2021年前端部署的灵魂拷问
Posted 前端开发博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2021年前端部署的灵魂拷问相关的知识,希望对你有一定的参考价值。
大家好,在过去的一年中,前端部署你遇到过哪些问题,一起来看看这篇文章吧。喜欢记得关注我并设为星标。
先上灵魂拷问
在文章之前,先抛一些灵魂拷问:
前端代码从 tsx/jsx 到部署上线被用户访问,中间大致会经历哪些过程?
上述过程中分别都有哪些考虑、指标和优化点,以满足复杂的业务需求?
可能大部分同学都知道强缓存/协商缓存,那前端各种产物(html、JS、CSS、IMAGES 等)应该用什么缓存策略?以及为什么?
若使用协商缓存,但静态资源却不频繁更新,如何避免协商过程的请求浪费?
若使用强缓存,那静态资源如何更新?
配套的,前端静态资源应该如何组织?
配套的,自动化构建 & 部署过程如何与 CDN 结合?
如何避免前端上线,影响未刷新页面的用户?
刚上线的版本发现有阻塞性 bug,如何做到秒级回滚,而非再次部署等 20 分钟甚至更久?
如何实现一个预发环境,除了前端资源外都是线上环境,将变量控制前端环境内?
部署环节如何方便配套做 AB 测试等?
如何实现一套前端代码,发布成多套环境产物?
如何实现按 feature 发布产物供用户使用,并逐步扩大 feature 灰度,将影响减到最小(即线上同时存在多 feature 产物)?
CDN 域名突然挂了,如何实现秒级 CDN 降级修补而非再次全部业务重新部署一次?
本文将会带着这些问题,试着一起探索在2021年,系统化的前端部署解决方案。
PS:本篇关于静态资源组织的问题&思路等,借鉴自知乎大佬张云龙这篇回答 大公司里怎样开发和部署前端代码
静态资源组织
一个简单的页面 前端开发博客
先从简单的静态页面开始,众所周知,前端资源由 HTML、javascript、CSS 三剑客组成,假设我们有一个简单的页面,用nginx作为 Web 服务器,资源组织结构大概如下:
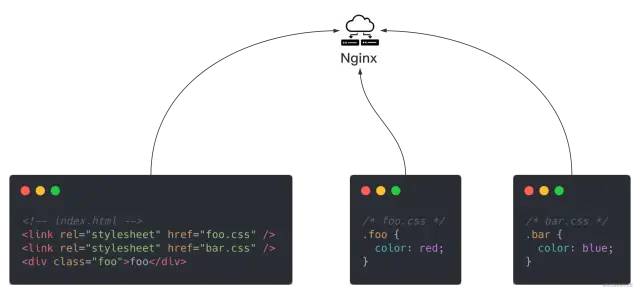
此时, 只需将 HTML、JavaScript、CSS 等静态资源通过 FTP 等软件,上传到 Web 服务器(如 Nginx)某目录,将 Nginx 启动做简单配置即可让用户访问。
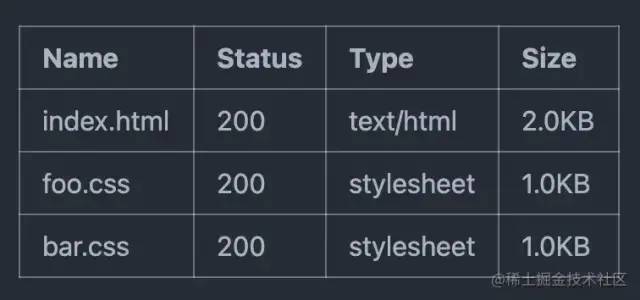
用户一访问,状态 200,页面渲染出来,前端十分简单,对不对?
利用缓存 前端开发博客
但仔细观察,用户每次访问都会请求 foo.css, bar.css 等静态文件,即使该文件并无变更。对带宽甚是浪费,对页面首屏性能等也有影响。于是在网络带宽紧张的互联网早期,计算机先贤们在 HTTP 协议上制定了多种缓存策略。
浏览器缓存:浏览器缓存(
Brower Caching)是浏览器对之前请求过的文件进行缓存,以便下一次访问时重复使用,节省带宽,提高访问速度,降低服务器压力。
协商缓存
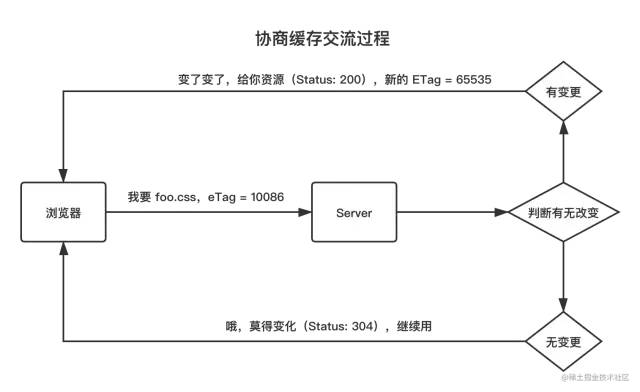
一种策略是浏览器先问问服务器有没有变化,没变化就用旧资源。毕竟"问一问"的通信成本,远小于每次重新加载资源的成本。大致流程如下:
协商缓存: 向服务器发送请求,服务器会根据这个请求的
Request Header的一些参数来判断是否命中协商缓存,如果命中,则返回304状态码并带上新的Response Header通知浏览器从缓存中读取资源;
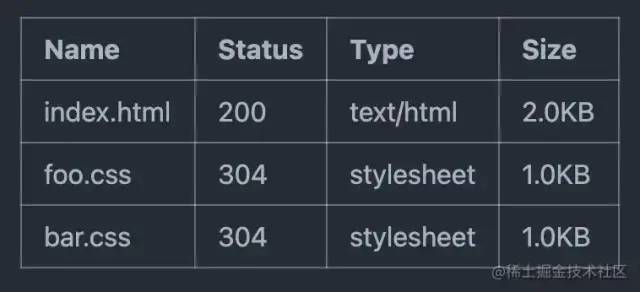
此时,使用协商缓存后,Network 大致变成了这样:
注:协商缓存一般可在服务端通过设置
Last-Modifed、ETag等ResponseHeader实现。
注:304状态码,表示资源未发生变更,可使用浏览器缓存。
强缓存
这样,通过协商缓存,我们大幅优化了资源未变更时的网络请求,节约大量带宽,网站首屏性能也有不错的提升,美滋滋!
