Iceberg文件组织原理
Posted 咬定青松
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Iceberg文件组织原理相关的知识,希望对你有一定的参考价值。
本文首发微信公众号:码上观世界
Understanding the rise of China
演讲者:Martin Jacques 马丁·雅克
语言:英语
简介:2010 | 在TED伦敦沙龙会上,经济学家马丁·雅克Martin Jacques问:在西方我们对中国和它显著的崛起现象有多少认识?作为《当中国统治世界》的作者,他解释了西方国家常常对中国经济的快速增长力感到困惑的理由,他提出3个基础观点来帮助我们理解当代的中国现实和中国未来的展望。
(查看原文链接有文字版)
Iceberg文件组织概述
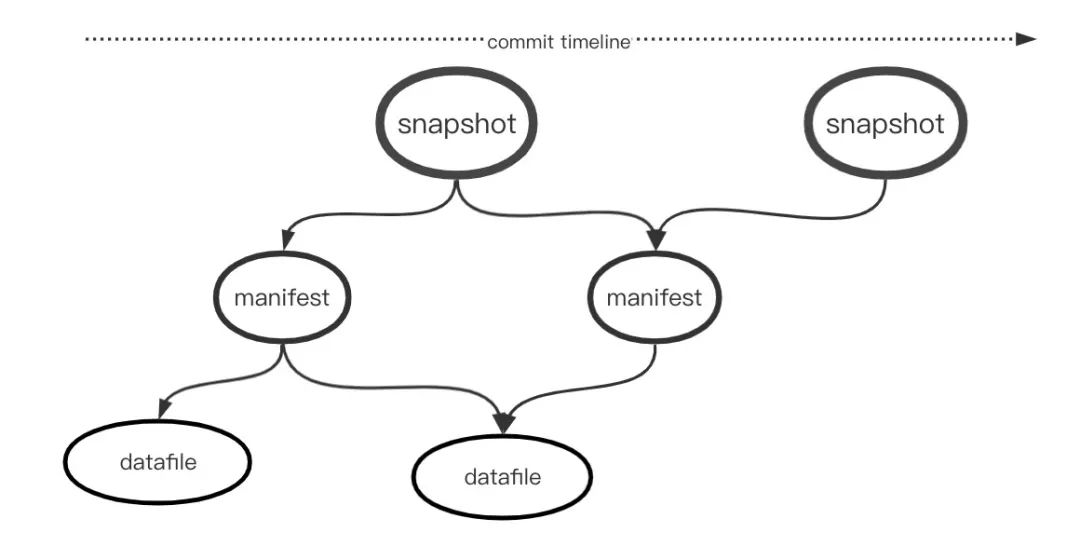
Iceberg通过快照隔离的方式实现数据的并发批量读写,每个快照反映了当前checkpoint发生的数据变更,比如快照发生的时间、增删或者修改的数据内容等,应用端可以通过快照增量消费数据或者回溯历史数据。快照通过层级的文件组织,所有文件都存储在分布式文件系统或者分布式对象系统,因为快照文件本身存储了相应层级文件的详细信息,不仅有效减轻对HDFS NameNode的访问压力,还有效扩展了Hive Metastore的存储和读写能力,下图展示的是 Iceberg 的整个文件组织格式,从上往下看依次是:
Snapshot。Iceberg 里面的 Snapshot 是一个用户可读取的基本的数据单位,用户可以从任意时间段的快照开始读取数据,读取的数据是截止当前快照时刻的全量数据,如果将两个快照的数据相减,即可得到两个快照期间的增量变更数据。每个 Snapshot 下面会有多个 Manifest,Snapshot存储每个Manifest的元信息,快照通过Manifest-list记录所辖的多个Manifest文件,一个快照对应一个Manifest-list。
Manifest。每个 Manifest 下面会管理一个至多个 DataFiles 文件,Manifest 文件里面存放的是这些物理数据文件的元信息。
DataFiles。存储数据的原始文件,数据格式由Iceberg表的Schema决定。
为管理的便利和性能需要,Manifest文件根据数据文件的类型分为2种,分别是数据类型(都是新增数据)和删除类型(都是删除数据):
public enum ManifestContent
DATA(0),
DELETES(1);
数据文件根据存储原始数据的内容类型也分为多种类型,新增数据类型、基于Position删除的数据类型和基于Equality删除的数据类型:
public enum FileContent
DATA(0),
POSITION_DELETES(1),
EQUALITY_DELETES(2);
Manifest会记录每个数据文件的状态,包括现存、新增、删除 三种:
interface ManifestEntry<F extends ContentFile<F>>
enum Status
EXISTING(0),
ADDED(1),
DELETED(2);
Snapshot存储Manifest的元数据,Manifest的元数据属性与含义定义见下表(类定义ManifestFile):

Manifest存储数据文件的元数据,数据文件的元数据的属性与含义定义见下表(类定义DataFile):

Iceberg文件操作
接下来我们以常见的数据添加、删除、更新操作来演示Iceberg如何通过文件组织存储数据。所有操作记录以相同的Schema:
public static final Schema SCHEMA = new Schema(
Types.NestedField.optional(1, "id", Types.IntegerType.get()),
Types.NestedField.optional(2, "data", Types.StringType.get())
