Android进阶知识——Android的消息机制
Posted ABded
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Android进阶知识——Android的消息机制相关的知识,希望对你有一定的参考价值。
文章目录
从开发的角度来说,Handler是android消息机制的上层接口,这使得在开发过程中只需要和Handler交互即可。Handler的使用过程很简单,通过它可以轻松地将一个任务切换到Handler所在的线程中去执行。
Android的消息机制主要是指Handler的运行机制,Handler的运行需要底层的MessageQueue和Looper的支撑。MessageQueue的中文翻译是消息队列,它的内部存储了一组消息,以队列的形式对外提供插入和删除的工作。虽然叫消息队列,但是它的内部存储结构并不是真正的队列,而是采用单链表的数据结构来存储消息列表。Looper的中文翻译为循环,在这里可以理解为消息循环。由于MessageQueue只是一个消息的存储单元,它不能去处理消息,而Looper就填补了这个功能,Looper会以无限循环的形式去查找是否有新消息,如果有的话就处理消息,否则就一直等待着。Looper中还有一个特殊的概念,那就是ThreadLocal,ThreadLocal并不是线程,它的作用是可以在每个线程中存储数据。我们知道,Handler创建的时候会采用当前线程的Looper来构造消息循环系统,那么Handler内部是如何获取当前线程的Looper呢?这就要使用ThreadLocal了,ThreadLocal可以在不同的线程中互不干扰地存储并提供数据,通过ThreadLocal可以轻松获取每个线程的Looper。当然需要注意的是,线程是默认没有Looper的,如果需要使用Handler就必须为线程创建Looper。我们经常提到的主线程,也叫UI线程,它就是ActivityThread,ActivityThread被创建时就会初始化Looper,这也就是在主线程中默认可以使用Handler的原因。
1.Android的消息机制概述
前面提到的,Android的消息机制主要是指Handler的运行机制以及Handler所附带的MessageQueue和Looper的工作过程,这三者实际上是一个整体,只不过我们在开发过程中比较多地接触到Handler而已。Handler的主要作用是将一个任务切换到某个指定的线程中去执行,那么Android为什么要提供这个功能呢?这是因为Android规定访问UI只能在主线程中进行,如果在子线程中访问UI,那么程序就会抛出异常。ViewRootImpl对UI操作做了验证,这个验证工作是由ViewRootImpl的checkThread方法来完成的,如下所示。
void checkThread()
if (mThread != Thread.currentThread())
throw new CalledFromWrongThreadException ("Only the original thread that created a view hierarchy can touch its views.") ;
由于上述代码的限制,导致必须在主线程中访问UI,但是Android又建议不要在主线程中进行耗时操作,否则会导致程序无法响应即ANR。考虑一种情况,假如我们需要从服务端拉取一些信息并将其显示在UI上,这个时候必须在子线程中进行拉取工作,拉取完毕后又不能在子线程中直接访问UI,如果没有Handler,那么我们的确没有办法将访问UI的工作切换到主线程中去执行。因此,系统之所以提供Handler,主要原因就是为了解决在子线程中无法访问UI的矛盾。
这里要延伸一点,系统为什么不允许在子线程中访问UI呢?这是因为Android的UI控件不是线程安全的,如果在多线程中并发访问可能会导致UI控件处于不可预期的状态,那为什么系统不对UI控件的访问加上锁机制呢?缺点有两个:首先加上锁机制会让UI访问的逻辑变得复杂;其次锁机制会降低UI访问的效率,因为锁机制会阻塞某些线程的执行。鉴于这两个缺点,最简单且高效的方法就是采用单线程模型来处理UI操作,对于开发者来说也不是很麻烦,知识需要通过Handler切换一下UI访问的执行线程即可。(原因:1.使得访问UI的逻辑变的更复杂;2.降低UI的访问效率)
