CrawlSpider实现微信小程序社区爬虫python爬虫入门进阶(18)
Posted 码农飞哥
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CrawlSpider实现微信小程序社区爬虫python爬虫入门进阶(18)相关的知识,希望对你有一定的参考价值。
您好,我是码农飞哥,感谢您阅读本文,欢迎一键三连哦。
😁 1. 社区逛一逛,周周有福利,周周有惊喜。码农飞哥社区,飞跃计划
💪🏻 2. Python基础专栏,基础知识一网打尽,9.9元买不了吃亏,买不了上当。 Python从入门到精通
❤️ 3. Python爬虫专栏,系统性的学习爬虫的知识点。9.9元买不了吃亏,买不了上当,持续更新中 。python爬虫入门进阶
❤️ 4. Ceph实战,从原理到实战应有尽有。 Ceph实战
❤️ 5. Java高并发编程入门,打卡学习Java高并发。 Java高并发编程入门
关注下方公众号,众多福利免费嫖;加我VX进群学习,学习的路上不孤单

文章目录
前言
前面两篇文章我们初步了解了Scrapy框架,并使用Scrapy框架实现了糗事百科的爬虫。
Scrapy框架快速入门,以糗事百科为例进行说明【python爬虫入门进阶】(16)
Scrapy框架快速爬取糗事百科之数据存储及爬取多个页面【python爬虫入门进阶】(17)
这篇文章,主要介绍一种特殊的爬虫CrawlSpider,相比普通的Spider使用起来更加方便便捷。
CrawlSpider介绍
在上一个糗事百科的爬虫中,我们是自己在解析完整个页面后获取下一页的url,然后重新发起一个请求。有时候我们想这样做,只需要满足某种条件的url,都给我爬取下来。这时候就可以使用到CrawlSpider了。CrawlSpider类继承自Spider类,不过在此基础上增加了一些功能,可以定义爬取url的规则,以后Scrapy碰到满足此规则的url都会自动爬取。
创建CrawlSpider
首先,还是先通过命令 scrapy startproject wxapp 创建一个名为wxapp的Scrapy项目。接着就是跳转到wxapp目录下,通过命令:
scrapy genspider -c crawl [爬虫名字] [域名]
例如:
scrapy genspider -c crawl wxapp_spider ”wxapp-union.com“
定义完成之后可以看到WxappSpiderSpider类的代码如下:
class WxappSpiderSpider(CrawlSpider):
name = 'wxapp_spider'
allowed_domains = ['wxapp-union.com']
start_urls = ['http://wxapp-union.com/']
rules = (
Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True),
)
def parse_item(self, response):
item =
#item['domain_id'] = response.xpath('//input[@id="sid"]/@value').get()
#item['name'] = response.xpath('//div[@id="name"]').get()
#item['description'] = response.xpath('//div[@id="description"]').get()
return item
这里主要注意的是
rules = (
Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True),
)
这个代码,根据Rule中的LinkExtractor来提取相应的url。
其中: allow参数用于用正则表达式匹配我们想要的url。
callback 参数传入回调方法,如果这个url对应的页面,只是为了获取更多的url,并不需要里面的数据,那么可以不用指定callback。如果想要获取url对应的页面的数据,那么久需要指定一个callback。
follow参数,如果在爬取页面的时候,需要将满足当前条件的url再进行跟进,就需要设置为True,否则设置为False。
定义LinkExtractor