);只有两个字段,整数类型的id和字符串类型的data,其中id可以当做更新的主键来用。而数据操作分两种情况:在同一个事务中进行和不在一个事务中进行。操作类型+I标识插入、-U标识更新之前,+U标识更新之后、-D标识删除。
记录添加
在同一个事务中添加两条记录:
[+I(1,a),+I(2,b)]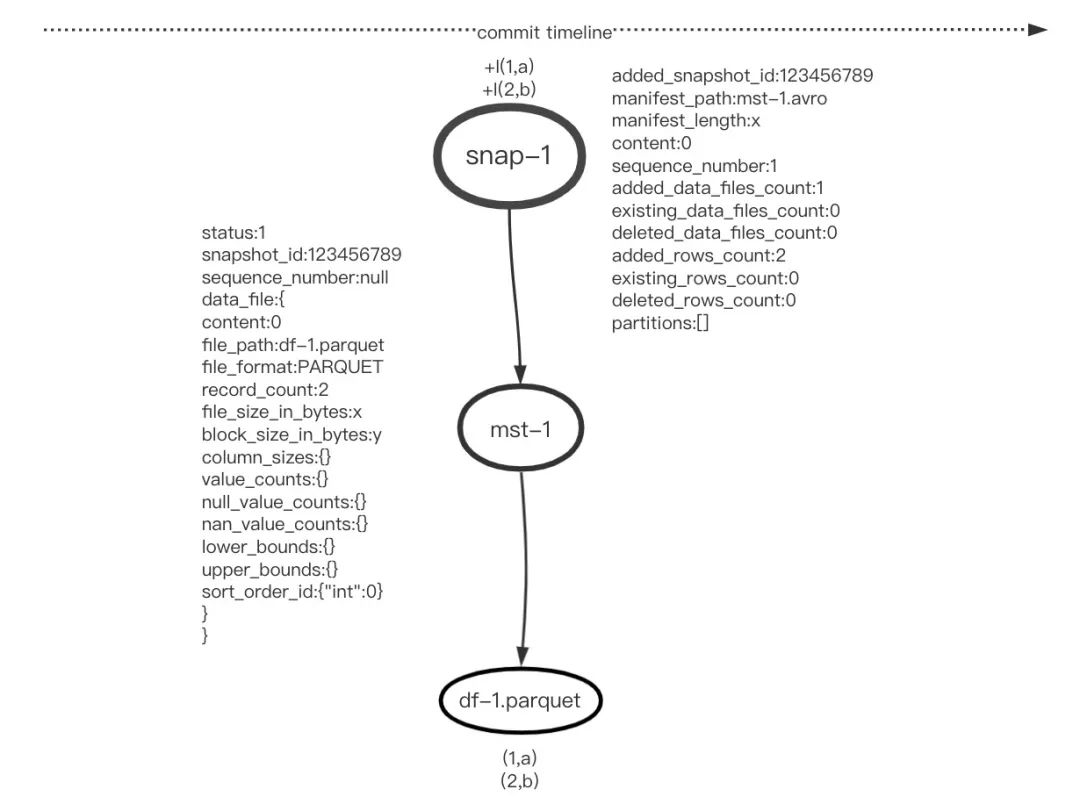
在本次一个事务提交中,该快照对应了一个Manifest文件,Manifest文件包含一个数据文件,数据文件存储了两条记录。
在不同事务中添加两条记录,分别通过两次commit操作提交
[+I(1,a)]
[+I(2,b)]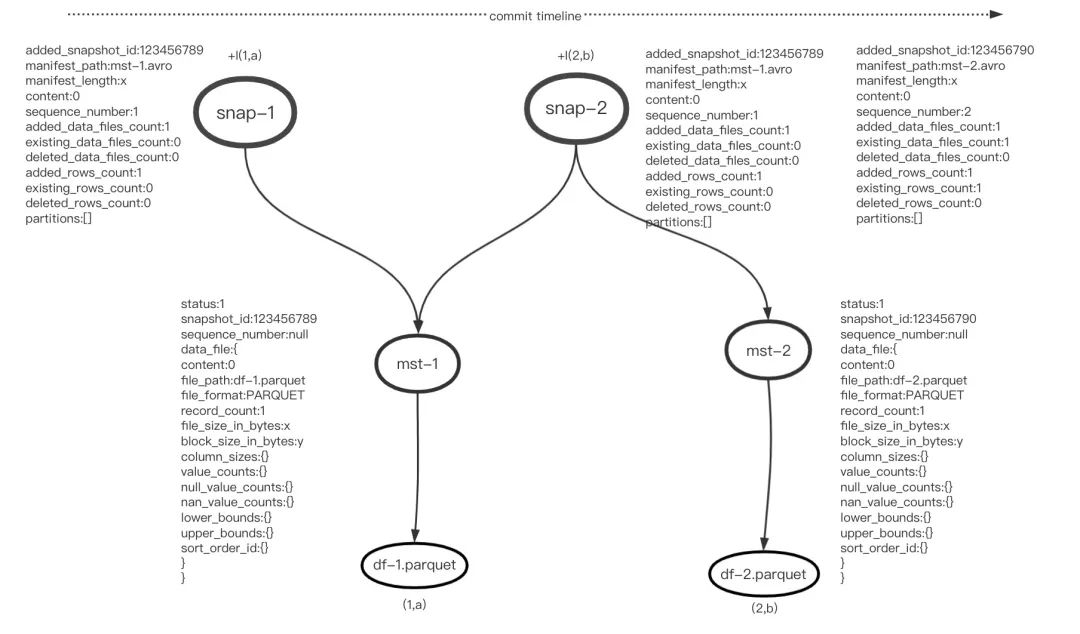
在本次提交中,产生了两个事务,每个事务快照对应了一个Manifest文件,且每个Manifest文件包含一个数据文件,每个数据文件存储一条记录。同上面不同之处在于,最新快照snap-2中存储了2条ManifestEntry,分别对应mst-1和mst-2,因此读取snap-2时候,需要加载更多的 Manifest文件和数据文件。
记录删除
在同一个事务中删除两条记录:
[+I(1,a),-D(1,a)]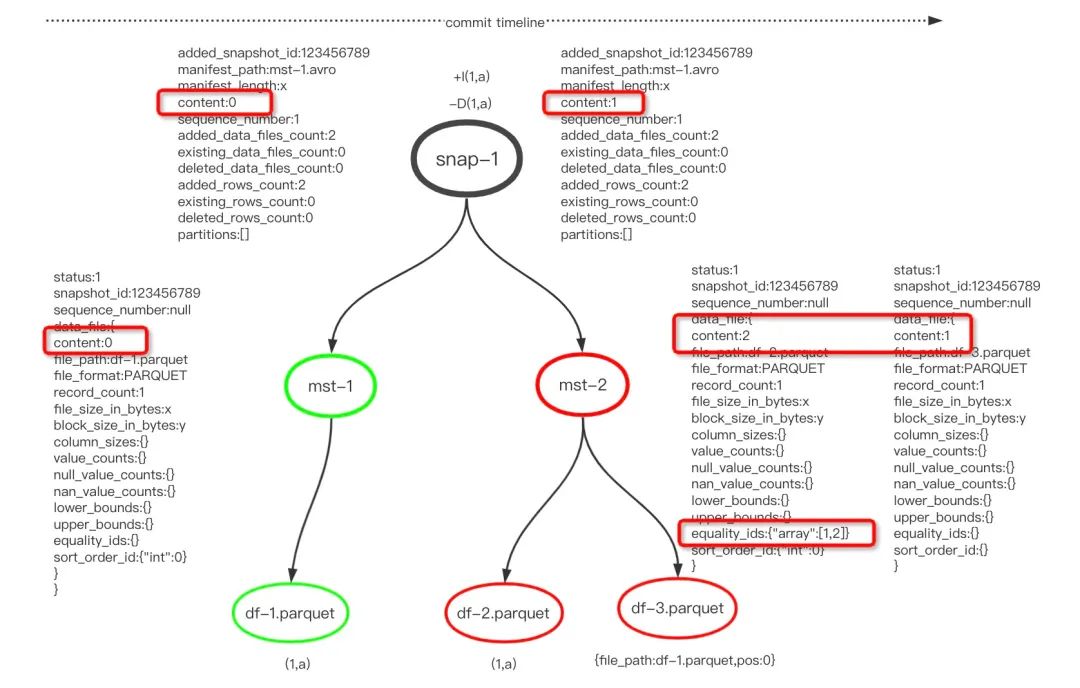