然而仔细观察,发现仍然有协商的过程,一百个静态文件就有一百个协商请求。在资源未发生变更时,追求极致的我们也应该优化掉这个协商请求,毕竟没有买卖就没有伤害!
和协商缓存对应的是使用强缓存,大概过程如下:
强缓存:浏览器不会向服务器发送任何请求,直接从本地缓存中读取文件并返回
Status Code: 200 OK。
此时,强缓存的大致对话过程如图:
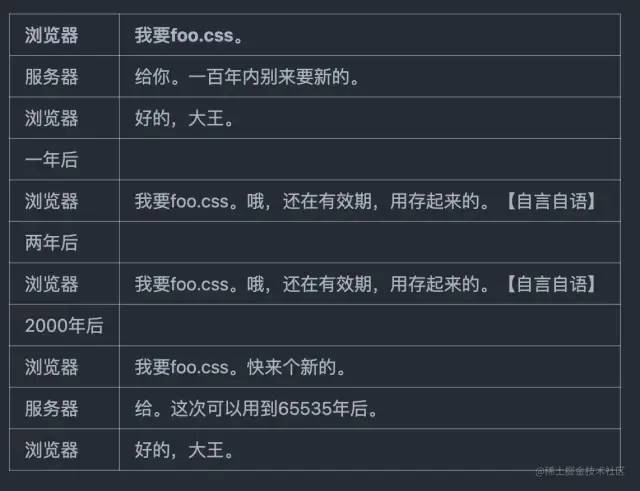
注意,缓存生效期间,浏览器是【自言自语】,和服务器无关。
此时,设置强缓存后,Network 大致变成了这样:
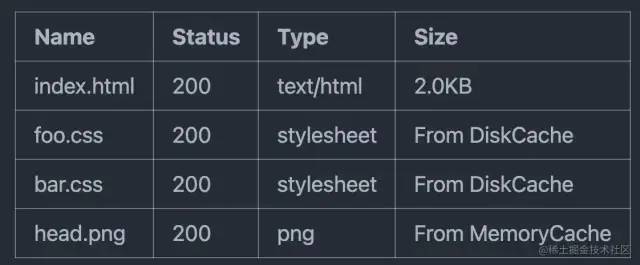
From DiskCache:从硬盘中读取。From MemoryCache:从内存中读取,速度最快。
注:强缓存一般可在服务端通过设置Cache-Control:max-age、Expires等ResponseHeader实现。
用上强缓存后,协商的请求也被消灭了,网站加载的性能达到极致了。美滋滋!
附录:协商缓存和强缓存详解
强缓存/协商缓存详解[1]
注:校招生或客户端转前端同学,关于强缓存/协商缓存的实现及使用先了解即可。
后续再熟练掌握。
关于缓存还可以看看:前端缓存最佳实践
缓存更新问题 前端开发博客
鉴于页面(index.html)会频繁更新,而静态资源则相对稳定。所以,我们能推断出的一种缓存策略是 index.html 适合走协商缓存,相对稳定 & 不常更新的静态资源(JS、CSS、IMAGES) 等应该消灭协商请求,使用强缓存。
然而问题很快就来了,都不让浏览器发请求,但缓存还未到期我们发现有 bug,想更新 foo.css 怎么办?
又想设置尽量长的时间走缓存,又想要能随时更新?
又想马儿跑又不给马儿吃草?
 相信大家很快就能得出一种思路,给资源加版本号!比如通过
相信大家很快就能得出一种思路,给资源加版本号!比如通过 query 加版本号,每次上线统一改版本号就搞定了。此时 HTML 变成如图:
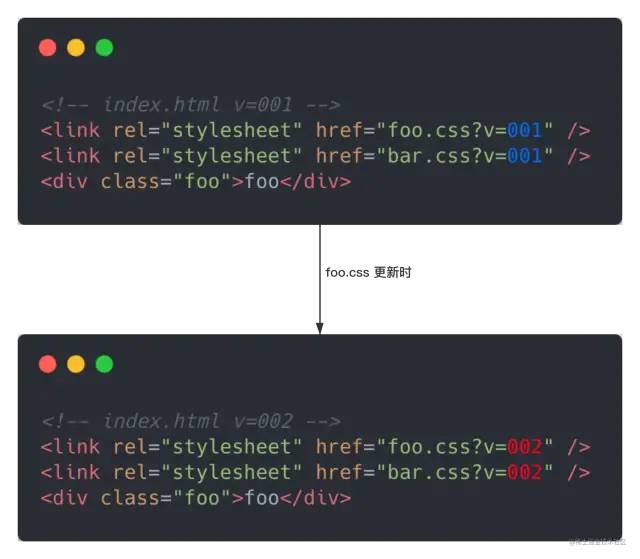
注意,此时服务器内只有一份文件
foo.css文件。
统一加版本号的优点是简单粗暴快捷,但缺点则是:假如我们只想更新 foo.css,但 bar.css 缓存也失效了,又造成了带宽的浪费。
大家应该很快就能想到办法,需要将文件内容与版本号(URL)绑定,当文件内容发生变更时才变更版本号(URL),这样就能实现每个文件精确的缓存控制。
什么东西与文件内容相关呢?消息摘要算法[2] ,对文件求摘要信息,摘要信息与文件内容一一对应,就有了一种可以精确到单个文件粒度的缓存控制依据。现在,我们把 URL 改成带文件摘要信息的:
 我们可以称这种这个方式为
我们可以称这种这个方式为 query-hash,后续发版上线时,只有被变更文件的 URL 会更新,实现了精确的缓存控制,完美!
