JUC学习之共享模型之工具上之线程池浅学
Posted 大忽悠爱忽悠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JUC学习之共享模型之工具上之线程池浅学相关的知识,希望对你有一定的参考价值。
JUC学习之共享模型之工具
线程池
1. 自定义线程池
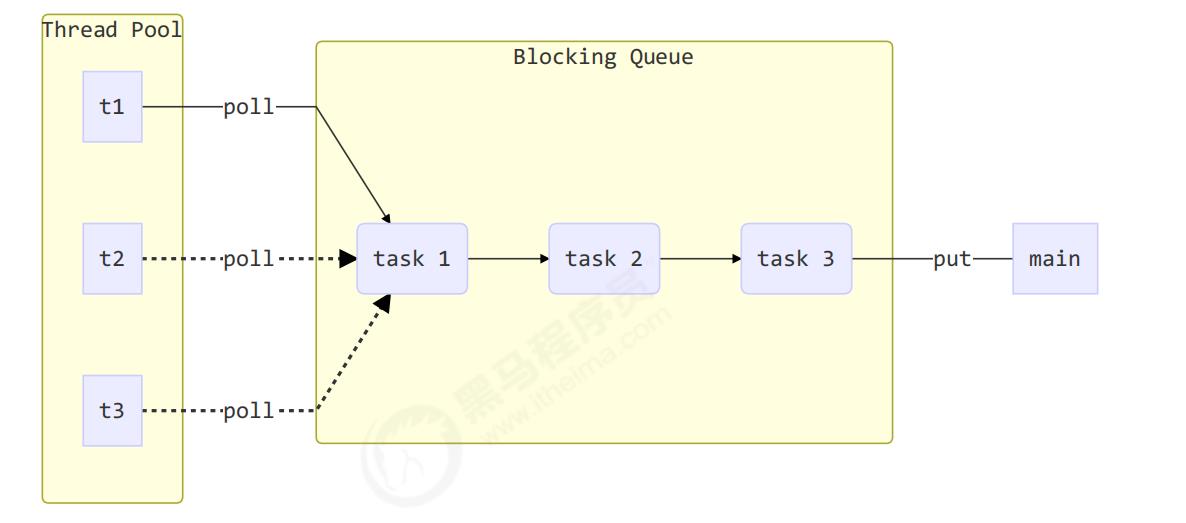
步骤1:自定义拒绝策略接口
package Pool;
@FunctionalInterface // 拒绝策略
interface RejectPolicy<T>
void reject(BlockingQueue<T> queue, T task);
步骤2:自定义任务队列
package Pool;
import lombok.extern.slf4j.Slf4j;
import java.util.ArrayDeque;
import java.util.Deque;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.ReentrantLock;
//阻塞队列
//TODO:泛型可以扩展阻塞队列的扩展性
@Slf4j
public class BlockingQueue<T>
//1.任务队列
private Deque<T> deque=new ArrayDeque<>();
//2.锁
private ReentrantLock lock=new ReentrantLock();
//3.生产者条件变量
private Condition fullWaitSet=lock.newCondition();
//4.消费者条件变量
private Condition emptyWaitSet=lock.newCondition();
//5.容量
private int capcity;
public BlockingQueue(int capcity)
this.capcity = capcity;
//带超时的阻塞获取----从队列头部获取一个任务
public T poll(long timeout, TimeUnit timeUnit)
//先上锁
lock.lock();
try
//将timeout统一转换为纳秒
long nanos = timeUnit.toNanos(timeout);
//TODO:队列为空陷入超时等待,否则返回一个任务
while(deque.isEmpty())
try
//等待超时
if(nanos<=0)
return null;
//返回剩余等待时间
//TODO:这里之所以会返回一个剩余时间,是因为存在被唤醒后抢不到锁的可能,因此会再次陷入休眠等待
nanos = emptyWaitSet.awaitNanos(nanos);
catch (InterruptedException e)
e.printStackTrace();
//返回任务
T first = deque.removeFirst();
//唤醒等待中的生产者线程
fullWaitSet.signal();
return first;
finally
//解锁
lock.unlock();
//阻塞获取任务---无限等待,直到被唤醒
public T take()
//加锁
lock.lock();
try
//当前没有任务
while(deque.isEmpty())
try
emptyWaitSet.await();
catch (InterruptedException e)
e.printStackTrace();
//返回任务
T first = deque.removeFirst();
//唤醒等待中的生产者线程
fullWaitSet.signal();
return first;
finally
//解锁
lock.unlock();
//阻塞添加
public void put(T task)
lock.lock();
try
//队列满了
while(deque.size()==capcity)
try