结果显示,该快照中产生了2条ManifestEntry,分别是添加类型的mst-1和删除类型的mst-2, 即 data manifest 和 delete manifest,这样区分的目的是为了加快查询。前者包含1个数据文件和1条记录,后者包含2个数据文件和2条记录,mst-2对应的两个datafile类型分别是基于Equality(content=2)和Position(content=1)。
之所以引入基于Position删除是因为在一个事务中可能存在的反复添加删除导致误删的问题,比如有这样的操作序列[+(1,a),-D(1,a),+(1,a)],最终应该是有一条记录,但是基于Equality删除会将id=1的记录都给删除了,但是基于Position可以指定删除原文件第0行,从而避免删除多行。同时拥有Position删除方法,可以确保在其他事务中能正常删除id=1的记录。在查询的时候,先通过Position过滤当前事务中的数据,再在其他事务中通过Equality过滤。
在两个事务中删除两条记录:
[+I(1,a)]
[-D(1,a)]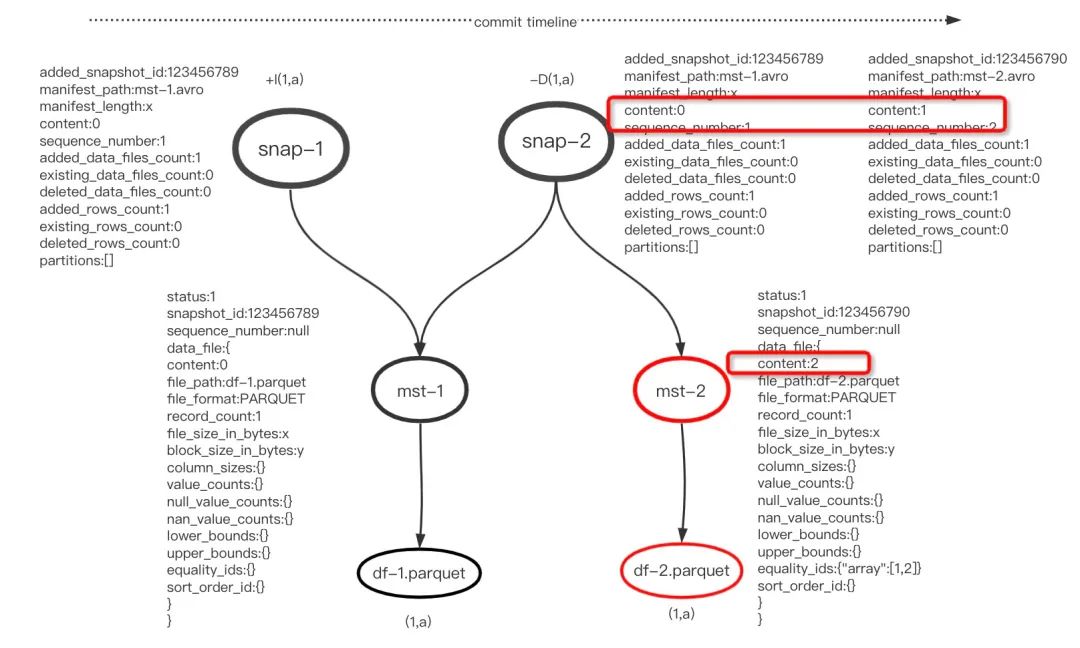