注意,此时服务器内只有一份文件
foo.css文件。
覆盖式发布引发的问题
然而假如我们就按上述部署方案就上了线,很快就会 Fatal 满天飞,每次更新上线都可能会出现灾难。
我们回顾一下,网站的静态文件只有一份,部署在 Nginx 服务器某目录下,并且通过 query-hash 的方式实现按文件做精确缓存控制,问题出在哪了呢?
回顾一下,我们某次更新时,更改了 foo.css 样式,此时会将 HTML 中的foo.css url更新为最新的 hash,并将服务器中存储的 foo.css & index.html 文件覆盖为最新(V2版本),看似HTML和静态资源都对应更新了,但是没有考虑极端情况。那就是:
先部署静态资源,部署期间访问时,会出现V1版本HTML访问到V2版本新静态资源,并按V1-hash缓存起来。
先部署HTML,部署期间访问时,会出现V2版本HTML访问到V1版本旧静态资源,并按V2-hash缓存起来。
如下图所示,展示了不同版本HTML与不同版本静态资源互相匹配到出现的异常Case。
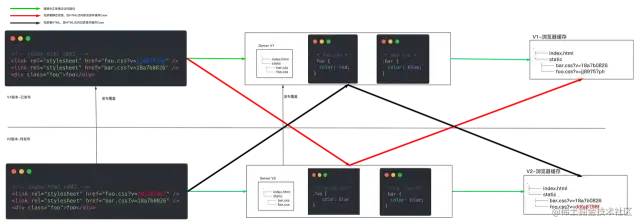
绿色走向:正常访问并建立缓存的路径。
红色走向:先部署静态资源(V2),V1-HTML访问V2静态资源并缓存Case
黑色走向:先部署HTML(V2),V2-HTML访问V1资源并缓存Case
对于问题1,会有两种子Case:
用户本地有缓存,此时无影响可正常访问。
用户本地无缓存,则会将V2版本静态资源加载并按V1版本 hash 缓存起来。用户报错。当V2版本HTML部署完成后,用户再次访问时恢复。
对于问题2,则会出现严重的Case:
V2 版本HTML,会将V1版本静态资源按V2版本Hash缓存起来。此时页面会出错,且缓存过期之前会持续报错。直到用户手动清除缓存,或者缓存过期,或者将来发布V3版本更新静态资源版本。否则用户会持续出错。
上面方案的问题起源于静态资源只有一份,每次发布时都是覆盖式发布,导致页面与静态资源出现匹配错误的情况!解决问题方案也极其简单,使用非覆盖式发布,一种简单的改造方式是将文件摘要(hash)放置到URL 中,即将 query-hash 改为 name-hash。
此时 HTML 变成如图:
这样,每次部署时先全量部署静态资源,再灰度部署页面,就能比较完美的解决了缓存的问题。
此时,服务器上会存在多份
foo.[$hash].css文件
与 CDN 结合
欢迎转载,转载请标明文章出处来自字节架构前端[3]
现在我们开开心心将网站部署上线了,但我们此时仍然将静态资源部署在 Nginx 服务器目录下,然后新的问题来了,随着时间推移,非覆盖部署导致文件逐渐增加多,硬盘逐渐吃紧。而且将文件存储在 Nginx Web服务器内某目录下,深度的将 Nginx、网站、部署过程等强耦合在一起,无法使用 CDN 技术。
CDN 是一种内容分发网络,部署在应用层,利用智能分配技术,根据用户访问的地点,按照就近访问的原则分配到多个节点,来实现多点负载均衡。
简单来说,用户就近访问,访问速度更快,大公司也无需搞一台超级带宽的存储服务器,只需使用多台正常带宽的 CDN 节点即可。
而 CDN 的常见实现是有一台源站服务器,多个 CDN 节点定时从源站同步。
那如何将 CDN 与 Nginx 等 Web 服务器结合呢?
答案是将静态资源部署到 CDN 上,再将 Nginx 上的流量转发到 CDN 上,这种技术我们称之为『反向代理』。
此时,用户访问时流量走向 & 研发构建部署过程大致如下:
 此时,我们总体部署方案需要进一步做三步改造。
此时,我们总体部署方案需要进一步做三步改造。
构建时依据环境变量,将
HTML中的静态资源地址加上CDN域名。构建完成后将静态资源上传到
CDN。配置
Nginx的反向代理,将静态资源流量转发到CDN。
其中,第 1、2 条涉及构建过程调整,以 Webpack 为例,我们需要做以下配置改造:
a. 配置 `output` 为 `content-hash` & `publicPath`
b. 配置 `Webpack-HTML-Plugin`下面是一个配置示例:
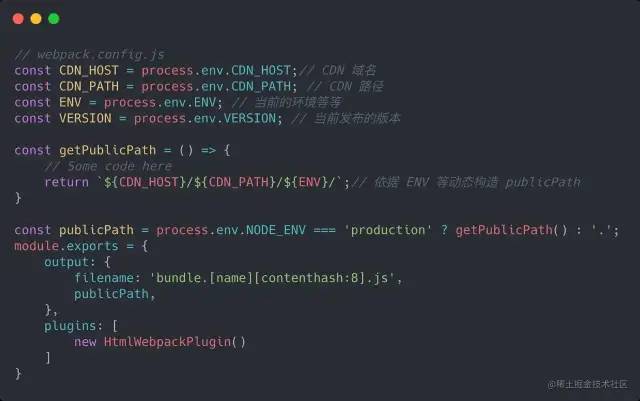
// webpack.config.js
const CDN_HOST = process.env.CDN_HOST;// CDN 域名
const CDN_PATH = process.env.CDN_PATH; // CDN 路径
const ENV = process.env.ENV; // 当前的环境等等
const VERSION = process.env.VERSION; // 当前发布的版本
const getPublicPath = () =>
// Some code here
return `$CDN_HOST/$CDN_PATH/$ENV/`;// 依据 ENV 等动态构造 publicPath
const publicPath = process.env.NODE_ENV === 'production' ? getPublicPath() : '.';
module.exports =
output:
filename: 'bundle.[name][contenthash:8].js',
publicPath,
,
plugins: [
new HtmlWebpackPlugin()
]