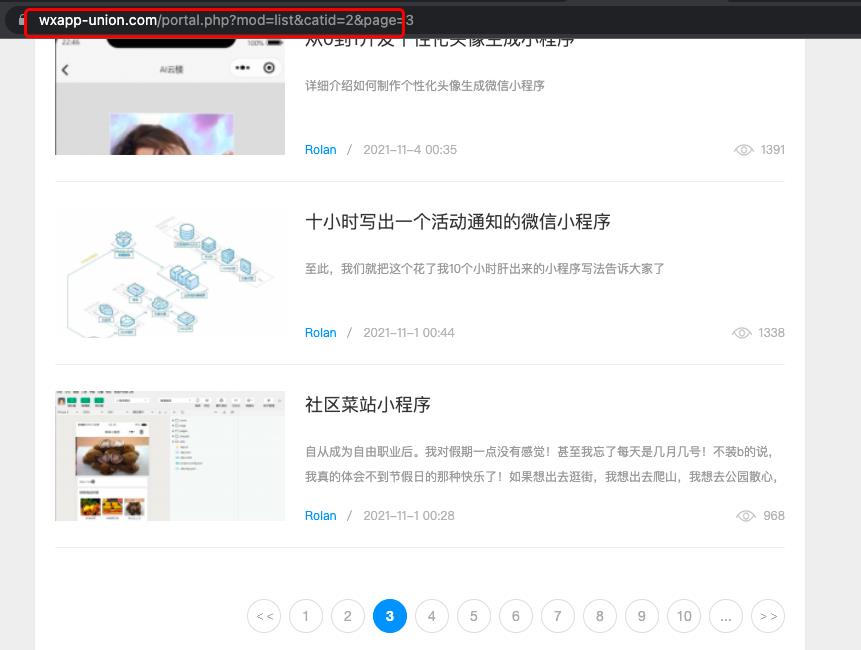
分析页面的url,
第一页的url是:https://www.wxapp-union.com/portal.php?mod=list&catid=2&page=1
第二页的url是:https://www.wxapp-union.com/portal.php?mod=list&catid=2&page=2
第三页的url是:https://www.wxapp-union.com/portal.php?mod=list&catid=2&page=3
故我们可以得出每个页面的url 唯一的区别就是 page的值不同。
allowed_domains = ['wxapp-union.com']
start_urls = ['https://www.wxapp-union.com/portal.php?mod=list&catid=2&page=1']
rules = (
# 列表页
Rule(LinkExtractor(allow=r'.+mod=list&catid=2&page=\\d'), callback='parse_item', follow=True),
Rule(LinkExtractor(allow=r'.+article-.+\\.html'), callback='parse_detail', follow=False)
)
所以:
- 列表页的LinkExtractor的allow值是
.+mod=list&catid=2&page=\\d,因为我们已经在allowed_domains中限制了域名。所以地址中只需要包含mod=list&catid=2&page=我们就认为是列表页。详细的正则表达式可以参考本文:学好正则表达式,啥难匹配的内容都给我匹配上【python爬虫入门进阶】(07)。
当然,也可以写成这样:https://www.wxapp-union.com/portal.php?mod=list&catid=2&page=\\d。其中\\d 表示匹配任意的数字。
follow设置为True是因为匹配到满足条件的列表页地址之后需要继续跟进,如果设置为False的话则只会爬取第一页。 - 详情页的LinkExtractor设置也是同理,这里follow是为了防止爬取到本页面中其他的详情页了。这里自定义了一个parse_detail方法,用于爬取详情页的数据。标题,作者,发布时间,文章内容都是在详情页中爬取的。
WxappSpiderSpider
class WxappSpiderSpider(CrawlSpider):
name = 'wxapp_spider'
allowed_domains = ['wxapp-union.com']
start_urls = ['https://www.wxapp-union.com/portal.php?mod=list&catid=2&page=1']
rules = (
# 列表页
Rule(LinkExtractor(allow=r'.+mod=list&catid=2&page=\\d'), callback='parse_item', follow=False),
Rule(LinkExtractor(allow=r'.+article-.+\\.html'), callback='parse_detail', follow=False)
)
def parse_item(self, response):
item =
return item
def parse_detail(self, response):
title = response.xpath('//h1[@class="ph"]/text()').get()
author = response.xpath('//p[@class="authors"]/a/text()').get()
publish_time = response.xpath('//p[@class="authors"]/span/text()').get()
article_content = response.xpath('//td[@id="article_content"]').getall()
content = "".join(article_content).strip()