结果显示,第二次事务提交后,只用一个基于Equality的删除方式,产生一个content=2的删除数据文件,第一次快照提交时新增一个数据文件,查询时候根据快照snap-2中的删除文件过滤即可。
更新记录
在同一个事务中更新两条记录:
[+I(1,a),+U(1,b)]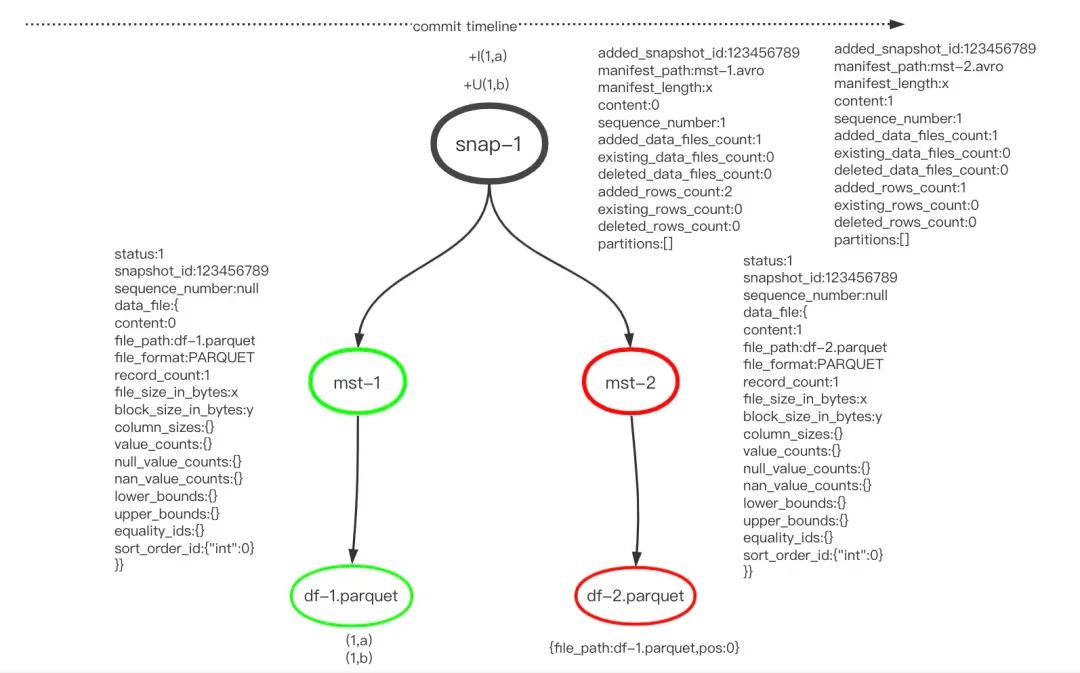
由图可知,更新记录被分为插入和删除两步操作,删除的记录记录在了mst-2,因为在一个事务中完成的,为了避免多次删除增加操作导致的误删,这里使用了基于Position的删除方式,删除信息指向了数据文件df-1的第0行。
分两次提交更新,第一次提交插入记录,
row("+I", 1, "aaa")第二次更新记录
row("-U", 1, "a"),
row("+U", 1, "b")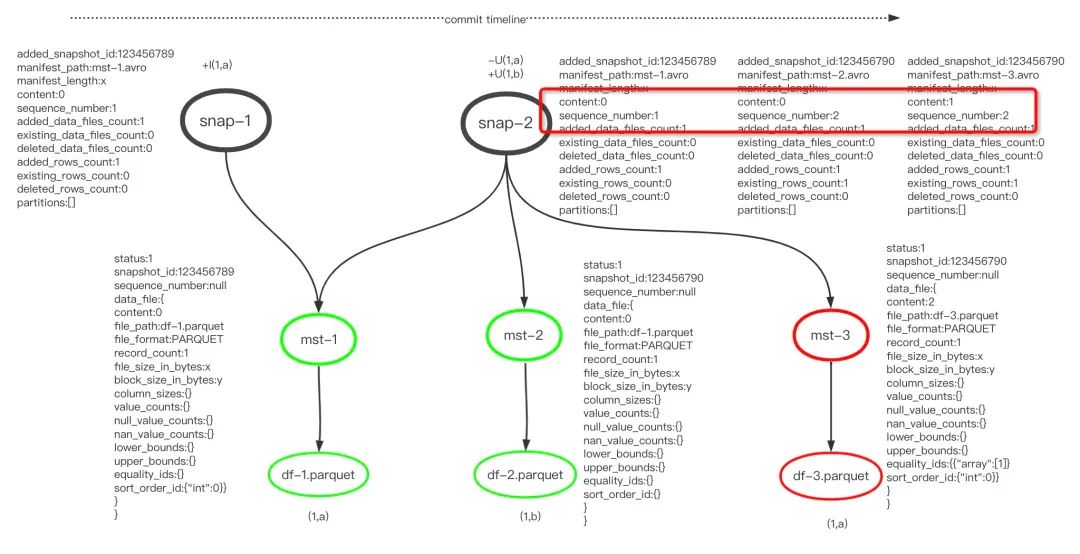
图示可知,在snap-2中根据id=1更新记录,除了新增一条记录(1,b),还在df-3中记录了删除记录(1,a),因为被删除记录不在当前快照,因此使用了基于Equality的删除方式。
文件合并
由上述文件操作可知,每次快照都产生了大量的文件,包括Manifest文件和数据文件,以及快照文件(包含Manifest-list)和上述这些文件的校验文件。