备注1:我们往往会将一套代码部署到多套前端环境,还需要在构建时注入当前部署相关环境变量(如
staging、prod、dev、pre等),以便动态构建publicPath。
备注 2:这里动态构造的 publicPath 里,严格的将产物按环境 + 发布版本做了隔离 & 收敛。某业务前端曾将所有环境的静态资源放到一起,以Hash做区分。但疑似出现了文件名 + hash 冲突,但文件内容不一样,导致了线上事故。故墙裂建议严格对产物做物理隔离。
备注 3:publicPath详解webpack.docschina.org/configurati…[4]
备注 4:此处使用了content-hash,与hash、chunkhash的区别请见:详解webpack中的hash、chunkhash、contenthash区别[5]
备注 5:使用contenthash时,往往会增加一个小模块后,整体文件的hash都发生变化,原因为Webpack的module.id默认基于解析顺序自增,从而引发缓存失效。具体可通过设置optimization.moduleIds设置为'deterministic'。
具体详见 webpack 官方文档-缓存[6]
注:关于 Webpack 的配置,校招生或客户端转前端同学,前期了解即可,后续建议深入学习。
构建完成后静态资源上传
CDN源站
上传 CDN 源站往往通过 CLI 调用各种客户端工具上传,此时要注意的是上传 CDN 依赖配置鉴权信息(如 文件存储的 Bucket Name/accessKey、ftp的账号密码)。这些鉴权信息不能直接写代码里,否则可能会有事故风险(想想为什么)!
第 3 步改造是 Nginx 层反向代理改造
反向代理(reverse proxy):是指以代理服务器来接受网络请求,并将请求转发给内部的服务器,并且将内部服务器的返回,就像是二房东一样。
一句话解释反向代理 & 正向代理:反向代理隐藏了真正的服务器,正向代理隐藏了真正的客户端。
详见:漫话:如何给女朋友解释什么是反向代理?[7]
Nginx 可通过设置 proxy_pass 配置代理转发,如
location ^~/static/
proxy_pass $cdn;
具体详见 nginx 之 proxy_pass详解[8]
注:校招生或客户端转前端同学,前期了解即可,后续建议熟悉 ~ 掌握。
静态资源组织总结
最后,回顾一下
为了最大程度利用缓存,将页面入口(
HTML)设置为协商缓存,将JavaScript、CSS等静态资源设置为永久强缓存。为了解决强缓存更新问题,将文件摘要(
hash)作为资源路径(URL)构成的一部分。为了解决覆盖式发布引发的问题,采用
name-hash而非query-hash的组织方式,具体需要配置Wbpack的output.filename为contenthash。为了解决
Nginx目录存储过大 + 结合CDN提升访问速度,采用了Nginx 反向代理+ 将静态资源上传到CDN。为了上传
CDN,我们需要按环境动态构造publicPath+ 按环境构造CDN上传目录并上传。为了动态构造
publicPath并且随构建过程插入到HTML中,采用Webpack-HTML-Plugin等插件,将编译好的带hash+publicPath的静态资源插入到HTML中。为了保证上传
CDN的安全,我们需要一种机制管控上传CDN秘钥,而非简单的将秘钥写到代码 /Dockerfile等明文文件中。
简直是层层套娃!
此时,我们已经基本获得了一套相对完备的前端静态资源组织方案。
此时你可能已经发现了,前端静态资源部署后,还有被 Nginx 加工消费过程,才能被用户访问到。
自动化构建
现在我们已经探索出一套静态资源组织的解决方案。现在探讨一下构建的过程。我们每次构建时大约需要进行这些步骤:
拉取远程仓库
切换到 XX 分支
代码安全检查(非必选)、单元测试等等
安装
npm/yarn依赖设置
node版本设置
npm/yarn源安装依赖等
执行编译 & 构建
产物检查(比如检测打包后
JS文件 / 图片大小、产物是否安全等,保证产物质量,非必选)人工卡点(非必选,如必须
Leader审批通过才能继续)打包上传
CDN自动化测试(非必选,
e2e)配套剩余其他步骤
通知构建完成
这其中,迎面而来的问题有:
在什么环境执行构建?
如何保证每次构建部署环境相同?
由谁触发构建?
如何管理前面所述上传
CDN等密钥(不增加成本、保证安全、保证构建上传可靠性)?如何自动化触发构建 & 自动化执行上述步骤?
假如每次都由人工执行,估计发版日就守着编译打包了,而且较为容易引发问题,比如某步骤遗漏或顺序错了。
如何提升构建速率?
构建完成如何通知研发同学构建完成了?
灵魂拷问有没有!
为了解决上面问题,业界有一些解决方案:
保证环境一致性:Docker[9]
按流程构建:Jenkins[10]
自动化构建触发:Gitlab webhook[11] 通知
开始构建通知:依赖账号体系打通+ Gitlab Webhook
构建完成通知:依赖账号体系打通
业界的大致实现,一般都为 Jenkins + Docker + GitlabWebHook,比如下面是一些实践:
前端项目自动化部署——超详细教程(Jenkins、Github Actions)[12]
iDeploy-为前端团队构建部署工程化而开发的一个持续交付平台[13]
此时还有一些其他问题:
比如宇宙最重物质 node_modules 安装速度过慢的问题?
