AI实现语音文字处理,PaddleSpeech项目安装使用 | 机器学习
Posted 剑客阿良_ALiang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了AI实现语音文字处理,PaddleSpeech项目安装使用 | 机器学习相关的知识,希望对你有一定的参考价值。
目录
前言
这段时间一直在研究飞浆平台,最近试了试PaddleSpeech项目,试着对文本语音做处理。整体的效果个人觉着不算特别优越,只能作为简单的学习使用。
项目github地址:github仓库
环境安装
首先我们看一下项目结构以及安装文档。
需要Python3.7以上、C++环境、requirements安装等等,下面按照我的顺序说一下。
1、conda安装Python3.9虚拟环境
使用conda安装python3.9环境,命令如下。
conda create -n py39 python=3.9
2、安装Visual Studio 2019
安装地址: Microsoft C++ 生成工具 - Visual Studio
注意安装的时候需要勾选C++桌面开发。
3、安装requirements.txt
使用命令安装requiremets.txt,命令如下:
pip install -r requirements.txt -i https://pypi.douban.com/simple
这里要注意一下,paddlespeech_ctcdecoders安装失败的话无所谓,可以略掉。
4、安装paddlepaddle和paddlespeech
命令如下:
pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple pip install paddlespeech -i https://pypi.tuna.tsinghua.edu.cn/simple
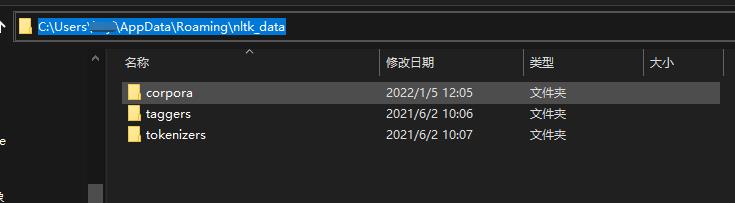
5、nltk_data下载
按照项目安装文档内的说明。

我的本地目录地址如下
项目验证
我下面分别验证一下tts、asr以及标点恢复功能。
tts语音合成
使用命令如下:
paddlespeech tts --input "南京现在很冷,下次再去夫子庙吧。" --output C:\\Users\\xxx\\Desktop\\115.wav
执行过程
(dh_partner) D:\\spyder\\PaddleSpeech>paddlespeech tts --input "南京现在很冷,下次再去夫子庙吧。" --output C:\\Users\\xxx\\Desktop\\115.wav
phones_dict: None
[2022-01-05 17:23:43,642] [ INFO] [log.py] [L57] - File C:\\Users\\huyi\\.paddlespeech\\models\\fastspeech2_csmsc-zh\\fastspeech2_nosil_baker_ckpt_0.4.zip md5 checking...
[2022-01-05 17:23:44,742] [ INFO] [log.py] [L57] - Use pretrained model stored in: C:\\Users\\huyi\\.paddlespeech\\models\\fastspeech2_csmsc-zh\\fastspeech2_nosil_baker_ckpt_0.4
self.phones_dict: C:\\Users\\huyi\\.paddlespeech\\models\\fastspeech2_csmsc-zh\\fastspeech2_nosil_baker_ckpt_0.4\\phone_id_map.txt
[2022-01-05 17:23:44,743] [ INFO] [log.py] [L57] - C:\\Users\\huyi\\.paddlespeech\\models\\fastspeech2_csmsc-zh\\fastspeech2_nosil_baker_ckpt_0.4
[2022-01-05 17:23:44,744] [ INFO] [log.py] [L57] - C:\\Users\\huyi\\.paddlespeech\\models\\fastspeech2_csmsc-zh\\fastspeech2_nosil_baker_ckpt_0.4\\default.yaml
[2022-01-05 17:23:44,744] [ INFO] [log.py] [L57] - C:\\Users\\huyi\\.paddlespeech\\models\\fastspeech2_csmsc-zh\\fastspeech2_nosil_baker_ckpt_0.4\\snapshot_iter_76000.pdz
self.phones_dict: C:\\Users\\huyi\\.paddlespeech\\models\\fastspeech2_csmsc-zh\\fastspeech2_nosil_baker_ckpt_0.4\\phone_id_map.txt
[2022-01-05 17:23:44,745] [ INFO] [log.py] [L57] - File C:\\Users\\huyi\\.paddlespeech\\models\\pwgan_csmsc-zh\\pwg_baker_ckpt_0.4.zip md5 checking...
[2022-01-05 17:23:44,782] [ INFO] [log.py] [L57] - Use pretrained model stored in: C:\\Users\\huyi\\.paddlespeech\\models\\pwgan_csmsc-zh\\pwg_baker_ckpt_0.4
[2022-01-05 17:23:44,783] [ INFO] [log.py] [L57] - C:\\Users\\huyi\\.paddlespeech\\models\\pwgan_csmsc-zh\\pwg_baker_ckpt_0.4
[2022-01-05 17:23:44,783] [ INFO] [log.py] [L57] - C:\\Users\\huyi\\.paddlespeech\\models\\pwgan_csmsc-zh\\pwg_baker_ckpt_0.4\\pwg_default.yaml
[2022-01-05 17:23:44,785] [ INFO] [log.py] [L57] - C:\\Users\\huyi\\.paddlespeech\\models\\pwgan_csmsc-zh\\pwg_baker_ckpt_0.4\\pwg_snapshot_iter_400000.pdz
vocab_size: 268
frontend done!
encoder_type is transformer
decoder_type is transformer
C:\\Users\\huyi\\.conda\\envs\\dh_partner\\lib\\site-packages\\paddle\\framework\\io.py:415: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' i
s deprecated since Python 3.3, and in 3.10 it will stop working
if isinstance(obj, collections.Iterable) and not isinstance(obj, (
acoustic model done!
voc done!
Building prefix dict from the default dictionary ...
[2022-01-05 17:23:51] [DEBUG] [__init__.py:113] Building prefix dict from the default dictionary ...
Loading model from cache C:\\Users\\huyi\\AppData\\Local\\Temp\\jieba.cache
[2022-01-05 17:23:51] [DEBUG] [__init__.py:132] Loading model from cache C:\\Users\\huyi\\AppData\\Local\\Temp\\jieba.cache
Loading model cost 0.659 seconds.
[2022-01-05 17:23:52] [DEBUG] [__init__.py:164] Loading model cost 0.659 seconds.
Prefix dict has been built successfully.
[2022-01-05 17:23:52] [DEBUG] [__init__.py:166] Prefix dict has been built successfully.
C:\\Users\\huyi\\.conda\\envs\\dh_partner\\lib\\site-packages\\paddle\\fluid\\dygraph\\math_op_patch.py:251: UserWarning: The dtype of left and right variables are not the same, left dtype is padd
le.int64, but right dtype is paddle.int32, the right dtype will convert to paddle.int64
warnings.warn(
[2022-01-05 17:23:58,811] [ INFO] [log.py] [L57] - Wave file has been generated: C:\\Users\\xxx\\Desktop\\115.wav
生成的音频如下
asr语音识别
我就使用了tts生成的音频进行asr识别,看看效果,命令如下:
paddlespeech asr --lang zh --input C:\\Users\\xxx\\Desktop\\115.wav
执行结果如下

