强化学习笔记 experience replay 经验回放
Posted UQI-LIUWJ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了强化学习笔记 experience replay 经验回放相关的知识,希望对你有一定的参考价值。
1 回顾 :DQN
DQN 笔记 State-action Value Function(Q-function)_UQI-LIUWJ的博客-CSDN博客
DQN是希望通过神经网络来学习Q(s,a)的结果,我们输入一个人状态s,通过DQN可以得到各个action对应的Q(s,a)
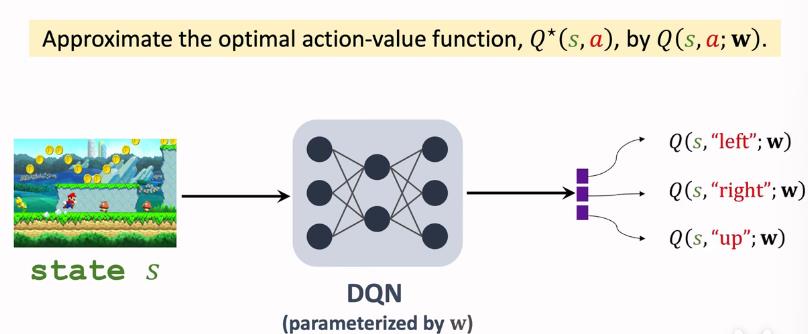
通常用TD来求解DQN
其中rt是实际进行交互得到的真实奖励,Q(s,a),
是预测得到的价值函数
(注:Q是fixed target network,所以qt和yt会稍有不同)
在之前我们所说的DQN中,我们每次采样得到一组episode
,然后就用这组episode来计算相应的loss,进行梯度下降更新参数
而用这组数据训练了模型之后,这组数据就被丢弃了


2 TD算法的缺点
2.1 缺乏经验

而事实上,经验是可以重复使用的
2.2 correlated updates
比如玩游戏,当前画面和下一帧画面之间的区别会非常小,也就是 会非常相近。实验证明把这些episode数据尽量打散,有利于训练得更好
会非常相近。实验证明把这些episode数据尽量打散,有利于训练得更好

3 经验回放
经验回放可以克服之前的两个缺点
把最近的n条记录存到一个buffer里面
如果存满了,每次存入一条新的transition,就删除当前最老的那一条transition
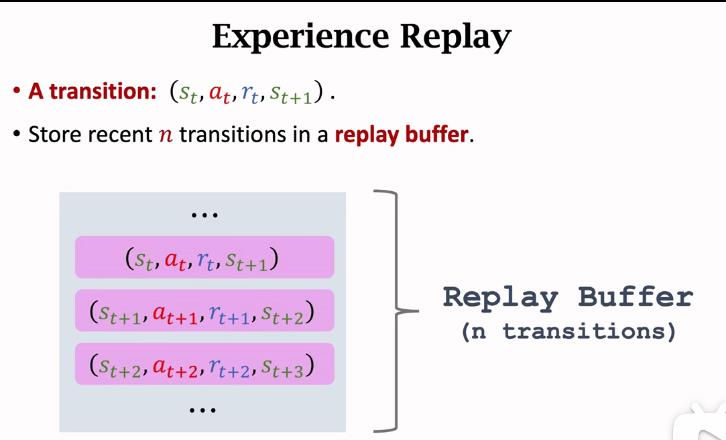
3.1 使用经验回放之后的TD

这里是从buffer中随机选择一个transition,实际上是从buffer中随机选择一个batch,做mini-batch SGD
3.2 经验回放的好处
1 打破了transition的关联性
2 经验可以重复使用
4 优先经验回放
buffer里面有多条 transition,每条的优先级各不相同
比如以超级玛丽为例,左边是普通关卡,右边是打boss的关卡。左边常见右边不常见。由于右边的经验少,所以很难真正训练除右边的情况应该如何做决策,在这种情况下,右边的重要性更大一些。

在priority experience replay 中,如果一条transition有更高的TD error δt,那么我们就认为他距离TD target比较大,DQN就不熟悉这个场景,所以需要给他较大的优先级。
优先经验回放的思路就是用非均匀抽样代替均匀抽样,有两种抽样方法
rank(t)是δt排序后的序号,δt越大,rank(t)越小

抽样的时候是非均匀采样的,我们需要相应地调整学习率,以减少不同抽样概率带来的偏差
如果一条transition有较大的抽样概率,那么他的学习率应当相应地小一些 (用来抵消大抽样概率带来的偏差,因为大抽样概率那么我被采样到的次数就会稍多)

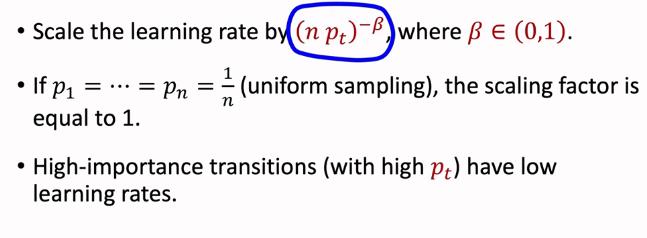
如果一条transition 刚被采集到,我们是不知道他的δt的,此时我们直接给他设置最大的优先级,也就是未被使用过的transition具有最高的优先级
每次使用一条transition之后,我们都要重新更新他的δt

参考资料:
以上是关于强化学习笔记 experience replay 经验回放的主要内容,如果未能解决你的问题,请参考以下文章