当存在删除更新操作,Manifest文件和数据文件又拆分出来删除类型的对应文件,当快照执行频率过高且每次操作数据量较小时,会产生大量的小文件,从而导致系统性能减弱,为解决这类问题,Iceberg也提供了相应的文件合并、重写等操作来减轻这类问题。如下举例说明。
数据文件重写
Actions actions = Actions.forTable(table);
RewriteDataFilesActionResult result = actions
.rewriteDataFiles()
.splitOpenFileCost(1)
.execute();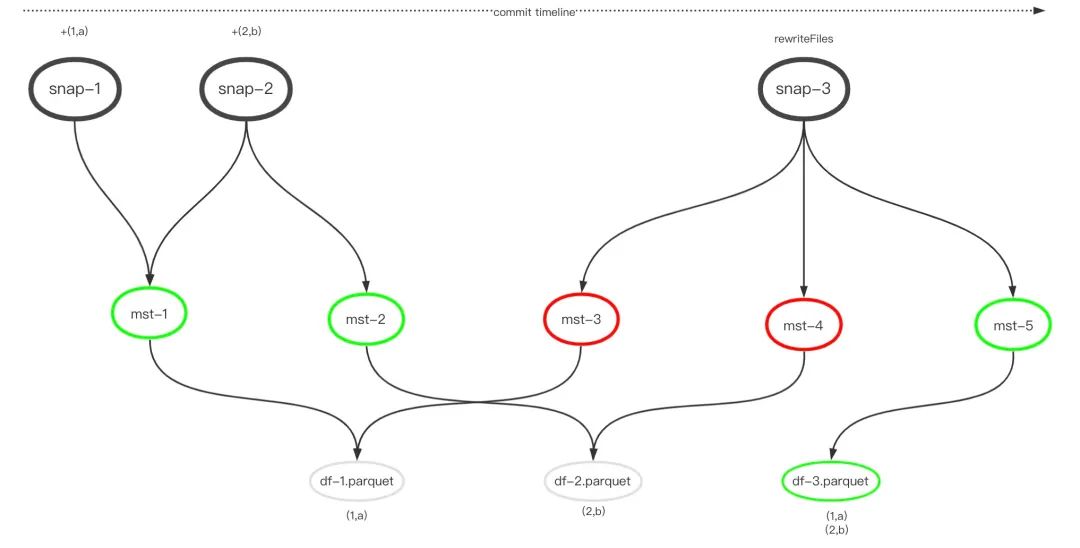
图中在两个事务(snap-1和snap-2)中分别增加1条记录,结果不出意料会生成2个manifst文件和2个datafile文件,我们期待这两条记录位于同一个文件,如在df-3,此时需要在snap-3中将数据文件df-1和df-2删除,为了能够保证之前的快照数据不被破坏,只能在snap-3中将增加指向这两个文件的移除指针。下图展示了执行snap-3后的元数据内容,mst-3和mst-4的status=2表示删除状态。mst-5指向的数据文件缩减为1个,代价是增加了Manifest文件数量。
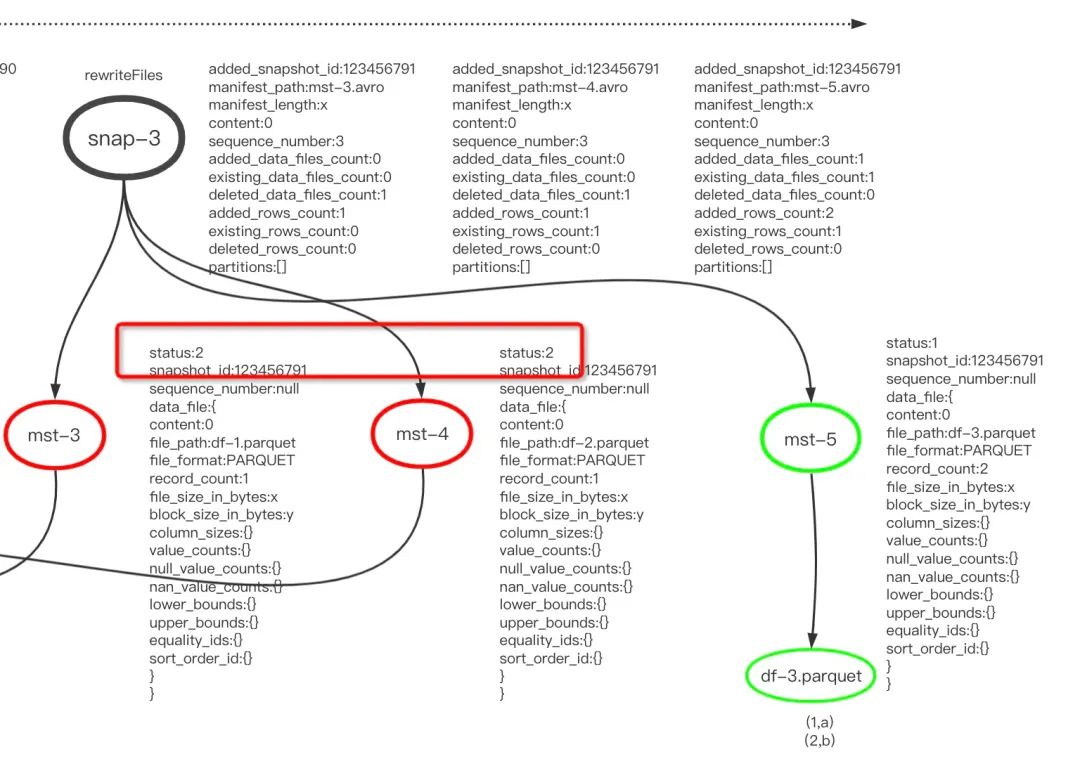