Handler的使用方法这里就不做介绍了,这里描述一下Handler的工作原理。Handler创建时会采用当前线程的Looper来构建内部的消息循环系统,如果当前线程没有Looper,那么就会报错。那么该如何解决这个问题呢?其实也简单,只需要为当前线程创建Looper即可,或者在一个有Looper的线程中创建Handler也行。
Handler创建完毕后,这个时候其内部的Looper以及MessageQueue就可以和Handler一起协同工作了,然后通过Handler的post方法将一个Runnable投递到Handler内部的Looper中去处理,也可以通过Handler的send方法来发送一个消息,这个消息同样会在Looper中去处理。其实post方法最终也是通过send方法来完成的,接下来主要来看一下send方法的工作过程。当Handler的send方法被调用时,它会调用MessageQueue的enqueueMessage方法来将这个消息放入消息队列中,然后Looper发现有新消息到来时,就会处理这个消息,最终消息中的Runnable或者Handler的handleMessage方法就会被调用。注意Looper运行在创建Handler所在的线程中,这样一来Handler中的业务逻辑就被切换到创建Handler所在的线程中去执行了,这个过程可以用下图来表示:
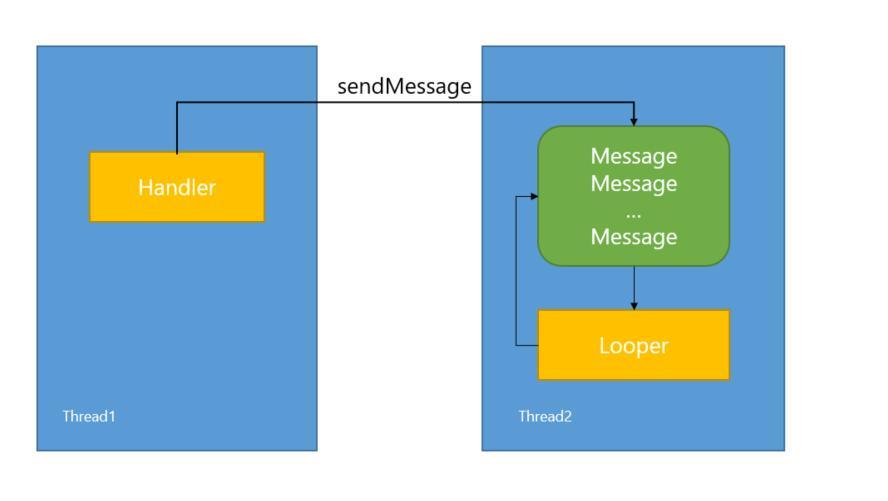
2.Android的消息机制分析
由于Android的消息机制实际上就是Handler的运行机制,因此本节主要围绕着Handler的工作过程来分析Android的消息机制,主要包括Handler、MessageQueue和Looper。同时为了更好地理解Looper的工作原理,本节还会介绍ThreadLocal,通过本节的介绍可以让读者对Android的消息机制有一个深入的理解。
2.1ThreadLocal的工作原理
ThreadLocal是一个线程内部的数据存储类,通过它可以在指定的线程中存储数据,数据存储以后,只有在指定线程中可以获取到存储的数据,对于其他线程来说则无法获取到数据。一般来说,当某些数据是以线程为作用域并且不同线程具有不同的数据副本的时候,就可以考虑采用ThreadLocal·。比如对于Handler来说,它需要获取当前线程的Looper,很显然Looper的作用域就是线程并且不同线程具有不同的Looper,这个时候通过ThreadLocal就可以轻松实现Looper在线程中的存取。如果不采用ThreadLocal,那么系统就必须提供一个全局的哈希表供Handler查找指定线程的Looper,这样一来就必须提供一个类似于LooperManager的类了,但是系统并没有这么做而是选择了ThreadLocal,这就是ThreadLocal的好处。(Manager类是用来在全局中存储或获取数据的一种类)
ThreadLocal另一种使用场景是复杂逻辑下的对象传递,比如监听器的传递,有些时候一个线程中的任务过于复杂,这可能表现为函数调用栈比较深以及代码入口的多样性,在这种情况下,我们又需要监听器能够贯穿整个线程的执行过程,这个时候我们就可以采用ThreadLocal,采用ThreadLocal可以让监听器作为线程内的全局对象而存在,在线程内部只要通过get方法就可以获取到监听器。如果不采用ThreadLocal,那么我们能想到的可能是如下两种方法:第一种方法是将监听器通过参数的形式在函数调用栈中进行传递;第二种方法就是·将监听器作为静态变量供线程访问。上述两种方法都是有局限性的。第一种方法的问题是当函数调用栈很深的时候,通过函数参数来传递检监听器对象这几乎是不可接受的,这会让程序的设计看起来很槽糕。第二种方法是可以接受的,但是这种状态是不具有可扩充性的,比如同时有两个线程在执行,那么就需要提供两个静态的监听器对象,如果有10个线程在并发执行呢?提供10个静态的监听器对象?这显然是不可思议的,而采用ThreadLocal,每个监听器对象都在自己的线程内部存储,根本就不会有方法2的这种问题。
介绍了那么多ThreadLocal的知识,可能还是有点抽象,下面通过实际的例子来演示ThreadLocal的真正含义。首先定义一个ThreadLocal对象,这里选择Boolean类型,如下所示。
private ThreadLocal<Boolean> mBooleanThreadLocal = new ThreadLocal<Boolean>();
然后分别在主线程,子线程1和子线程2中设置和访问它的值,代码如下所示。
