DataLink 数据同步平台
Posted 木兮同学
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了DataLink 数据同步平台相关的知识,希望对你有一定的参考价值。
一、数据同步平台
在项目开发中,经常需要将数据库数据同步到 ES、Redis 等其他平台,通过自己写代码进行同步过程中面临诸多问题,比如业务代码和同步代码高耦合,数据一致性等;一个支持多输入输出源的数据同步平台就显得很有意义。
概述
- DataLink 数据平台基于当前成熟的 Canal、定时任务补偿、Dubbo 泛化调用等方案,实现异构数据平台的同步和最终一致性问题,支持集群部署。通过 DataLink 健康检查程序,可以对所有中间件和 DataLink 本身服务的异常情况(包括服务宕机等)进行补偿操作。
- DataLink 当前主要支持对 mysql 数据同步到 ElasticSearch,对 Oracle、Redis 以及其他 RDB 的输出正在规划中。
核心能力
- Canal 实时同步
Canal 订阅 Mysql binlog,推送数据变更信息到 RocketMQ,监听 MQ 处理变更数据到 ElasticSearch - 区间数据健康检查、自动补偿
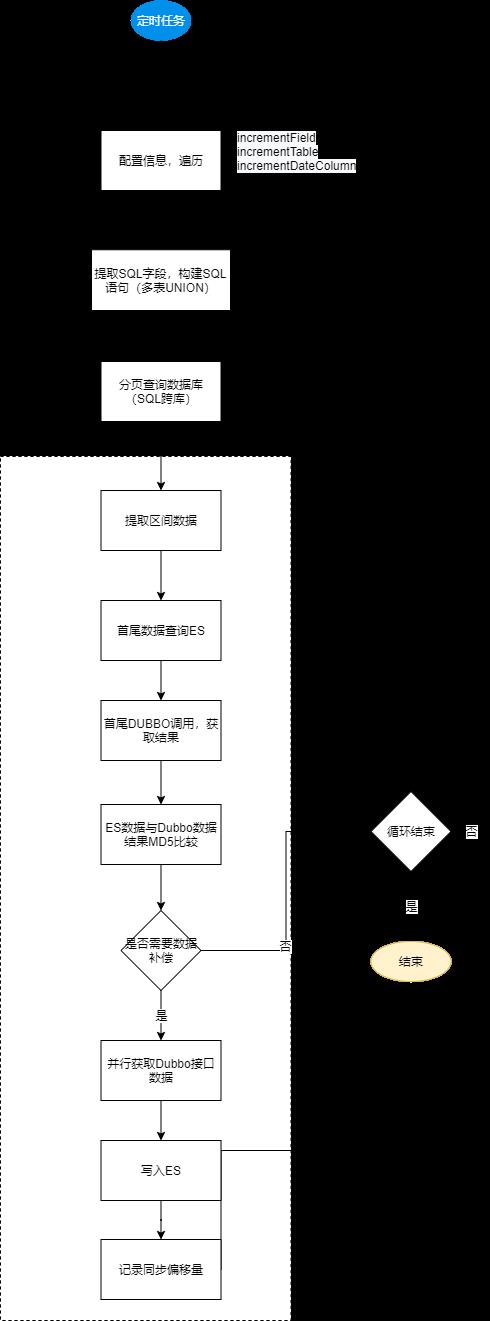
基于 Elastic-Job 定时任务方式,MD5 比较 ES 与数据库信息,有差异则同步,同时解决所有中间件或同步程序可能的异常情况补偿 - 基于 RocketMQ 的自定义同步支持
接入方在没有部署 Canal Server,仅有 RocketMQ 的情况下,主动往 RocketMQ 发送数据请求同步
工作原理
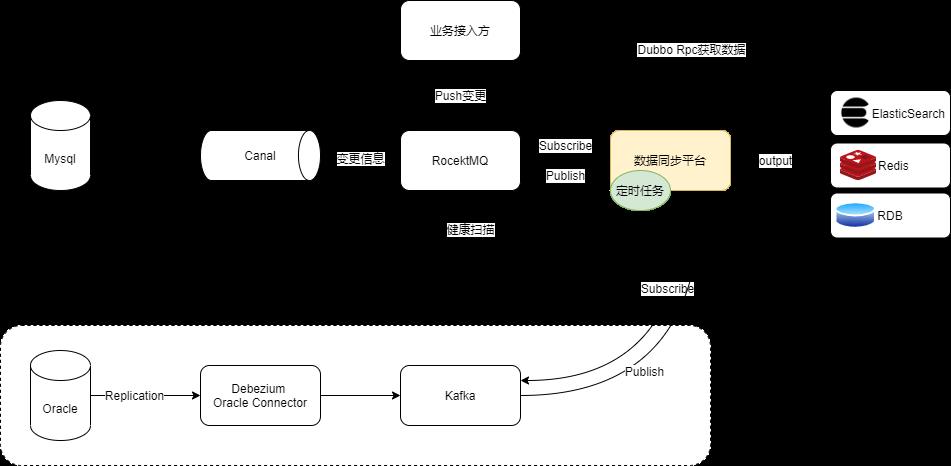
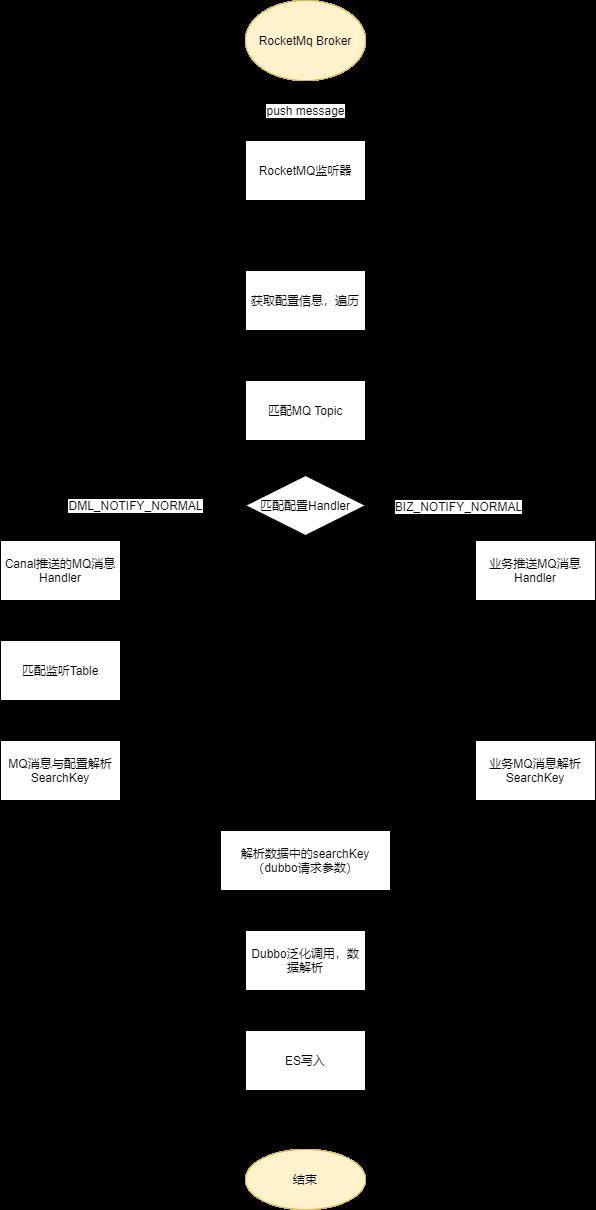
详细流程
-
实时数据同步流程
-
健康检查与补偿流程
二、快速接入
部署中间件
- 部署 Canal Server,使用 MQ 模式,可参考 https://github.com/alibaba/canal
- 部署 ElasticSearch 6.x,参考 https://www.elastic.co/cn/blog/state-of-the-official-elasticsearch-java-clients
- 部署 Rocketmq
程序配置
spring:
datasource:
name: datalink-service
type: com.alibaba.druid.pool.DruidDataSource
url: jdbc:mysql://127.0.0.1:3306/ins_basicdata_prd?autoReconnect=true&characterEncoding=UTF8&useSSL=false&serverTimezone=UTC
username: meicloud_ssc
password: meicloud
driver-class-name: com.mysql.jdbc.Driver
dubbo:
application:
name: datalink
registry:
address: zookeeper://127.0.0.1:2181?timeout=30000
protocol: zookeeper
timeout: 60000
protocol:
port: 21990
name: dubbo
id: dubbo
consumer:
timeout: 6000
rocketmq:
# 业务方主动推送 MQ 变更配置(可选)
biz:
namesrvAddr: 127.0.0.1:9876
groupName: datalinkBizConsumerGroup
# canal监听的变更 MQ 配置
canal:
namesrvAddr: 127.0.0.1:9876
groupName: datalinkCommonConsumerGroup
elaticjob:
zookeeper:
server-lists: 127.0.0.1:2181
namespace: datalink
elasticsearch:
cluster-name: elasticsearch
cluster-nodes: 127.0.0.1:9300
创建数据库表
CREATE TABLE `m_elastic_search_cfg` (
`id` BIGINT(20) NOT NULL AUTO_INCREMENT COMMENT '主键id',
`config_name` VARCHAR(64) NOT NULL COMMENT '配置名字',
`match_topic` VARCHAR(64) NOT NULL COMMENT '匹配的topic',
`listen_table` TEXT COMMENT '匹配的数据库和数据表',
`primary_key` VARCHAR(64) DEFAULT NULL COMMENT '主键',
`interface_name` VARCHAR(128) NOT NULL COMMENT '接口名字',
`function_name` VARCHAR(128) NOT NULL COMMENT '方法名字',
`search_class` VARCHAR(128) NOT NULL COMMENT '方法的参数',
`search_key` VARCHAR(64) NOT NULL COMMENT '方法的参数的主键',
`data_node_path` VARCHAR(64) DEFAULT NULL COMMENT '数据节点路径',
`version` VARCHAR(64) DEFAULT NULL COMMENT '版本',
`es_index` VARCHAR(64) NOT NULL COMMENT 'es的索引',
`handler` VARCHAR(64) NOT NULL COMMENT '处理类',
`increment_field` VARCHAR(64) DEFAULT NULL COMMENT '定时器补偿字段',
`increment_table` TEXT COMMENT '定时器补偿表',
`increment_date_column` VARCHAR(64) NOT NULL DEFAULT 'UPDATE_TIME' COMMENT '定时器补偿日期字段',
`last_check_time` DATETIME DEFAULT NULL COMMENT '定时器最近同步日期',
`create_time` DATETIME DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`id`)
) ENGINE=INNODB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8mb4 COMMENT='es配置表'
- match_topic
配置格式为:ins_trade_prd_0,ins_trade_prd_[0-9](监听 ins_trade_prd_0 到 ins_trade_prd_9) - listen_table
监听表配置,支持正则表达式,例如 ins_trade_prd_[0-9]+\\.t_order_main.* 表示监听数据库 ins_trade_prd_0 到 ins_trade_prd_9 10 个数剧库,前缀为 t_order_main 的所有表(分表)。仅 handler 为 DML_NOTIFY_NORMAL 需要配置。 - primary_key