Manifest合并
Iceberg也提供了合并Manifest文件的功能,可以通过如下两种方式来开启自动合并。
table.updateProperties().set(SNAPSHOT_ID_INHERITANCE_ENABLED, "true").commit();
table.rewriteManifests()
.clusterBy(file -> "")
.commit();或者
table.updateProperties()
.set(TableProperties.MANIFEST_MIN_MERGE_COUNT, "1")
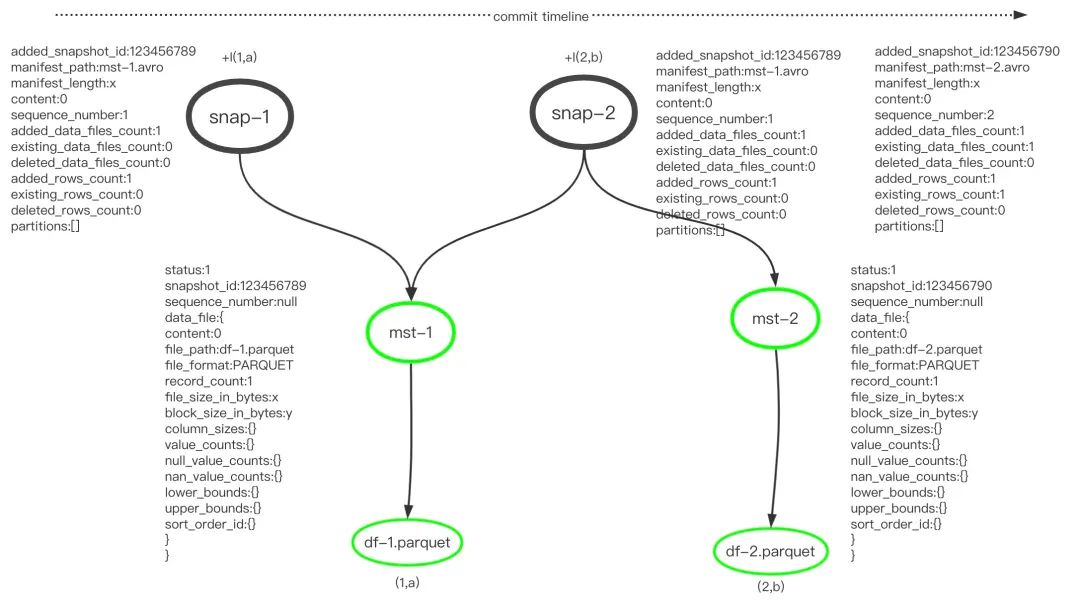
.commit();同样以在两个快照中分别新增一条记录为例,合并manifest之前的图示:
合并manifest之后的图示:
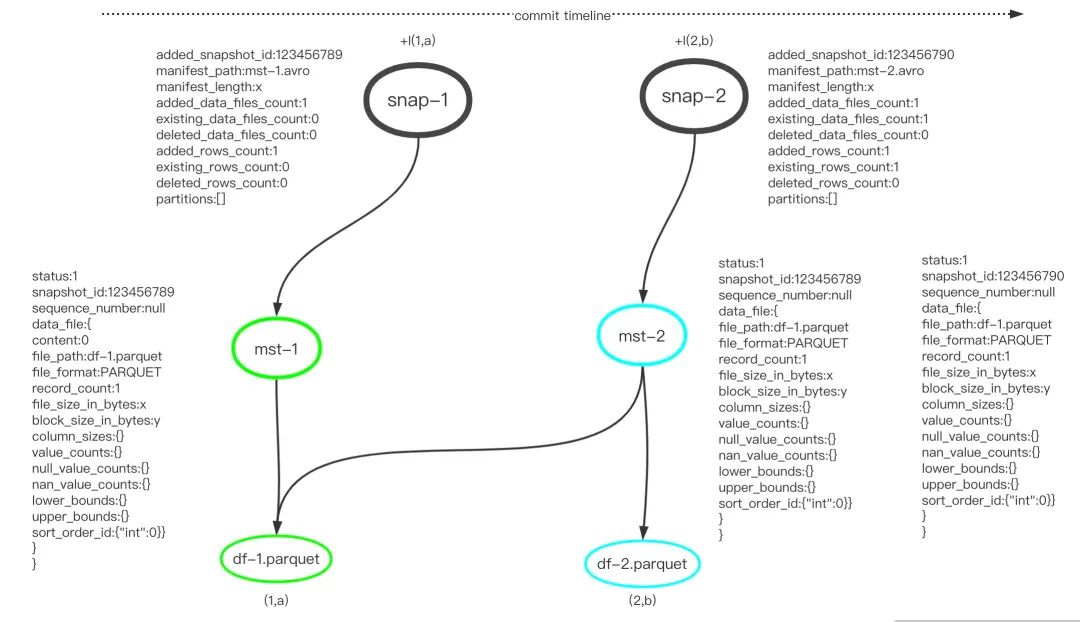
比较合并Manifest前后变化可知,虽然前后文件总数没变,但是合并后的snap-2指向的manifest文件数量少了1个,因为snap-2将mst-1的manifestEntry添加到了mst-2,减少了一次读取Manifest文件的开销。
以上是关于Iceberg文件组织原理的主要内容,如果未能解决你的问题,请参考以下文章