mBooleanThreadLocal.set(true);
Log.d (TAG, "[Thread#ma in] mBooleanThreadLocal=" + mBooleanThreadLocal.get());
new Thread("Thread#1")
@Override
public void run()
mBooleanThreadLocal.set(false) ;
Log.d (TAG,"[Thread#1]mBooleanThreadLocal=" + mBooleanThreadLocal.
get());
;
.start() ;
new Thread ("Thread#2")
@Override
public void run ()
Log.d (TAG, " [Thread#2] mBooleanThreadLocal=" + mBooleanThreadLocal .
get()) ;
;
.start();
在上面的代码中,在主线程中设置mBooleanThreadLocal的值为true,在子线程1中设置mBooleanThreadLocal的值为false,在子线程2中不设置mBooleanThreadLocal的值。然后分别在3个线程中通过get方法获取mBooleanThreadLocal的值,根据前面对ThreadLocal的描述,这个时候,主线程中应该为true,在线程1中应该为false,而子线程2中由于没有设置值,所以应该是null。程序运行结果如下:
D/TestActivity(8676) : [Thread#main]mBooleanThreadLocal=true
D/TestActivity(8676) : [Thread#1]mBooleanThreadLocal=false
D/TestActivity(8676) : [Thread#2]mBooleanThreadLocal=null
从上面的日志可以看出,虽然在不同线程中访问的是同一个ThreadLocal对象,但是它们通过ThreadLocal获取的值却是不一样的,这就是ThreadLocal的奇妙之处。ThreadLocal之所以有这么奇妙的效果,是因为不同线程访问同一个ThreadLocal的get方法,ThreadLocal内部会从各自的线程中取出一个数组,然后再从数组中根据当前ThreadLocal的索引去查找对应的value值。很显然,不同线程中的数组是不同的,这就是为什么通过ThreadLocal可以在不同线程中维护一套数据的副本并且彼此互不干扰。
对ThreadLocal的使用方法和工作过程做了介绍后,下面分析ThreadLocal的内部实现,ThreadLocal是一个泛型类,它的定义为public class ThreadLocal,只需要弄清楚ThreadLocal的get和set方法就可以明白它的工作原理。
首先看ThreadLocal的set方法,如下所示:
public void set(T value)
Thread currentThread = Thread.currentThread();
Values values = values(currentThread);
if (values == null)
values = initializeValues(currentThread);
values.put(this, value);
在上面的set方法中,首先会通过values方法来获取当前线程中的ThreadLocal数据,如何获取呢?在Thread类的内部有一个成员专门用于存储线程的ThreadLocal的数据:ThreadLocal .Values localValues,因此获取当前线程的ThreadLocal数据就变得异常简单了。如果localValues的值为null,那么就需要对其进行初始化,初始化后再将ThreadLocal的值进行存储。下面看一下ThreadLocal的值到底是如何在localValues中进行存储的。在localValues内部有一个数组:private Object[] table,ThreadLocal的值就存在这个table数组中。下面看一下localValues是如何使用put方法将ThreadLocal的值存储到table数组中的,如下所示:
void put(ThreadLocal<?> key, Object value)
cleanUp() ;