如何提升 Build 构建速
上述往往在各大公司都有相对完善的构建系统 & 解决方案等,各公司各不相同但大致类似,故本文跳过该步骤。
前端发布服务 - 预发环境、版本管理(秒级回滚)、小流量、灰度、AB测试
假定我们静态资源组织完成,也搞定了自动化构建部署,也配好了 Nginx 的反向代理,我们的网站终于第一次上线了。
但第二次第三次上线怎么办?直接发到生产环境做回归测试的风险极大,但又不能本地部署前端测试环境去连接后端生产库(可以想想为什么),所以我们需要一个预发(Pre)环境,除了非测试人员访问不到之外,其他所有环节都和生产环境保持一致!
此时遇到第一个需求,预发环境功能。
假如我们某个功能是元旦零点发布,跨年时守在服务器面前点发布?万一 npm 抽风拉取依赖失败导致构建失败,或者上线后发现有bug,那就只能凉凉。
或者,随着时间推移大家前端项目越积越大,node_modules 质量逐渐超越银河系总质量,构建的时间往往会超过二十分钟甚至更久。某天某次我们新上线了功能后,却发现有致命阻塞性 bug,收款后自动退款 1.5 倍!想立即回滚版本?那就且等着,大眼瞪小眼的等它慢慢编译吧。这个时候才真的是时间就是金钱,再编译慢点公司就破产啦。
此时有没有一种办法,能在发现问题后,立即将版本回滚呢?并且这个回滚操作,回滚的同学也不应该登陆服务器去做操作(想想为什么?)。
此时遇到第二个需求,版本管理功能。 即可提前将静态资源上线,也需要保留每个历史版本,并且能实现瞬间切换版本,且切换过程不应该登陆服务器操作(想想为什么)。
其次是,假定 PM 对功能不断优化,想先灰度一部分用户,或者想做一些 AB 测试,比如给广东用户推广福建美食,给重庆用户推广钵钵鸡。
此时我们有两种方案,方案一是将把钵钵鸡和福建美食都打包到一份代码产物里,再在运行时根据地域做切换。但很快你的代码产物里就有钵钵鸡冷锅串串热锅串串老妈兔头跷脚牛肉狼牙土豆以及福建美食等等,会串味儿的对不对?况且热锅串串和冷锅串串打包混到一起我就第一个不同意,简直是对美食的亵渎!所以方案一不可取。
实际上,现实中往往会热锅串串冷锅串串这样完全不兼容的两份改动同时在线上运行做 AB 测试。
方案二是我们将热锅串串和冷锅串串分开打包,让热锅不犯冷锅。再设计一些机制,比如携带了香蕉糖果(cookie)的同学给跷脚牛肉锅,讲港东话的同学福建美食锅,四川地域的同学随机给火锅干锅汤锅鱼火锅。岂不乐哉?
大家应该很容易发现,这种机制是极其多变的,大概率朝令夕改。难道我们每次想调整干锅、鱼火锅的比例,就要登陆服务器做调整?某天干锅卖完了但又没带电脑回家怎么办?
此时遇到第三个需求,随时调整的小流量测试、AB-Test测试、灰度上线等等功能。
总结一下,为了满足复杂的线上需求,在部署层面总体来说需要:预发环境、版本管理、小流量、灰度、AB测试等功能。
静态资源的加工
如前所述,前端静态资源部署到 CDN 后,有一道 Nginx 反向代理做转发的加工工序。事实上,为了解决各种部署问题或为了提升性能,人们往往而需要对静态资源做更多的加工工序。
比如,部分 Web 应用为了提升首屏性能,一种常见的方式为通过 BFF 层或通过后端直出 HTML,并且在过程中注入若干信息,如 userInfo、用户权限信息、灰度信息等等,从而大幅降低前端登陆研发成本 & 降低首屏耗时。
下面是后端直出 HTML 的一种简要流程。
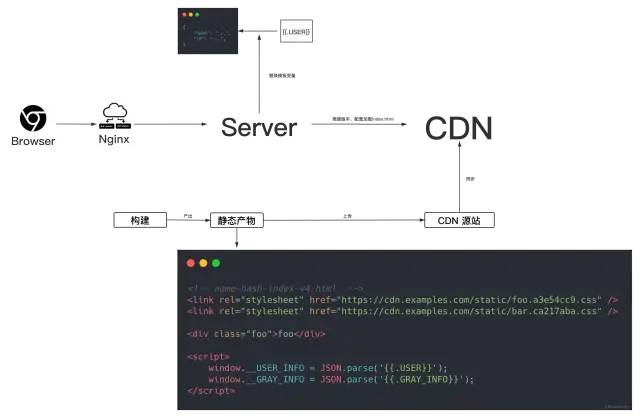
主要流程为前端构建出的 HTML 包含若干模板变量,后端收到请求后,通过各种 Proxy 层将 Cookie 转换成用户信息,再按依据版本配置从 CDN 加载 index.html, 并使用模板引擎等方式将模板变量替换为用户信息,最终吐回给浏览器的则是已经包含用户信息的 HTML 了!
