Elasticsearch:使用 Elasticsearch 在键入时实现类似 Linkedin 的搜索
Posted Elastic 中国社区官方博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch:使用 Elasticsearch 在键入时实现类似 Linkedin 的搜索相关的知识,希望对你有一定的参考价值。
原文:Implementing a Linkedin like search as you type with Elasticsearch
在大多数社交网络中搜索时,你的直接联系人的排名将高于其他用户。 让我们看一下 Linkedin 的搜索,看看我们是否可以用 Elasticsearch 复制类似的东西。在这里也告诉大家一个小秘密:Linkedin 上面的搜索也是使用 Elasticsearch 完成的哦!
请注意,这篇文章仅在你输入建议时处理自动完成/搜索,并且在发送搜索后不会深入搜索搜索结果,从而产生搜索结果页面。
让我们看看 Linkedin 的搜索界面:
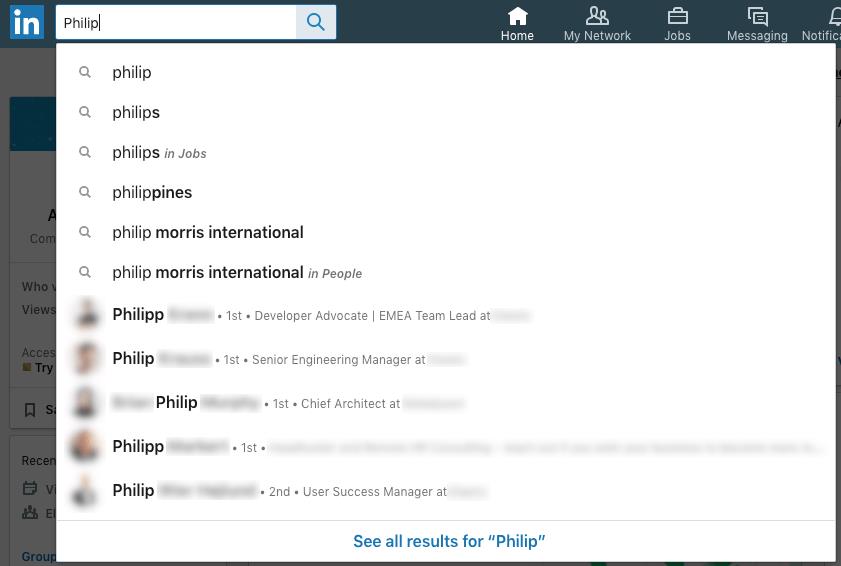
所以让我们看看这个搜索响应。 输入是 Philip。 我们将忽略任何非人的搜索结果或建议 - 前 6 条建议(非人)只是向你展示你可能还在搜索什么。
关注人员结果,列表中的最后五个。 前四个命中是在我的直接联系人中(也即是我的朋友或者同事)。 前两位也在 Elastic 工作。 第三个命中有 Philip 作为他的名字的一部分。 只有最后一个命中不是直接联系人 - 但也在我现在的雇主 Elastic 工作。
另一个需要注意的有趣的事情是,这显然是一个前缀(prefix)搜索,因为 Philipp 末尾有两个 p 也是一个有效匹配。
在收集需求之前,让我们尝试第二次搜索。
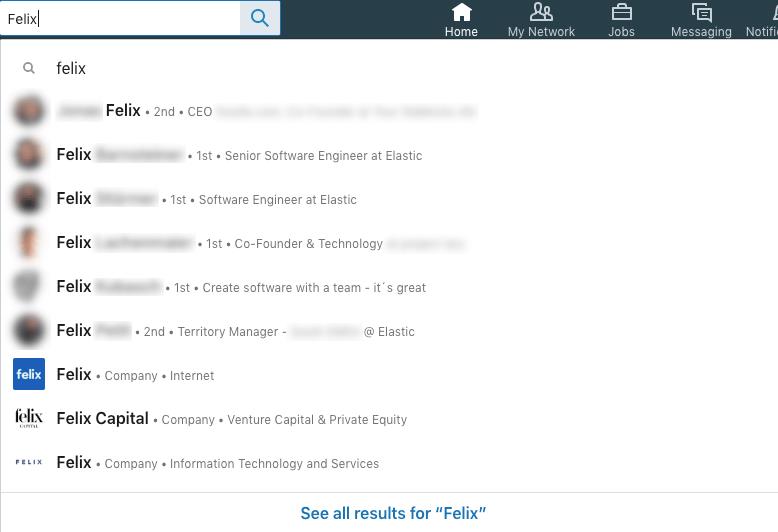
现在这很有趣,因为它与第一次搜索有很大不同。 我一点也不知道,为什么这不会在顶部给你任何非人的结果。 此外,似乎还有一些名为 Felix 的公司。 但是让我们看看人员搜索结果。
这次的第一个命中不是来自我的直接联系人,尽管我的直接联系人中有很多 Felix(这是复数,对吗?)。
显然,姓氏的完全匹配得分很高。
接下来是直接联系,首先是同事,然后是其他公司。 最后一个命中是 2 级命中,但也在 Elastic 工作。
计分规则
让我们尝试从两个结果中得出一些评分规则:
- 搜索的名字和姓氏(first name 及 last name 这是两个不同的字段)
- 姓氏精确匹配会使得排名靠前(还记得 TF/IDF 吗?与名字相比,Felix 很可能是一个罕见的姓氏,所以这可能是在没有调整的情况下发生的)。
- 前缀匹配是可以的(见 Philip vs. Philipp)
- 自己的联系人排名更高
- 你自己雇主的第二级联系人排名更高
Data Model
接下来,让我们提出一个数据模型。
一、全文检索所需字段:名(first name)、姓(last name)、全名(full name)。
二,排名除了搜索字段外还需要的字段:雇主(employer)、直接联系人(direct contacts)。
三、显示必填字段:职称(title)、雇主(employer)。
映射数据模型
现在我先不解释映射(mapping),因为稍后需要一些映射功能来改进查询,让我们暂时坚持下去。
PUT social-network
"mappings":
"properties":
"name":
"properties":
"first":
"type": "text",
"fields":
"search-as-you-type":
"type": "search_as_you_type"
,
"last":
"type": "text",
"fields":
"search-as-you-type":
"type": "search_as_you_type"
,
"full":
"type": "text",
"fields":
"search-as-you-type":
"type": "search_as_you_type"
,
"employer":
"type": "text"
,
"contacts":
"type": "keyword"
,
"title":
"type": "keyword"
在上面,我使用了 search_as_you_type 数据类型。如果你对这个还是不很熟悉的话,请参阅我之前的文章 “Elasticsearch:Search-as-you-type 字段类型”。
接下来,让我们创建一个索引 pipelien 来自动创建全名(full name):