int firstTombstone - -1 ;
for (int index= key.hash & mask;; index = next (index))
Object k = table[index];
if (k == key.reference)
table[index + 1] = value;
return;
if (k == nul1) (
if (firstTombstone == -1)
table[index] = key.reference;
table[index + 1] = value;
size++;
return;
table[firstTombstone] = key.reference;
table[firstTombstone + 1] = value;
tombstones-- ;
size++;
return;
if (firstTombstone == -1 && k == TOMBSTONE)
firstTombstone = index;
从上述的代码中我们可以得出一个存储规则,那就是ThreadLocal的值在table数组中的存储位置总是为ThreadLocal的reference字段所标识的对象的下一个位置,比如ThreadLocal的reference对象在table数组中的索引为index,那么ThreadLocal的值在table数组中的索引就是index+1。最终ThreadLocal的值将会被存储在table数组中:table[index + 1]=value。
接下来我们来分析ThreadLocal的get方法,如下所示:
public T get()
Thread currentThread = Thread.currentThread();
Values values = values(currentThread);
if (values != null)
Object[] table = values.table;
int index = hash & values.mask;
if (this.reference == table[index])
return (T) table[index + 1];
else
values = initializevalues(currentThread);
return (T) values.getAfterMiss(this);
ThreadLocal的get方法,它同样是取出当前线程的localValues对象,如果这个对象为null那么就返回初始值,初始值由ThreadLocal的initialValue方法来描述,默认情况下为null,当然你也可以重写这个方法,它的默认实现如下所示:
protected T initialValue()
return null;
如果localValues对象不为null,那就取出它的table数组并找出ThreadLocal的reference对象在table数组中的位置,然后table数组中的下一个位置所存储的数据就是ThreadLocal的值。
从ThreadLocal的set和get方法可以看出,它们所操作的对象都是当前线程的localValues对象的table数组,因此在不同线程中访问同一个ThreadLocal的set和get方法,它们对ThreadLocal所做的读/写操作仅限于各自线程的内部,这就是为什么ThreadLocal可以在多个线程中互不干扰地存储和修改数据,理解ThreadLocal的实现方式有助于理解Looper的工作原理。
2.2消息队列的工作原理
消息队列在Android中指的是MessageQueue,MessageQueue主要包含两个操作:插入和读取。读取操作本身会伴随着删除操作,插入和读取对应的方法分别为enqueueMessage和next,其中enqueueMessage的作用是往消息队列中插入一条消息,而next的作用是从消息队列中取出一条消息并将其从消息队列中移除。尽管MessageQueue叫消息队列,但是它的内部实现并不是用的队列,实际上它是通过一个单链表的数据结构来维护消息列表,单链表在插入和删除上比较有优势。下面主要看一下它的enqueueMessage和next方法的实现,enqueueMessage的源码如下所示:
boolean engueueMessage (Message msg, long when)
...
synchronized (this)
...