log.debug("等待加入任务队列 ...",task);
fullWaitSet.await();
catch (InterruptedException e)
e.printStackTrace();
//当前队列未满
log.debug("加入队列 ",task);
//加入队列尾部
deque.addLast(task);
//唤醒等待中的消费者线程
emptyWaitSet.signal();
finally
lock.unlock();
//带超时的阻塞添加
public boolean offer(T task,long timeout,TimeUnit timeUnit)
lock.lock();
try
long nanos = timeUnit.toNanos(timeout);
while(deque.size()==capcity)
if(nanos<=0)
return false;
log.debug("等待加入的任务队列 ...",task);
try
nanos = fullWaitSet.awaitNanos(nanos);
catch (InterruptedException e)
e.printStackTrace();
log.debug("加入任务队列 ",task);
deque.addLast(task);
emptyWaitSet.signal();
return true;
finally
lock.unlock();
public int size()
lock.lock();
try
return deque.size();
finally
lock.unlock();
public void tryPut(RejectPolicy<T> rejectPolicy,T task)
lock.lock();
try
//判断队列是否满了
if(deque.size()==capcity)
//采用指定的拒绝策略
rejectPolicy.reject(this,task);
else
//有空闲
log.debug("加入任务队列 ",task);
deque.addLast(task);
emptyWaitSet.signal();
finally
lock.unlock();
步骤3:自定义线程池
package Pool;
import lombok.extern.slf4j.Slf4j;
import java.util.HashSet;
import java.util.concurrent.TimeUnit;
//线程池
@Slf4j
public class ThreadPool
//任务队列
private BlockingQueue<Runnable> taskQueue;
//线程集合
private HashSet<Worker> workers=new HashSet<>();
//核心线程数
private int coreSize;
//获取任务的超时时间
private long timeout;
//超时时间单位
private TimeUnit timeUnit;
//拒绝策略
private RejectPolicy<Runnable> rejectPolicy;
//执行任务
public void execute(Runnable task)
//当任务数没有超过coreSize时,直接交给worker对象执行
//如果任务数超过coreSize时,加入任务队列暂存
if(workers.size()<coreSize)
Worker worker=new Worker(task);
log.debug("新增worker,",worker,task);
workers.add(worker);
worker.start();
else
// taskQueue.put(task);
// 1) 死等
// 2) 带超时等待
// 3) 让调用者放弃任务执行
// 4) 让调用者抛出异常
// 5) 让调用者自己执行任务
taskQueue.tryPut(rejectPolicy, task);