PUT _ingest/pipeline/name-pipeline
"processors": [
"script":
"source": "ctx.name.full = ctx.name.first + ' ' + ctx.name.last"
]
再接下来,让我们索引一些人,一些直接联系人,一些同事和一些根本没有联系人的人:
PUT social-network/_bulk?pipeline=name-pipeline
"index":"_id":"alexr"
"name":"first":"Alexander","last":"Reelsen","employer":"Elastic","title":"Community Advocate","contacts":["philippk","philipk","philippl"]
"index":"_id":"philipk"
"name":"first":"Philip","last":"Kredible","employer":"Elastic","title":"Team Lead"
"index":"_id":"philippl"
"name":"first":"Philipp","last":"Laughable","employer":"FancyWorks","title":"Senior Software Engineer"
"index":"_id":"philippi"
"name":"first":"Philipp","last":"Incredible","employer":"21st Century Marketing","title":"CEO"
"index":"_id":"philippb"
"name":"first":"Philipp Jean","last":"Blatantly","employer":"Monsters Inc.","title":"CEO"
"index":"_id":"felixp"
"name":"first":"Felix","last":"Philipp","employer":"Felixia","title":"VP Engineering"
"index":"_id":"philippk"
"name":"first":"Philipp","last":"Krenn","employer":"Elastic","title":"Community Advocate"为简单起见,我只为自己添加了直接联系人列表,在实际应用程序中,每个用户都会有自己的联系人列表。
搜索用户
好的,最简单的搜索优先展示 :),任意搜索 Philipp,这次只在 first name 字段中。
GET social-network/_search
"query":
"match":
"name.first": "Philipp"
如果要减少结果字段,请将 filter_path=**.name.full,**._score 附加到 URL 以仅包含 full name 和 score。
GET social-network/_search?filter_path=**.name.full,**._score
"query":
"match":
"name.first": "Philipp"
你会看到,所有文档的评分都相同(因为大多数字段仅在名字中包含 Philipp,但最后评分的 Philipp Jean 除外)。
"hits" :
"hits" : [
"_score" : 0.6063718,
"_source" :
"name" :
"full" : "Philipp Laughable"
,
"_score" : 0.6063718,
"_source" :
"name" :
"full" : "Philipp Incredible"
,
"_score" : 0.6063718,
"_source" :
"name" :
"full" : "Philipp Krenn"
,
"_score" : 0.44027865,
"_source" :
"name" :
"full" : "Philipp Jean Blatantly"
]
没有具体的顺序,因为分数相同并且没有定义 tie breaker。最后一个文档的得分较低是因为 full name 和其它的文章相比较长一些。你可以参阅文章 TF/IDF。
给自己的联系人评分更高
好的,所以我的用户(first: Alexander)有一个联系人列表。 他们的影响力如何得分。 我们可以在 bool 查询中使用 should。 假设只有 Philipp Krenn 是我的同事。 我可以查看他的 id (philippk) 并像这样添加:
GET social-network/_search?filter_path=**.name.full,**._score
"query":
"bool":
"should": [
"term":
"_id":
"value": "philippk"
],
"must": [
"match":
"name.first": "Philipp"
]
响应如下所示:
"hits" :
"hits" : [
"_score" : 1.438688,
"_source" :
"name" :
"full" : "Philipp Krenn"
,
"_score" : 0.43868804,
"_source" :
"name" :
"full" : "Philipp Laughable"
,
...
]
在我看来不错! Philipp 现在得分更高。 但是在每次查询之前手动查找 id 太乏味了(想象一下为成千上万的联系人这样做)。 Elasticsearch 已经可以为我们做到这一点了! 有一个内置的术语查找(terms lookup)功能。 使用它,我们可以像这样自动查找我的用户的联系人列表。
GET social-network/_search?filter_path=**.name.full,**._score
"query":
"bool":
"should": [
"terms":
"_id":
"index": "social-network",
"id": "alexr",
"path": "contacts"
],
"must": [
"match":
"name.first": "Philipp"
]
响应如下所示:
"hits" :
"hits" : [
"_score" : 1.6063719,
"_source" :
"name" :
"full" : "Philipp Laughable"
,
"_score" : 1.6063719,
"_source" :
"name" :
"full" : "Philipp Krenn"
,
"_score" : 0.6063718,
"_source" :
"name" :
"full" : "Philipp Incredible"
,
"_score" : 0.44027865,
"_source" :
"name" :
"full" : "Philipp Jean Blatantly"
]
好吧,前两个命中是直接联系人中的,所以这对我来说听起来是一个很好的实现。 每当你添加新联系人时,请确保联系人数组已更新并且一切顺利。
然而,还有更多。
完全匹配的姓氏得分更高
我们看到姓氏匹配得更高。 让我们尝试一下,到目前为止,我们只搜索了名字,但也许我们可以使用 multi match 查询来搜索名字和姓氏。
GET social-network/_search?filter_path=**.name.full,**._score,**.employer
"query":
"bool":
"should": [
"terms":
"_id":
"index": "social-network",
"id": "alexr",
"path": "contacts"
],
"must": [
"multi_match":
"query": "Philipp",
"fields": [
"name.last",
"name.first"
]
]
让我们看看结果:
"hits" :
"hits" : [
"_score" : 1.6739764,
"_source" :
"name" :
"full" : "Felix Philipp"
,
"employer" : "Felixia"
,
"_score" : 1.6063719,
"_source" :
"name" :
"full" : "Philipp Laughable"
,
"employer" : "FancyWorks"
,
"_score" : 1.6063719,
"_source" :
"name" :
"full" : "Philipp Krenn"
,
"employer" : "Elastic"
,
"_score" : 0.6063718,
"_source" :
"name" :
"full" : "Philipp Incredible"
,
"employer" : "21st Century Marketing"
,
"_score" : 0.44027865,
"_source" :
"name" :
"full" : "Philipp Jean Blatantly"
,
"employer" : "Monsters Inc."
