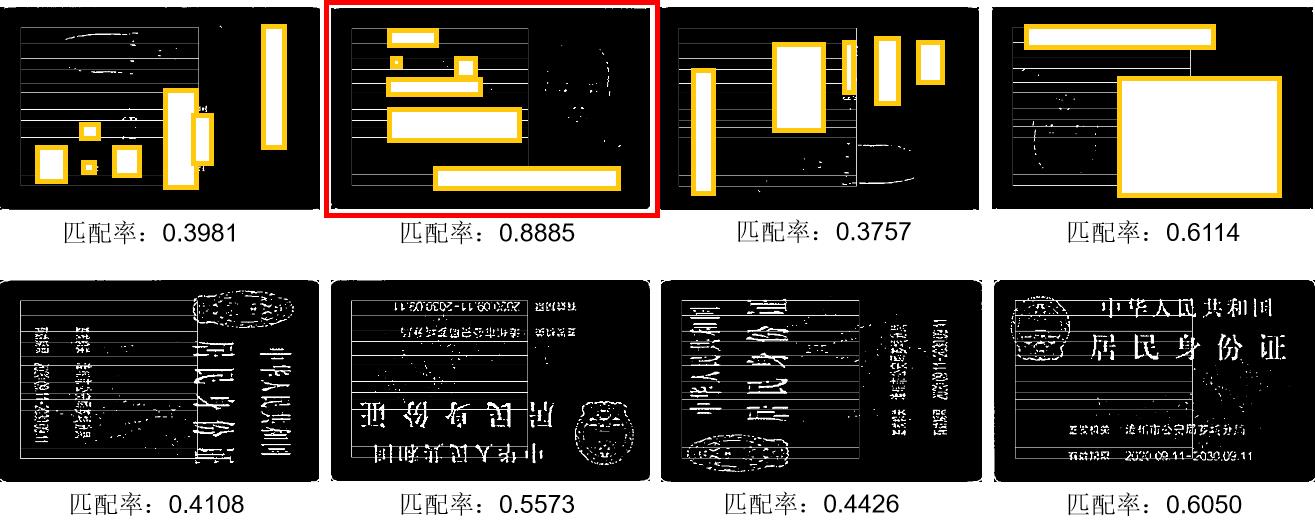
反面模板匹配率:

对于拍照中出现的局部反光,算法也能很好的适应:
正面反光:

背面反光:

基于以上多种模板匹配算法,不能说任何一个算法是完全有效且完美的,但是如果将多种匹配算法结合起来对最终的分类做决策。这种基于简单集成学习的思想最终却能够更有效的辅助算法实现更为鲁棒的分类。
因此,在算法设计过程中,可以将上述的多种算法结合起来,各自贡献一定的权重,用于联合辅助算法最终的决策。不过其中的代价就是增加了算法的复杂度。
6.算法优化(基于视频流检测)
6.1 面向识别算法的优化
一个普遍的认知是,相较于静态的图像而言,视频流的图像质量往往较低,从而导致在识别的过程中容易出现识别抖动的现象(识别结果在多个类别之间反复跳动)。以此同时,基于视频流的检测与基于静态图像的检测之间最大的差别就在于,视频流当前帧的检测可以充分参考先前帧的先验信息。
基于这个思路,同时通过观察不难发现,识别的结果发生改变当且仅当原来的身份证离开了相机视野或者原来的身份证没有离开相机视野但是翻了一个面(建立在识别区域每次仅有一个目标的前提下)。这两种操作对于算法而言都有一个共同的性质:即此时算法检测出的角点数为0。对于身份证离开了相机视野这点很容易解释。对于身份证翻面而言,在翻面的过程中,身份证一定会在某一时刻,与相机保持垂直,此时的身份证对于相机而言就是一条线。由于在计算交点的过程中,我们已经限定了平行线或一条边缘上的线不参与计算交点,因此,翻面的操作也会短暂的产生无法检测出角点的情况。
在出现上述现象与上一次出现该现象的时间间隔里,我们可以保证,目标的类别比然不会发生改变(同样建立在识别区域每次仅有一个目标的前提下)
若将上面总结出的现象(暂时称作“0角点现象”)作为算法的先验知识,我们就可以设计启发式的方法,来进行算法的优化。
缓解视频流识别过程中的抖动现象
我们可以在算法初始化时设置一个计数器,用于统计每个类别出现的次数,当没有出现0角点现象时,算法总是提取计数器中出现次数最多的那个类别作为最终算法预测的类别(此时每一帧仍然需要进行识别)。当发生0角点现象时,则重置计数器。通过多次的实验表明,该启发式方法能够很有效的缓解视频流识别过程中的抖动现象,提升识别的准确率
优化识别速率与准确率:
同样基于0角点现象的规律,当发生0角点现象后的一小段时间里(可以设定一个阈值,比如30帧),我们可以根据计数器统计算法预测结果最多的那个类别。当时间的间隔大于设定的阈值之后,算法就可以大胆的不再进行目标的识别,每次的识别结果均来自于前30帧里出现次数最多的类别,一直到下一次0角点现象发生的那一刻。此时重置计数器,并重新开始计算流过的视频帧数。通过多次的实验表明,该启发式方法不仅能够有效的缓解视频流识别过程中的抖动现象,提升识别的准确率,也能够提升算法的实时识别速率。
6.2 面向透视矫正算法的优化
减少算法的匹配复杂度
在对视频流的检测中,影响算法效率的因素除了每次都要进行目标的识别以外,另一个更致命的因素是透视变换后会得到四个基于不同旋转角的矫正图像。对于一张图像而言,识别算法会进行两次模板匹配(一正一反),对于四张图像就是匹配八次,因此优化的要求就期望减少矫正后需要匹配的图像数,最好是矫正之后就能够得到正确旋转角的目标图像。
一个可以利用的先验信息便是先前帧已检测出的角点坐标以及旋转角度。在OpenCV内置的透视变换求解函数中,输入的角点与匹配点需要严格按照左上,左下,右下,右上这一逆时针方向的顺序。根据视频流相邻两帧之间物体的移动角度不会太大这一特点,我们可以设置一个数组专门用于保存上一帧的角点坐标以及顺序信息,在进行当前帧的矫正时,算法无需遍历四种旋转角,只需要将当前帧检测出的角点与上一帧的角点进行两两匹配(采用欧式距离度量),根据距离最近的点就是上一帧移动到当前帧的角点这一前提假设,我们就可以忽略遍历四种顺序而直接进行透视变换。大大减少了算法的计算复杂度,
缓解视频流变换的抖动现象:
同识别问题类似,在进行透视矫正的过程中,算法也会出现抖动现象,根本的原因还是模板的匹配出现了错误。因此基于先验角点位置信息的启发式方法也能够一定程度的提升算法的识别率(从原始的四张图片中进行识别到只需一张图片进行识别)。
不过值得注意的是,该启发式方法在某些情况下同样需要重置,除了前面提到的0角点现象,还有一个是当目标的部分角点被遮挡时。这是因为,出现这些现象的时间间隔里,算法无法对身份证进行定位,而当算法重定位时,当前的角点坐标很有可能已经和现象发生之前的角点坐标产生了较大的偏差。因此通用的做法是,只要当检测到的角点个数小于4, 就需要重置保存上一帧的角点坐标以及顺序信息的数组,此时就需要重新匹配四个旋转角的图像。
Github链接自取
项目代码已上传Github:https://github.com/Scienthusiasts/IDcard_back_front_sides_identification,需要自取,若对您有帮助,别忘了点个⭐star😆 若有任何疑问请私信或在评论区留言。
以上是关于数字图像处理课程设计基于非深度学习方法实现身份证定位与正反面识别的主要内容,如果未能解决你的问题,请参考以下文章