public ThreadPool(int coreSize, long timeout, TimeUnit timeUnit, int queueCapcity,
RejectPolicy<Runnable> rejectPolicy)
this.coreSize = coreSize;
this.timeout = timeout;
this.timeUnit = timeUnit;
this.taskQueue = new BlockingQueue<>(queueCapcity);
this.rejectPolicy = rejectPolicy;
public class Worker extends Thread
private Runnable task;
public Worker(Runnable task)
this.task = task;
@Override
public void run()
// 执行任务
// 1) 当 task 不为空,执行任务
// 2) 当 task 执行完毕,再接着从任务队列获取任务并执行
// while(task != null || (task = taskQueue.take()) != null)
while(task != null || (task = taskQueue.poll(timeout, timeUnit)) != null)
try
log.debug("正在执行...", task);
task.run();
catch (Exception e)
e.printStackTrace();
finally
task = null;
synchronized (workers)
log.debug("worker 被移除", this);
workers.remove(this);
步骤4:测试
package Pool;
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.TimeUnit;
@Slf4j
public class Test
public static void main(String[] args)
ThreadPool threadPool = new ThreadPool(1,
1000, TimeUnit.MILLISECONDS, 1, (queue, task)->
// 1. 死等
// queue.put(task);
// 2) 带超时等待
// queue.offer(task, 1500, TimeUnit.MILLISECONDS);
// 3) 让调用者放弃任务执行
// log.debug("放弃", task);
// 4) 让调用者抛出异常
// throw new RuntimeException("任务执行失败 " + task);
// 5) 让调用者自己执行任务
task.run();
);
for (int i = 0; i < 4; i++)
int j = i;
threadPool.execute(() ->
try
Thread.sleep(1000L);
catch (InterruptedException e)
e.printStackTrace();
log.debug("", j);
);
ThreadPoolExecutor
- 线程池状态
ThreadPoolExecutor 使用 int 的高 3 位来表示线程池状态,低 29 位表示线程数量
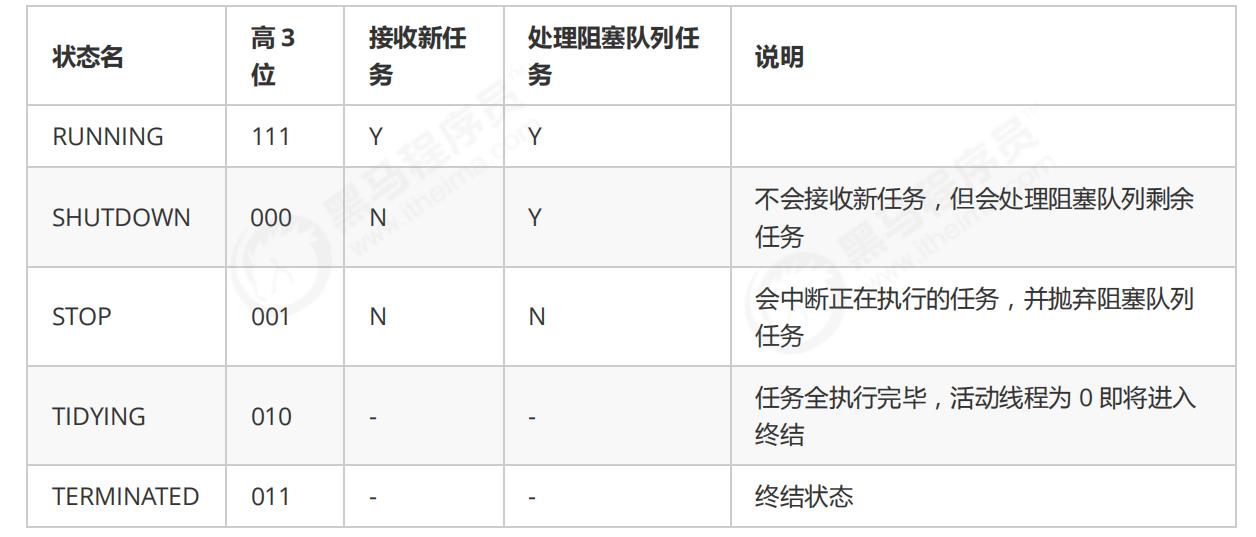
从数字上比较,TERMINATED > TIDYING > STOP > SHUTDOWN > RUNNING
最高位是符号位,1表示负数,0表示整数
这些信息存储在一个原子变量 ctl 中,目的是将线程池状态与线程个数合二为一,这样就可以用一次 cas 原子操作进行赋值
// c 为旧值, ctlOf 返回结果为新值
ctl.compareAndSet(c, ctlOf(targetState, workerCountOf(c))));
// rs 为高 3 位代表线程池状态, wc 为低 29 位代表线程个数,ctl 是合并它们