Pre 环境、灰度上线的常见实现
如前所述,我们的静态资源为非覆盖式发布,多次部署后,线上存在若干版本静态资源。实现Pre环境/灰度上线的思路则是:通过一定的机制,让特定用户访问特定静态资源版本,从而达到访问Pre/灰度上线的能力。
方案一 Nginx 层动态转发
一种常见的 Pre 机制是静态资源部署多个版本后,开发者的通过 ModHeader 等浏览器插件,在请求中携带特定 Header(如xx-env=pre),在 Nginx 层消费该 Header 并动态转发到对应环境的静态资源上,实现访问 Pre 环境目的。此时,除静态资源为特定版本外,所有环境都是生产环境,可以将变量范围控制在最小。
流程大致如图:
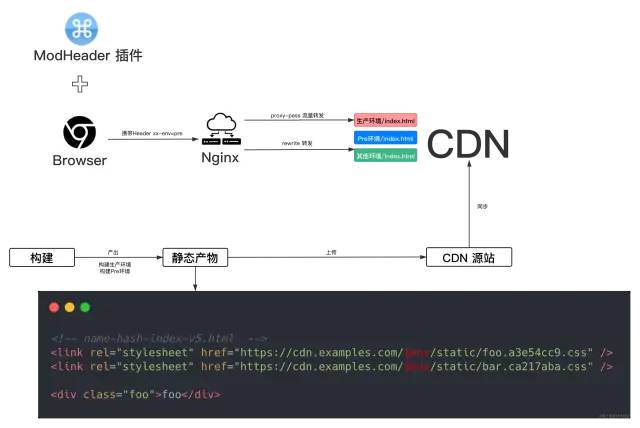
Nginx 可通过配置 rewrite 设置转发,如下所示。
详情请查阅:nginx配置rewrite指令详解[14]
location /example
rewrite ^ $cdn/$http_x_xx_env/index.html break;
proxy_pass $cdn/prod/index.html;
# $http_x_xx_env 表示取自定义的 Request Header 字段 xx_env注:对于Nginx,校招生或客户端转前端同学,前期了解即可,后续建议熟悉 ~ 掌握。
该方案优点为配置简单高效,适用于工程师。
缺点为每个用户都需要手动配置,不适用于移动端,且无法让特定用户被动精确访问某版本,比如 PM、KP 用户来配置 Header 成本过高。
同理,也可以在 Nginx 层按一些其他规则处理,实现灰度上线的能力。
如通过一定随机数 rewrite,达到小范围随机灰度。
获取 ua 并 rewrite,达到按浏览器定向灰度。
通过 Nginx GeoIP 获取地域信息,达到按地域灰度。
但上述灰度方案配置复杂,而灰度比例 / 范围往往会配置较多,每次上线都需要运维登陆生产服务器修改,较容易出各种事故。故不推荐使用,仅供拓宽思路。
方案二 动态配置 + 服务端转发
但 Pre 环境或灰度往往需要精确定位某些特定人群,如给特定PM、HR、远端报错的特定用户、KP用户 甚至给某个部门开 Pre环境等。上述同学工程背景相对缺失 / 较忙 / 通过移动端访问,此时通过修改 Header 的方式不再适用。故我们仍然要寻找某种机制,达到能方便随时调整 Pre/ 灰度范围又不用重新发版上线。既然需要按用户维度来定向,此时就依赖后端帮忙处理了。
而为了能随时随地调整灰度 / Pre 策略,而非依赖调整代码发版上线,此时引入配置中心的概念。
配置中心:一般是独立的平台 / SDK,提供动态配置管理的解决方案,提供功能有配置管理、版本管理、权限管理、灰度发布等等。后端应用通过接口消费,故配置中心和后端解耦,可以随时修改调整配置而非重新发版。配置中心一般是配置一个 JSON 对象。配置中心JSON对象人工维护容易引发问题,故增加机器人来降低出错几率。
下图是依赖配置中心 + 服务端转发的流程图:
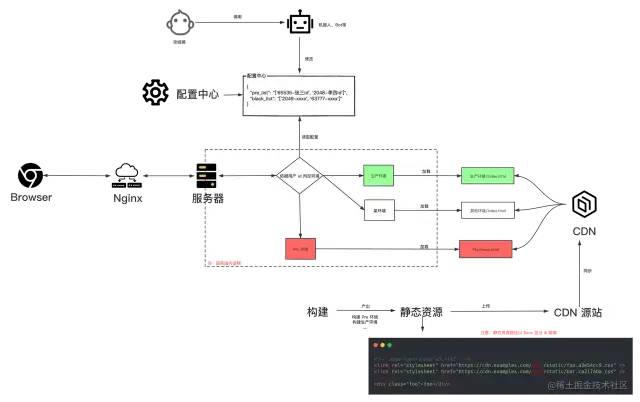
主要流程为:
前端攻城狮同学部署多个版本静态资源到 CDN 上(问题?如何管控多版本静态资源?)。
后端收到请求后,通过各种 Proxy 层将 Cookie 转换成用户信息。
后端读取配置中心数据,依据用户信息判断给用户访问什么环境,加载具体环境 index.html
后端返回给浏览器加工后的 index.html
若需添加具体 KP 等同学到 Pre 名单,攻城狮同学只需调用机器人/Bot 等,修改配置中心,即可生效。
注意,在上述架构下,若线上某用户发生某些难以排查的问题,也可发布特定的版本,在配置中心修改后让用户访问特定版本页面,从而简化排查问题的过程。
此时,一些小流量配置,AB实验,版本管理其实也可以通过该方案实施。
该方案优点:可以随时调整,不用后端发版,移动端也可生效。
该方案缺点:
和服务端强绑定(要求用户信息,在所难免)。
每次都需要从
CDN加载HTML, 有一定性能浪费。但若缓存HTML,发版环节还要通知服务端,总体增加复杂度。若考虑
CDN故障,服务端做CDN降级会增加复杂度。版本管理 / 小流量等为通用需求,而该方案每个后端应用都需要开发或接入。
常见的配置中心又一般为
JSON配置,比较简陋,和发版的多环境无法关联,依赖人为配置,有出错的风险(如发版v1.2501,配置中心手动配置时手误改成了v1.2051)。
前端发布服务实现与设计
可能部分同学对线上产物实行版本管理会误理解对代码增加版本管理(如发版后手动 / 自动打Tag),后续需要时再次发版部署即可满足需求。但如前所述,通过源码做版本管理灵活性较差,无法做到一键 &秒级切换版本,不满足商业化环境多变 & 复杂的需要。
那么如何进行版本管理呢?答案是对构建产物进行深层次加工 & 管理。
与此同时,版本管理/小流量是前端部署的常见公共业务需求,应该和业务后端服务脱离,故这里提出一个新的公共服务,纯用于前端部署相关,此处将之称为 Page Server,用于具体的 index.html 文件管理 & 承接 Nginx 流量或业务后端流量等。