主键或者从表的外键,即能从 canal 监听的 dml 数据中提取出用于 dubbo 查询的 searchKey 值;逗号间隔,依次提取 - interface_name、function_name、search_class、search_key、data_node_path 和 version
都是配置 dubbo provider 的接口信息,其中 data_node_path 指定返回结果的数据路径 $.content(符合 jsonpath 语法,以 $ 开头) - handler
BIZ_NOTIFY_NORMAL,监听业务推送消息Handler
DML_NOTIFY_NORMAL,监听业务表数据变更Handler - increment_field、increment_table、increment_date_column
分别为定时任务健康检查和补偿相关字段。increment_table的配置规则同上面match_topic
启动应用
- 运行 DataLinkApplication 类启动应用程序,几种触发数据同步方式:
- Canal 监听的业务数据表发生变更
- 主动往业务 MQ 插入消息
- 等待定时任务健康检查、数据补偿
注意事项
- 同步 ES 的索引需要建立,Mapping 映射最好可以先建立(如果不建立,由 ES 动态创建 Mapping)
- 分库分表情况下,库需要在同一个 IP 下,能够互相访问
三、扩展:四种 CDC 方案比较优劣
- 抽取处理需要重点考虑增量抽取,也被称为变化数据捕获,简称 CDC。假设一个数据仓库系统,在每天夜里的业务低峰时间从操作型源系统抽取数据,那么增量抽取只需要过去 24 小时内发生变化的数据。变化数据捕获也是建立准实时数据仓库的关键技术。
- 当你能够识别并获得最近发生变化的数据时,抽取及其后面的转换、装载操作显然都会变得更高效,因为要处理的数据量会小很多。遗憾的是,很多源系统很难识别出最近变化的数据,或者必须侵入源系统才能做到。变化数据捕获是数据抽取中典型的技术挑战。
- 常用的变化数据捕获方法有时间戳、快照、触发器和日志四种。相信熟悉数据库的读者对这些方法都不会陌生。时间戳方法需要源系统有相应的数据列表示最后的数据变化。快照方法可以使用数据库系统自带的机制实现,如 Oracle 的物化视图技术,也可以自己实现相关逻辑,但会比较复杂。触发器是关系数据库系统具有的特性,源表上建立的触发器会在对该表执行 insert、update、delete 等语句时被触发,触发器中的逻辑用于捕获数据的变化。日志可以使用应用日志或系统日志,这种方式对源系统不具有侵入性,但需要额外的日志解析工作。
- CDC 大体可以分为两种,一种是侵入式的,另一种是非侵入式的。所谓侵入式的是指 CDC 操作会给源系统带来性能的影响。只要 CDC 操作以任何一种方式对源库执行了 SQL 语句,就可以认为是侵入式的 CDC。基于时间戳的 CDC、基于触发器的 CDC、基于快照的 CDC 是侵入性的,基于日志的 CDC 是非侵入性的。
- 下表总结了四种CDC方案的特点。
| 项目 | 时间戳方式 | 快照方式 | 触发器方式 | 日志方式 |
|---|---|---|---|---|
| 能区分插入/更新 | 否 | 是 | 是 | 是 |
| 周期内,检测到多次更新 | 否 | 否 | 是 | 是 |
| 能检测到删除 | 否 | 是 | 是 | 是 |
| 不具有侵入性 | 否 | 否 | 否 | 是 |
| 支持实时 | 否 | 否 | 是 | 是 |
| 需要 DBA | 否 | 否 | 是 | 是 |
| 不依赖数据库 | 是 | 是 | 否 | 否 |
说明:本篇是公司研发平台数据同步的一套解决方案,目前在公司多个项目中已落地,效果还不错,本人在此进行一个分享和记录,其中源码不对外开放,欢迎一起探讨~。
以上是关于DataLink 数据同步平台的主要内容,如果未能解决你的问题,请参考以下文章