可以看到最后打印的内容是没有标点的文字输出,还是比较准的。
标点恢复
就用这句话试试标点恢复的情况,命令如下:
paddlespeech text --task punc --input 南京现在很冷下次再去夫子庙吧
执行结果
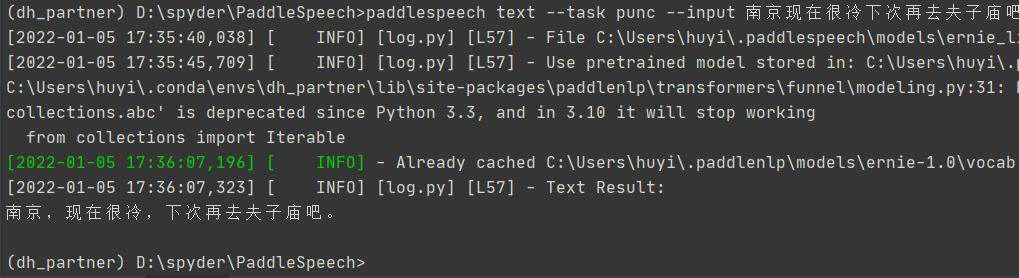
看起来语义上没什么问题。
总结
我在前言中说效果不是很好的主要原因是因为速率比较慢,相比于类似阿里云提供的tts、asr接口来说,效率比较低。也可能和需要校验模型是否存在这些无关紧要的功能有关。可以考虑研究代码,自己重新封装一些服务,效果应该好的多。
还有补充一下,最近博主在参加评选博客之星活动。如果你喜欢我的文章的话,不妨给我点个五星,投投票吧,谢谢大家的支持!!链接地址:https://bbs.csdn.net/topics/603956455
分享:
世界不会在意你的自尊,人们看到的只是你的成就。在你没有成就以前,切勿过分强调自尊。——《了不起的盖茨比》
如果本文对你有用的话,点个赞吧,谢谢!!!

以上是关于AI实现语音文字处理,PaddleSpeech项目安装使用 | 机器学习的主要内容,如果未能解决你的问题,请参考以下文章