PyTorch 加载超大 Libsvm 格式数据
Posted Alex_996
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PyTorch 加载超大 Libsvm 格式数据相关的知识,希望对你有一定的参考价值。
对于比较大的数据集,比如好几个T的数据,没有办法一次性全部加载进内存,因此需要构建一个可迭代的数据集IterableDataset。
迭代读取文本文件
要借助pytorch的IterableDataset模块,官方文档是:IterableDataset。
按照官网的说法,需要继承这个IterableDataset类,然后覆写__iter__这个方法,返回一个可迭代的对象即可。
因为我们要处理的时标准 Libsvm 格式数据,所以还需要实现又给process_line函数处理每一行数据。
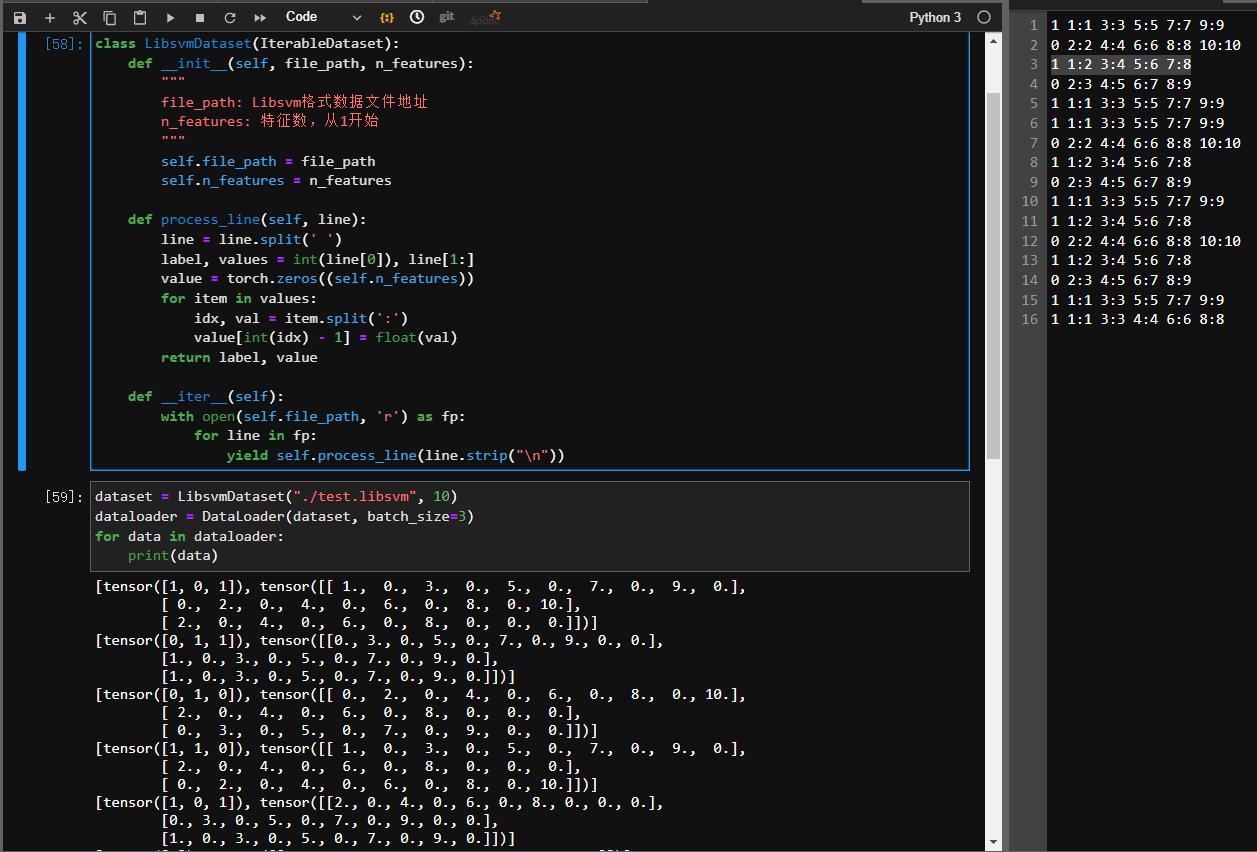
class LibsvmDataset(IterableDataset):
def __init__(self, file_path, n_features):
"""
file_path: Libsvm格式数据文件地址
n_features: 特征数,从1开始
"""
self.file_path = file_path
self.n_features = n_features
def process_line(self, line):
line = line.split(' ')
label, values = int(line[0]), line[1:]
value = torch.zeros((self.n_features))
for item in values:
idx, val = item.split(':')
value[int(idx) - 1] = float(val)
return label, value
def __iter__(self):
with open(self.file_path, 'r') as fp:
for line in fp:
yield self.process_line(line.strip("\\n"))
然后我们就可以直接把LibsvmDataset通过DataLoader封装成一个加载器。
dataset = LibsvmDataset("./test.libsvm", 10)
dataloader = DataLoader(dataset, batch_size=3)
for data in dataloader:
print(data)
以上是关于PyTorch 加载超大 Libsvm 格式数据的主要内容,如果未能解决你的问题,请参考以下文章