wxappItem = WxappItem(title=title, author=author, publish_time=publish_time, content=content)
yield wxappItem
这里parse_item必须要返回item,不然的话如果有其他的Spider的则使用不到item。
WxappItem的设置
同样的还是在WxappItem中定义相关的标题,作者,发布时间等属性。
import scrapy
class WxappItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
author = scrapy.Field()
publish_time = scrapy.Field()
content = scrapy.Field()
settings的设置
这里settings.py中DEFAULT_REQUEST_HEADERS一定要设置请求头以及将ROBOTSTXT_OBEY设置为Flase。ROBOTSTXT_OBEY这用于检查是否有robots.txt ,如果设置为True的话,当Scrapy在爬虫之前没有找到robots.txt 文件的话,则爬虫会直接结束。
DEFAULT_REQUEST_HEADERS如果不设置的话,则可能会报403的错误。
#settings
BOT_NAME = 'wxapp'
SPIDER_MODULES = ['wxapp.spiders']
NEWSPIDER_MODULE = 'wxapp.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
# USER_AGENT = 'wxapp (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
# CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
DOWNLOAD_DELAY = 1
# The download delay setting will honor only one of:
# CONCURRENT_REQUESTS_PER_DOMAIN = 16
# CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
# COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
# TELNETCONSOLE_ENABLED = False
# Override the default request headers:
DEFAULT_REQUEST_HEADERS =
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36'
数据存储WxappPipeline
这里使用的是JsonLinesItemExporter类,操作比较简单,唯一需要注意的是设置编码encoding为utf-8,以及将ensure_ascii设置为False。
from scrapy.exporters import JsonLinesItemExporter
class WxappPipeline:
def __init__(self):
self.fp = open('wxapp.json', 'wb')
self.export = JsonLinesItemExporter(self.fp, encoding='utf-8', ensure_ascii=False)
def process_item(self, item, spider):
self.export.export_item(item)
return item
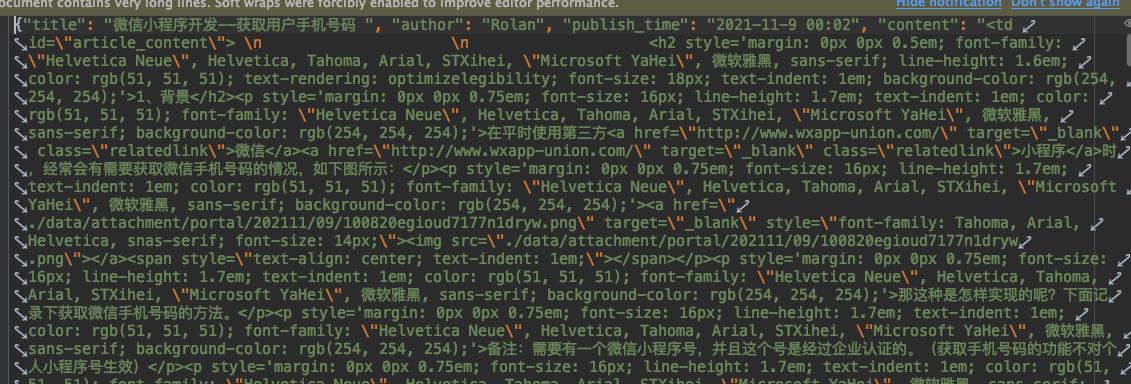
运行结果:
总结
本文详细介绍了CrawlSpider的使用,相对Spider而言,它主要简化了url的匹配。使用它之后我们只需要定义好匹配url的规则即可。
粉丝专属福利
软考资料:实用软考资料
面试题:5G 的Java高频面试题
学习资料:50G的各类学习资料
脱单秘籍:回复【脱单】
并发编程:回复【并发编程】
👇🏻 验证码 可通过搜索下方 公众号 获取👇🏻
以上是关于CrawlSpider实现微信小程序社区爬虫python爬虫入门进阶(18)的主要内容,如果未能解决你的问题,请参考以下文章