]
谢谢标准评分算法(best_fields)和我们非常小的数据集匹配 last name 得分最高。我们甚至可以使用加权的办法确保 last time 的得分较高:
GET social-network/_search?filter_path=**.name.full,**._score,**.employer
"query":
"bool":
"should": [
"terms":
"_id":
"index": "social-network",
"id": "alexr",
"path": "contacts"
],
"must": [
"multi_match":
"query": "Philipp",
"fields": [
"name.last^2",
"name.first"
]
]
在上面,我们使用 name.last^2 使得 last name 在计算分数时进行加权。
给同事打分更高
如果我们找到两个直接联系人,但一个用户为你的雇主(比如 Elastic)工作,那么如何给他们更高的评价? 幸运的是,我们可以添加一个 should 子句。
GET social-network/_search?filter_path=**.name.full,**._score,**.employer
"query":
"bool":
"should": [
"terms":
"_id":
"index": "social-network",
"id": "alexr",
"path": "contacts"
,
"match":
"employer": "Elastic"
],
"must": [
"multi_match":
"query": "Philipp",
"fields": [
"name.last",
"name.first"
]
]
结果是这些:
"hits" :
"hits" : [
"_score" : 2.5486999,
"_source" :
"name" :
"full" : "Philipp Krenn"
,
"employer" : "Elastic"
,
"_score" : 1.6739764,
"_source" :
"name" :
"full" : "Felix Philipp"
,
"employer" : "Felixia"
,
"_score" : 1.6063719,
"_source" :
"name" :
"full" : "Philipp Laughable"
,
"employer" : "FancyWorks"
,
"_score" : 0.6063718,
"_source" :
"name" :
"full" : "Philipp Incredible"
,
"employer" : "21st Century Marketing"
,
"_score" : 0.44027865,
"_source" :
"name" :
"full" : "Philipp Jean Blatantly"
,
"employer" : "Monsters Inc."
]
现在有了两个 should 子句,你可以看到得分发生了变化,并且 Philipp 作为姓氏不再得分最高。 这可能是期望的行为,也可能不是。 我们能做些什么来再次增加姓氏得分? 或者可能减少两个 should 从句? 另一个解决方案是给联系人打分更高,但员工只有在他们还没有联系人的情况下 - 因为这个查询变得更加复杂,这对你来说是一个练习。
另一种解决方案是通过将查询的必须部分更改为
"must": [
"multi_match":
"query": "Philipp",
"boost": 2,
"fields": [
"name.last",
"name.first"
]
]这样,must 部分变得更加重要。 如你所见,有很多方法可以调整和尝试使用你自己的数据。
还有最后一件事。
使用 “search-as-you-type” 数据类型
我们还没有涉及的一件事是部分匹配。 搜索 Philip 还应该返回我们数据集中的所有 Philipps。
现在下面的查询只返回 Philip Jan Kredible,我们唯一的只含有一个 p 字母的 Philip。
GET social-network/_search?filter_path=**.name.full,**._score,**.employer
"query":
"bool":
"should": [
"terms":
"_id":
"index": "social-network",
"id": "alexr",
"path": "contacts"
,
"match":
"employer": "Elastic"
],
"must": [
"multi_match":
"query": "Philip",
"boost": 2,
"fields": [
"name.last",
"name.first"
]
]
还记得一开始的映射吗? name 字段包含我们现在利用的 search-as-you-type 类型映射。 该字段针对搜索进行了优化,因为你通过存储字段 shingle 和 edge ngram 标记过滤器来开箱即用地键入用例,以确保查询尽可能快 - 以需要更多磁盘空间为代价。
让我们切换 multi match 查询的类型:
GET social-network/_search?filter_path=**.name.full,**._score,**.employer
"query":
"bool":
"should": [
"terms":
"_id":
"index": "social-network",
"id": "alexr",
"path": "contacts"
,
"match":
"employer": "Elastic"
],
"must": [
"multi_match":
"query": "Philip",
"boost": 2,
"type": "phrase_prefix",
"fields": [
"name.last.search-as-you-type",
"name.first.search-as-you-type"
]
]
这将返回:
"hits" :
"hits" : [
"_score" : 5.47071,
"_source" :
"name" :
"full" : "Philip Kredible"
,
"employer" : "Elastic"
,
"_score" : 3.3479528,
"_source" :
"name" :
"full" : "Felix Philipp"
,
"employer" : "Felixia"
,
"_score" : 3.1550717,
"_source" :
"name" :
"full" : "Philipp Krenn"
,
"employer" : "Elastic"
,
"_score" : 2.2127438,
"_source" :
"name" :
"full" : "Philipp Laughable"
,
"employer" : "FancyWorks"
,
"_score" : 1.2127436,
"_source" :
"name" :
"full" : "Philipp Incredible"
,
"employer" : "21st Century Marketing"
,
"_score" : 0.8805573,
"_source" :
"name" :
"full" : "Philipp Jean Blatantly"
,
"employer" : "Monsters Inc."