msg.markInUse();
msg.when = when;
Message p = mMessages;
boolean needWake;
if(p == null || when == 0 || when < p.when)
msg.next = p;
mMessages = msg:
needWake = mBlocked;
else
needWake = mBlocked && p.target == null && msg.isAsynchronous();
Message prev;
for (;;)
prev = p;
P = p.next;
if (p == null || when < p.when)
break;
if (needWake && p.isAsynchronous())
needWake = false;
msg.next = P; // invariant: p == prev.next
prev.next = msg;
if (needWake)
nativeWake(mPtr);
return true;
从enqueueMessage的实现来看,它的主要操作其实就是单链表的插入操作,这里就不再过多解释了,下面看一下next方法的实现,next的主要逻辑如下所示:
Message next()
int pendingIdleHandlerCount = -1;
int nextPollTimeoutMillis = 0;
for(;;)
if (nextPollTimeoutMillis != 0)
Binder.flushPendingCommands();
nativePollOnce(ptr, nextPollTimeoutMillis);
synchronized (this)
final long now = SystemClock.uptimeMillis();
Message prevMsg = null;
Message msg = mMessages;
if (msg != null && msg.target == null)
do
prevMsg = msg;
msg = msg.next;
while (msg != null && !msg.isAsynchronous());
if (msg !- null)
if(now<msg.when)
nextPollTimeoutMillis = (int) Math.min (msg.when一now,
Integer .MAX VALUE) ;
else
mBlocked = false;
if (prevMsg !=null)
prevMsg.next = msg.next;
else
mMessages = msg.next;
msg.next = null;
if (false) Log.v ("MessageQueue", "Returning message:" + msg);
return msg;
else
nextPollTimeoutMillis = -1;
...
...
可以发现next方法是一个无限循环的方法,如果消息队列中没有消息,那么next方法会一直阻塞在这里。当有新消息到来时,next方法会返回这条消息并将其从单链表中移除。
2.3Looper的工作原理
Looper在Android的消息机制中扮演着消息循环的角色,具体来说就是它会不停地从MessageQueue中查看是否有新消息,如果有新消息就会立刻处理,否则就一直阻塞在那里。首先看一下它的构造方法,在构造方法中它会创建一个MessageQueue即消息队列,然后将当前线程的对象保存起来,如下所示:
private Looper(boolean quitAllowed)
mQueue = new MessageQueue(quitAllowed);
mThread = Thread.currentThread();
我们知道,Handler的工作需要Looper,没有Looper的线程就会报错,那么如何为一个线程创建Looper呢?其实很简单,通过Looper.prepare()即可为当前线程创建一个Looper,接着通过Looper.loop()来开启消息循环,如下所示:
new Thread("Thread#2")
@Override
public void run()
Looper.prepare();
Handler handler = new Handler();
Looper.loop();
;
.start () ;
Looper除了prepare方法外,还提供了prepareMainLooper方法,这个方法主要是给主线程也就是ActivityThread创建Looper使用的,其本质也是通过prepare方法来实现的。由于主线程的Looper比较特殊,所以Looper提供了一个getMainLooper方法,通过它可以在任何地方获取到主线程的Looper。Looper也是可以退出的,Looper提供了quit和quitSafely来退出一个Looper,二者的区别是:quit会直接退出Looper,而quitSafely只是设定一个退出标记,然后把消息队列中的已有消息处理完毕后才安全地退出。Looper退出后,通过Handler发送的消息会失败,这个时候Handler的send方法会返回false。在子线程中,如果手动为其创建了Looper,那么在所有的事情完成以后应该立即调用quit方法来终止循环,否则这个子线程就会一直处于等待的状态,而如果退出Looper以后,这个线程就会立刻终止,因此建议在不需要的时候终止Looper。
Looper最重要的一个方法是loop方法,只有调用了loop后,消息循环系统才会真正地起作用,它的实现如下所示:
public static void loop()
final Looper me = myLooper();
if (me == null)
throw new RuntimeException("No Looper; Looper.prepare() wasn't called on this thread.");
final MessageQueue queue = me.mQueue;
Binder.clearCallingIdentity();
final long ident = Binder.clearCallingIdentity();