同时,鉴于版本管理、小流量策略等调整会特别频繁,每次调整不应该都登录服务器,故我们需要一个新的服务 & 界面,用于操作管理版本、调整小流量等信息,并且与上述 Page Server 同步,此处我们将该服务称之为 Page Config Web。
而我们的 Page Server 则可能会有很多个实例,部署在多个集群上,以满足跨国部署、多部门项目部署等要求。所以理想情况下 Page Config Web ****还要承接 PageServer 的创建、管理、配置等工作。所以 PageConfigWeb 与 PageServer 是 1 比 N 关系(或M比N,用于跨国部署等)。
同时,我们一个前端项目可能有多套前端环境,PageSever 在固定集群算公共设施,这些环境理论上都可以由一个或多个 PageServer 承载。故一个 PageServer 和多个前端环境是 1 比 1 或者 1 比 N 关系。
此时,对于 Nginx 来的流量,我们需要一种机制来区分该流量属于哪个环境实例,比如通过 URL 来区分,我们可以称之为 路由。
最后,为了保证上述服务的正确性和自动化,构建部署(新增版本)完成后,要同步到上述两个服务,以确保版本管理的正确性。
最后,大致的流程图如下:
超大图预警
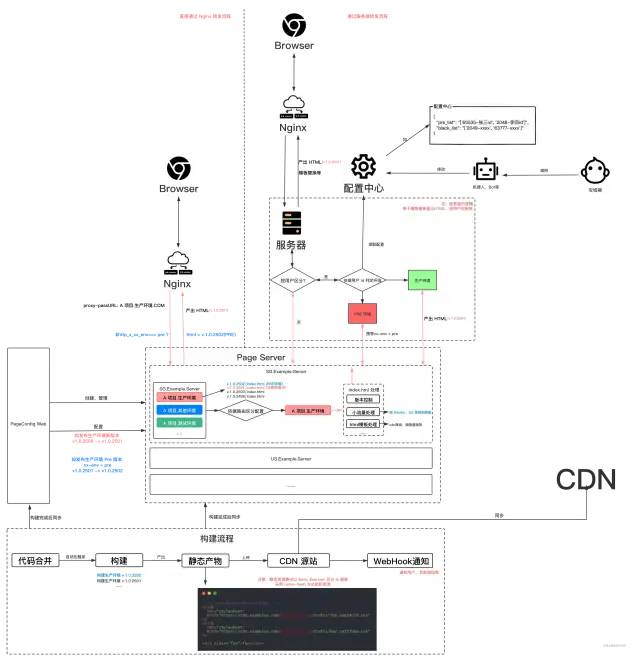
本质上来说,相当于有一个公用的中间服务,部署在多个集群上,与构建发布过程深度绑定,用于承接HTML 的流量,并通过 Web 站点设置小流量规则、版本等等,来满足多变的上线需求。
其中,PageServer 在承载 HTML 服务时,可做一些其他工作,比如:
SSR
CDN 降级,用于 CDN 异常时直出 HTML 中将静态资源替换为可用的 CDN 站点。
404 处理
兜底页(比如服务出现故障,短时间内无法修复时出兜底)
模板渲染(如做模板替换,将 query 替换到模板中等)
特殊时期全局处理,如注入全局样式将页面全局置灰
等等等等。
PageConfig Web 和 PageServer 中有构建后的所有版本信息,理论上可以缓存每个版本的 HTML文件,并且为了优化性能,PageServer 中可将最新全量版本的 HTML 文件缓存到内存中,最大程度提升响应速度,其余版本存储到 Redis 等缓存中。
下面以发布一个正式版本 v.1.0.2502 并且回滚过程为例:
代码合并,触发自动化构建,构建产物以环境(env)+版本(env) + 版本(env)+版本(version) + name-hash 方式组织,并上传到 CDN。
构建完成后,构建脚本通知攻城狮同学、同步 PageServer、PageConfig Web 服务有新版本 v.1.0.2502 。
攻城狮同学收到通知后,到 PageConfig Web 站点发布新版本 v.1.0.2502 (PRE),并为该版本配置 PRE 环境小流量规则,
xx-env = pre。此时,只有设置特定 Header 才能访问该版本。若是 Nginx 直接转发,则攻城狮通过设置 Header 访问 PRE 版本。
若是通过服务端转发,攻城狮通过配置中心设置 PRE 白名单,即可让用户访问 PRE 版本。
在 PRE 版本验收完成后,攻城狮登录 PageConfig Web 站点,发布正式版本 v.1.0.2502 (不带小流量信息)。此时立即生效。
生效后线上回归,发现有 bug,攻城狮立马登录 PageConfig Web 站点,将版本回滚为上一版本v.1.0.2501 。此时立即生效。
关于部署的总结
静态资源组织部分
为了最大程度利用缓存,将页面(HTML)设置为协商缓存,将 JavaScript、CSS 等设置为永久强缓存。
为了解决强缓存更新问题,将文件摘要(hash)作为资源路径(URL)构成的一部分。
为了解决覆盖式发布引发的问题,采用 name-hash 而非 query-hash 的组织方式,具体需要配置 webpack 的 output.filename 为 contenthash 方式。
为了解决 Nginx 目录存储过大 + 结合 CDN 提升访问速度,采用了 Nginx 反向代理+ 将静态资源上传到 CDN。
为了上传 CDN,我们需要按环境动态构造 publicPath + 按环境构造 CDN 上传目录并上传。
为了动态构造 publicPath 并且随构建过程插入到 HTML 中,采用 Webpack-HTML-Plugin 等插件,将编译好的带 hash + publicPath 的静态资源插入到 HTML 中。
为了保证上传 CDN 的安全,我们需要一种机制管控上传 CDN 秘钥,而非简单的将秘钥写到代码 / Dockerfile 等明文文件中。
自动化部署部分
为了提升部署效率,100% 避免因部署出错,需要设计 & 搭建自动化部署平台,以 Docker 等保证环境的一致性,以 Jenkins 等保证构建流程的串联。使用es-build等提升构建效率。
前端部署 & 静态资源加工
关于前端部署,能总结出下面几个原则/要求:
构建发布后,不应该被覆盖。
构建发布后,静态资源应当永久保存在服务器/CDN 上,即只可读。
静态资源组织上,每个版本应该按文件夹存储,做到资源收敛。这样假如真要删除时,可按版本删除。(如某个版本代码泄密)
// webpack.config.js
const CDN_HOST = process.env.CDN_HOST;// CDN 域名
