为什么要使用3×3卷积?& 1*1卷积的作用是什么?& 对ResNet结构的一些理解
Posted 甘霖佳佳
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了为什么要使用3×3卷积?& 1*1卷积的作用是什么?& 对ResNet结构的一些理解相关的知识,希望对你有一定的参考价值。
为什么要使用3×3卷积?
常见的卷积核大小有1×1、3×3、5×5、7×7,有时也会看到11×11,若在卷积层提取特征,我们通常选用3×3大小的卷积。
我们知道,两个3×3卷积核一个5×5卷积的感受野相同,三个3×3卷积和一个7×7卷积的感受野相同(通俗来讲,感受野就是可以提取到周围邻居个数的特征)
假设输入输出channel均为C,使用7×7卷积核所需参数为
7
×
7
×
C
×
C
=
49
C
2
7×7×C×C = 49C^2
7×7×C×C=49C2 使用3×3卷积核所需参数为
3
×
3
×
C
×
C
+
3
×
3
×
C
×
C
+
3
×
3
×
C
×
C
=
27
C
2
3×3×C×C + 3×3×C×C + 3×3×C×C = 27C^2
3×3×C×C+3×3×C×C+3×3×C×C=27C2
可见在感受野相同的情况下,三个3×3卷积比一个7×7卷积所需参数要少很多,这无疑减少了模型的复杂度,加快了训练速度。
而且虽然感受野一样,但是3×3卷积的非线性程度更高,可以表示更复杂的函数;小的卷积核可以提取细小的特征,由小而大到比较抽象的特征。
但层数加深了,会产生有一串连锁效应,可能会效果提升,但也有可能变差,例如梯度消失。
ResNet 网络结构
ResNet结构如图所示
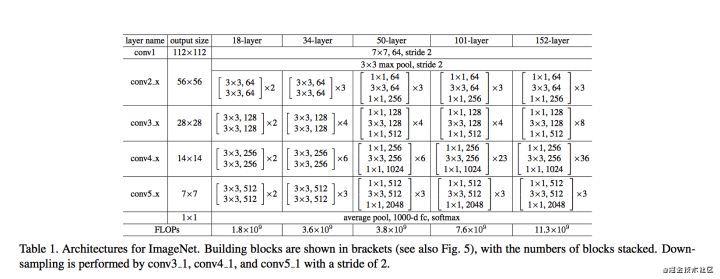
可见,在输入阶段使用了7x7卷积,作用实际上是用来直接对输入图片降采样(early downsampling),那为什么不使用3个3×3卷积呢?
原因:
在进入ResidualBlock训练之前尽可能保留原图更多的信息。
注意像7x7这样的大卷积核一般只可能出现在input layer层,这种情况下通常图像的分辨率很高,图像的像素值的方差较小。
具体问题具体分析,也有实验表面在此使用三个3×3卷积比一个7×7卷积效果好。
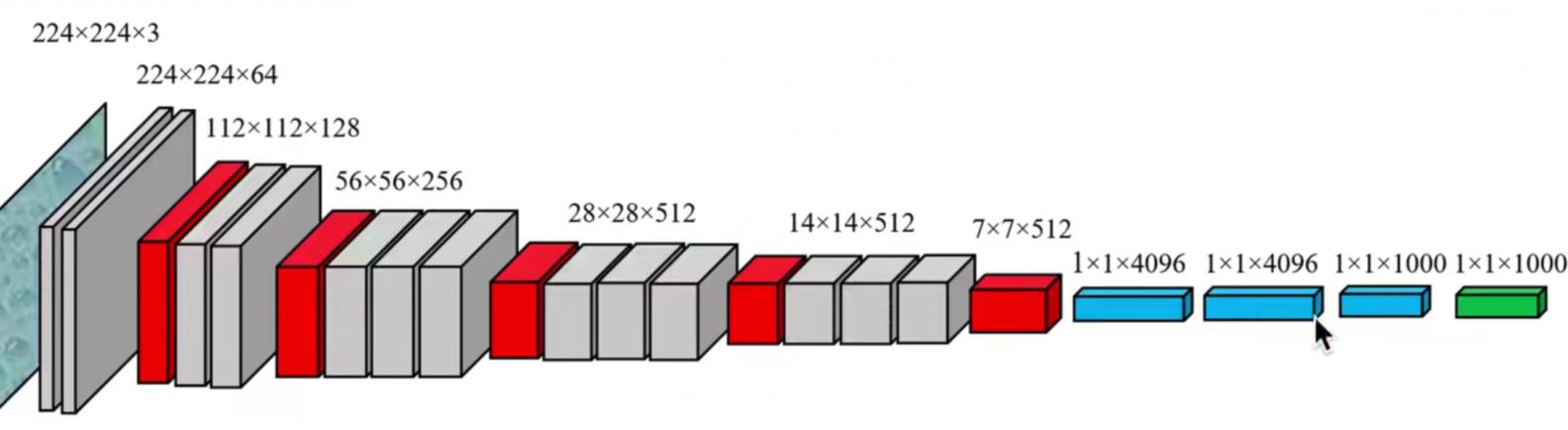
为什么卷积通道数逐层增加,而不是逐层减少
vgg网络的设计也是如此。
我们对神经网络的认识是:把像素空间的信息转化为语义信息。
卷积核和池化使得图像长宽方向的信息逐渐减小,而卷积通道数逐层增加通道信息逐渐增加,这符合我们的认知。
下图vgg结构可以更好的帮助我们理解
ResidualBlock
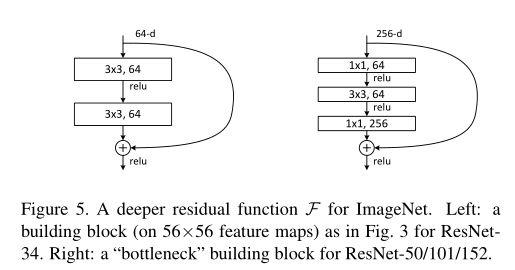
左边就是一个典型的ResidualBlock,通过两个3×3的空间卷积,输入通道数等于输出通道数,相加即可,不需要做处理。
在右边我们看到了1×1卷积,它的作用是什么呢?
右图的ResidualBlock代表我们先对数据降维一次(通道数从256降维到64)、再对其进行空间卷积(3×3卷积核,通道数不变),再投影回256通道数,使得输入和输出维度匹配以便相加。
那为什么不直接使用一个3×3通道数为256的卷积?
为什么使用1×1卷积来降维
如果不适用1×1卷积,直接使用一个3×3通道数为256的卷积,改成的参数量为
3
×
3
×
256
×
256
=
589824
3×3×256×256 = 589824
3×3×256×256=589824 而使用1×1卷积降维后构建ResidualBlock有
1
×
1
×
64
×
256
+
3
×
3
×
64
×
64
+
1
×
1
×
64
×
256
=
69632
1×1×64×256+3×3×64×64+1×1×64×256 = 69632
1×1×64×256+3×3×64×64+1×1×64×256=69632
由此可见,如果不增加1×1的卷积来降维,后续3×3卷积核所需的参数量会急剧增加。
1*1卷积的应用
残差连接如何处理输入、输出维度不同的情况?
①在输入、输出上添加额外的0,使得两个形状对应起来然后相加。(即以0填充扩展的维度,这种方法不需要添加额外的参数,但通常有些蛮力,效果不佳)
②在上述情况下可以使用1*1卷积来匹配维度。
以上是关于为什么要使用3×3卷积?& 1*1卷积的作用是什么?& 对ResNet结构的一些理解的主要内容,如果未能解决你的问题,请参考以下文章