]
首先是完全匹配(philip),第二是得分最高的姓氏(Philipp),然后是我的同事 Philipp Krenn。 看起来不错!
现在我们得到了完美的搜索? 好吧……尝试搜索 Philipp K - 我们没有得到任何结果。 那很糟!
然而,由于我们的摄入管道,我们也获得了全名索引,让我们将其添加到正在搜索的字段中:
GET social-network/_search?filter_path=**.name.full,**._score,**.employer
"query":
"bool":
"should": [
"terms":
"_id":
"index": "social-network",
"id": "alexr",
"path": "contacts"
,
"match":
"employer": "Elastic"
],
"must": [
"multi_match":
"query": "Philipp K",
"boost": 2,
"type": "phrase_prefix",
"fields": [
"name.full.search-as-you-type",
"name.last.search-as-you-type",
"name.first.search-as-you-type"
]
]
现在搜索 Philip、Philipp 和 Philipp K 会返回正确的结果。
还有一件事……
不关心 term 的顺序
不是每个人都知道他正在搜索的人的全名,所以有时你可能只输入姓氏。 搜索 Krenn 按预期工作,但是搜索 Krenn P 不会产生任何结果!
那么,我们能做些什么呢? 让我们的查询更大一点:
GET social-network/_search?filter_path=**.name.full,**._score,**.employer
"query":
"bool":
"should": [
"terms":
"_id":
"index": "social-network",
"id": "alexr",
"path": "contacts"
,
"match":
"employer": "Elastic"
],
"must": [
"bool":
"should": [
"multi_match":
"query": "Krenn P",
"operator": "and",
"boost": 2,
"type": "bool_prefix",
"fields": [
"name.full.search-as-you-type",
"name.full.search-as-you-type._2gram",
"name.full.search-as-you-type._3gram"
]
,
"multi_match":
"query": "Krenn P",
"boost": 2,
"type": "phrase_prefix",
"fields": [
"name.full.search-as-you-type",
"name.last.search-as-you-type",
"name.first.search-as-you-type"
]
]
]
此查询在所有先前情况下的行为相似,但还支持以任意顺序搜索术语(如姓氏在前),同时仍提供补全支持。上面的搜索结果为:
"hits" :
"hits" : [
"_score" : 7.384149,
"_source" :
"name" :
"full" : "Philipp Krenn"
,
"employer" : "Elastic"
]
现在作为最后一步,让我们在搜索端使它更易于维护。
使用搜索模板
最后一步是存储此搜索,以便搜索客户端只需提供一次输入查询。
让我们存储一个 mustache 脚本:
POST _scripts/social-query
"script":
"lang": "mustache",
"source":
"query":
"bool":
"should": [
"terms":
"_id":
"index": "social-network",
"id": "own_id",
"path": "contacts"
,
"match":
"employer": "employer"
],
"must": [
"bool":
"should": [
"multi_match":
"query": "query_string",
"operator": "and",
"boost": 2,
"type": "bool_prefix",
"fields": [
"name.full.search-as-you-type",
"name.full.search-as-you-type._2gram",
"name.full.search-as-you-type._3gram"
]
,
"multi_match":
"query": "query_string",
"boost": 2,
"type": "phrase_prefix",
"fields": [
"name.full.search-as-you-type",
"name.last.search-as-you-type",
"name.first.search-as-you-type"
]
]
]
现在查询超短,我们只需要提供一些查询信息:
GET social-network/_search/template
"id": "social-query",
"params":
"query_string": "Philipp",
"own_id" : "alexr",
"employer" : "Elastic"
这种方法的另一个优点是,你现在可以在不更改应用程序的情况下切换查询的底层实现。 你甚至可以做一些花哨的事情,比如 a/b 测试。
最终优化:排除自己
尽管这在开始时听起来很有用,但我敢打赌,每个人都会时不时地在每个社交网络上搜索自己。 关闭自恋很难 :-)
你可以在 bool 查询中添加另一个过滤 own_id 的 must_not 子句,并确保你在搜索内容时永远不会看到自己,但我认为这可能是一种不错的感觉。 此外,如果你继续包括自己,你可能希望使用 should 子句给自己打高分。
我特意没有在此处包含此示例,请随意尝试。
以上是关于Elasticsearch:使用 Elasticsearch 在键入时实现类似 Linkedin 的搜索的主要内容,如果未能解决你的问题,请参考以下文章