const CDN_PATH = process.env.CDN_PATH''; // CDN 路径
const ENV = process.env.ENV; // 当前的环境等等
const VERSION = process.env.VERSION; // 当前发布的版本
const getPublicPath = () =>
// Some code here
return `$CDN_HOST/$CDN_PATH/$ENV/$VERSION/`;// 依据 ENV 等动态构造 publicPath
module.exports =
output:
filename: 'bundle.[name][contenthash].js',
publicPath: getPublicPath(),
,
plugins: [
new HtmlWebpackPlugin()
]
故 publicPath 应增加 version 字段
发布过程应该自动化,开发人员不应该直接接触服务器。
版本切换时,也应当不接触服务器。
版本切换能秒级生效。(如 v0.2 切换 v0.3,立即生效)。
线上需要能同时生效多个版本,满足 AB 测试、灰度、PRE 环境等小流量需求。
上述需求都相对复杂多变,为了应对复杂的线上需求,可以对静态资源做深度加工,如通过服务端直出 HTML、通过配置中心实现按用户 PRE 等等。
前端发布服务
面对复杂的商业化需求,方便多前端业务实现版本管理、灰度、PRE、AB 测试等小流量功能,我们设计了一个中间服务 PageConfig Web & PageServer,与 Nginx 和各种后端相结合,达到配置即时生效的能力。
灵魂拷问的部分答案
Q: 前端代码从 tsx/jsx 到部署上线被用户访问,中间大致会经历哪些过程?
A: 经历本地开发、远程构建打包部署、安全检查、上传CDN、Nginx做流量转发、对静态资源做若干加工处理等过程。
Q:可能大部分同学都知道强缓存/协商缓存,那前端各种产物(HTML、JS、CSS、IMAGES 等)应该用什么缓存策略?以及为什么?
若使用协商缓存,但静态资源却不频繁更新,如何避免协商过程的请求浪费?
若使用强缓存,那静态资源如何更新?
A:HTML使用协商缓存,静态资源使用强缓存,使用name-hash(非覆盖式发布)解决静态资源更新问题。
Q:配套的,前端静态资源应该如何组织?
A:搭配 Webpack 的Webpack_HTML-Plugin & 配置 output publicPath等。
Q:配套的,自动化构建 & 部署过程如何与 CDN 结合?
A:自动化构建打包后,将产物传输到对应环境 URL 的CDN上。
Q:如何避免前端上线,影响未刷新页面的用户?
A:使用name-hash方式组织静态资源,先上线静态资源,再上线HTML。
Q:刚上线的版本发现有阻塞性 bug,如何做到秒级回滚,而非再次部署等 20 分钟甚至更久?
A:HTML文件使用非覆盖方式存储在CDN上,搭建前端发布服务,对 HTML 按版本等做缓存加工处理。当需要回滚时,更改发布服务HTMl指向即可。
Q: CDN 域名突然挂了,如何实现秒级 CDN 降级修补而非再次全部业务重新部署一次?
A1: 将静态资源传输到多个 CDN 上,并开发一个加载Script的SDK集成到HTML中。当发现CDN资源加载失败时,逐步降级CDN域名。
A2:在前端发布服务中,增加HTML文本处理环节,如增加CDN域名替换,发生异常时,在发布服务中一键设置即可。
Q:如何实现一个预发环境,除了前端资源外都是线上环境,将变量控制前端环境内?
A:对静态资源做加工,对HTML入口做小流量。
Q:部署环节如何方便配套做 AB 测试等?
A:参见前端发布服务
Q:如何实现一套前端代码,发布成多套环境产物?
A:使用环境变量,将当前环境、CDN、CDN_HOST、Version等注入环境变量中,构建时消费 & 将产物上传不同的CDN即可。
其他
如果想深入学习前端部署,下面是一些学习建议。
学习负载均衡(要求:了解)。
学习和了解负载均衡的原理、都有哪些配置玩法。如参考大型网站架构系列:负载均衡详解[15]深入学习 HTTP(要求:熟练掌握)
如掌握常见的状态码、常见的 Header 及其深度应用、强缓存/协商缓存、HTTP2 的新增功能等等。尤其HTTP 1.1 和 HTTP 2.0。推荐书籍:
图解HTTP[16]
HTTP 权威指南[17]深入学习前端工程化 (要求:精通)
a. 了解前端工程化可以做什么,如 前端工程化:体系设计与实践[18]
b. 掌握前端工程师的常见实践原理 & 实操
c. 深度学习 Webpack Webpack 官方文档[19]学习各种对前端静态资源加工的各种方案(要求:掌握)
深度学习浏览器原理 (要求:精通)
一些资料:从浏览器多进程到JS单线程,JS运行机制最全面的一次梳理[20]
关于本文
作者:字节架构前端
https://juejin.cn/post/7017710911443959839
推荐链接

创作不易,加个点赞、在看 支持一下哦!
以上是关于2021年前端部署的灵魂拷问的主要内容,如果未能解决你的问题,请参考以下文章
面试面到自闭,字节Python后端开发岗4轮面试,四个小时灵魂拷问,结局我哭了