private static int ctlOf(int rs, int wc) return rs | wc;
- 构造方法
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
- corePoolSize 核心线程数目 (最多保留的线程数)
- maximumPoolSize 最大线程数目
- keepAliveTime 生存时间 - 针对救急线程
- unit 时间单位 - 针对救急线程
- workQueue 阻塞队列
- threadFactory 线程工厂 - 可以为线程创建时起个好名字
- handler 拒绝策略

工作方式:
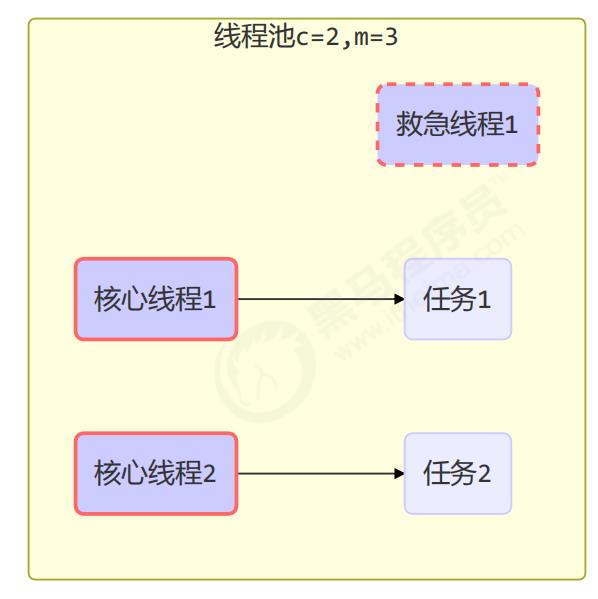

- 线程池中刚开始没有线程,当一个任务提交给线程池后,线程池会创建一个新线程来执行任务。
- 当线程数达到 corePoolSize 并没有线程空闲,这时再加入任务,新加的任务会被加入workQueue 队列排
队,直到有空闲的线程。 - 如果队列选择了有界队列,那么任务超过了队列大小时,会创建 maximumPoolSize - corePoolSize 数目的线
程来救急。 - 如果线程到达 maximumPoolSize 仍然有新任务这时会执行拒绝策略。拒绝策略 jdk 提供了 4 种实现,其它
著名框架也提供了实现 - AbortPolicy 让调用者抛出 RejectedExecutionException 异常,这是默认策略
- CallerRunsPolicy 让调用者运行任务
- DiscardPolicy 放弃本次任务
- DiscardOldestPolicy 放弃队列中最早的任务,本任务取而代之
- Dubbo 的实现,在抛出 RejectedExecutionException 异常之前会记录日志,并 dump 线程栈信息,方
便定位问题 - Netty 的实现,是创建一个新线程来执行任务
- ActiveMQ 的实现,带超时等待(60s)尝试放入队列,类似我们之前自定义的拒绝策略
- PinPoint 的实现,它使用了一个拒绝策略链,会逐一尝试策略链中每种拒绝策略
- 当高峰过去后,超过corePoolSize 的救急线程如果一段时间没有任务做,需要结束节省资源,这个时间由
keepAliveTime 和 unit 来控制

根据这个构造方法,JDK Executors 类中提供了众多工厂方法来创建各种用途的线程池
newFixedThreadPool----固定大小的线程池
public static ExecutorService newFixedThreadPool(int nThreads)
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
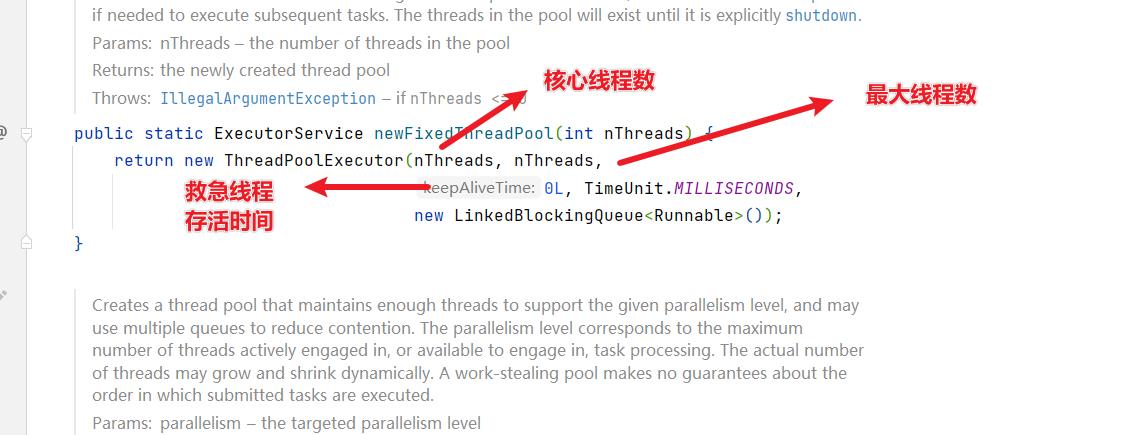
可以看到newFixedThreadPool底层还是通过ThreadPoolExecutor的构造参数传递不同参数实现
注意这里ThreadPoolExecutor返回的是线程池对象
特点
- 核心线程数 == 最大线程数(没有救急线程被创建),因此也无需超时时间
- 阻塞队列是无界的,可以放任意数量的任务
评价 适用于任务量已知,相对耗时的任务
package Pool;
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
@Slf4j
public class Test
public static void main(String[] args)
ExecutorService executorService = Executors.newFixedThreadPool(2);
executorService.execute(()->
log.debug("线程名称: ",Thread.currentThread().getName());
log.debug(以上是关于JUC学习之共享模型之工具上之线程池浅学的主要内容,如果未能解决你的问题,请参考以下文章