for (;;)
Message msg = queue.next();
if (msg == nul1)
return;
Printer logging = me.mLogging;
if (logging!= null)
logging.print1n(">>>>> Dispatching to" + msg.target + " " + msg.callback + ":" + msg.what);
msg.target.dispatchMessage(msg);
if (logging != null)
logging.println("<<<<< Finished to " + msg.target + " " + msg.callback);
final long newIdent = Binder.clearCallingIdentity();
if (ident != newIdent)
Log.wtf(TAG, "Thread identity changed from 0x"
+ Long.toHexString(ident) + "to 0x"
+ Long.toHexString(newIdent) + "while dispatching to"
+ msg.target.getClass().getName() + " "
+ msg.callback + " what=" + msg.what);
msg. recycleUnchecked() ;
Looper的loop方法的工作过程也比较好理解,loop方法是一个死循环,唯一跳出循环的方式是MessageQueue的next返回了null。当Looper的quit方法被调用时,Looper就会调用MessageQueue的quit或者quitSafely方法来通知消息队列退出,当消息队列被标记位退出状态时,它的next方法就会返回null。也就是说,Looper必须退出,否则loop方法就会无限循环下去。loop方法会调用MessageQueue的next方法来获取新消息,而next是一个阻塞操作,当没有消息时,next方法会一直阻塞在那里,这也导致loop方法一直阻塞在那里。如果MessageQueue的next方法返回了新消息,Looper就会处理这条消息:msg.target.dispatchMessage(msg),这里的msg.target是发送这条消息的Handler对象,这样Handler发送的消息最终又交给它的dispatchMessage方法来处理了。但是这里不同的是,Handler的dispatchMessage方法是在创建Handler时所使用的Looper中执行的,这样就成功地将代码逻辑切换到指定的线程中去执行了。
2.4Handler的工作原理
Handler的工作原理包含消息的发送和接收过程。消息的发送可以通过post的一系列方法以及send的一系列方法来实现,post的一系列方法最终是通过send的一系列方法来实现的。发送一条消息的典型流程如下所示:
public final boolean sendMessage(Message msg)
return sendMessageDelayed(msg, 0);
public final boolean sendMessageDelayed(Message msg, long delayMi1lis)
if (delayMillis < 0)
delayMillis = 0;
return sendMessageAtTime(msg, SystemClock.uptimeMillis() + delayMillis) ;
public boolean sendMessageAtTime(Message msg, long uptimeMillis)
MessageQueue queue = mQueue;
if (queue == null)
RuntimeException e = new Runt imeException (this +"sendMessageAtTime() called with no mQueue");
Log.w("Looper", e.getMessage(), e);
return false;
return enqueueMessage(queue, msg, uptimeMillis);
private boolean enqueueMessage(MessageQueue queue, Message msg, long uptimeMillis)
msg.target = this;
if (mAsynchronous)
msg.setAsynchronous(true);
return queue.enqueueMessage(msg, uptimeMillis);
Handler发送消息的过程仅仅是向消息队列中插入了一条信息,MessageQueue的next方法就会返回这条消息给Looper,Looper收到消息后就开始处理了,最终消息由Looper交由Hadnler处理,即Handler的dispatchMessage方法就会被调用,这时Handler就进入了处理消息的阶段。dispatchMessage的实现如下:
public void dispatchMessage(Message msg)
if (msg.callback != null)
handleCallback(msg);
else
if (mCallback != null)
if (mCallback.handleMessage(msg))
return;
handleMessage(msg);
Handler处理消息的过程如下:首先,检查Message的callback是否为null,不为null就通过handleCallback来处理消息。Message的callback是一个Runnable对象,实际上就是Handler的post方法所传递的Runnable参数。handleCallback的逻辑也很简单,如下所示:
private static void handleCallback(Message message)
message.callback以上是关于Android进阶知识——Android的消息机制的主要内容,如果未能解决你的问题,请参考以下文章