MySQL事务原理
Posted 小王子jvm
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL事务原理相关的知识,希望对你有一定的参考价值。
原子性怎么实现的
首先需要知道的就是在mysql中有几种日志,什么undo log,redo log。而原子性就是undo log实现的。
undo log就是记录一些相反的操作,比如我插入一条数据,那么这个日志中记录的就是删除这条数据,更新这条数据,记录的就是更新为原来的数据。这样就可以在事务出现问题,需要回滚保证原子性,通过这个日志就可以查找到我之前的状态然后逐步 恢复过去。
持久性怎么实现
同样也是基于日志,叫做redo log日志。
数据库在更新数据时候,为了提升速度,会有一个对应的Buffer缓冲区,也就是先把数据读取到buffer中,对这个更改之后在刷回磁盘,这样就会出现一个问题,如果还没有刷回就挂了,数据岂不是直接丢了?
所以就有redo log这个东西来记录写入的东西:
- redo log buffer :保存在内存中,同样是容易丢失的
- redo log file:保存在磁盘中,不会丢失
有了这个之后再来看看开启事务插入数据的一个过程:
- 开启事务
- 执行语句(更新或者插入,删除)—> 此时数据就会刷到buffer中
- redo log buffer记录修改
- commit事务 ----> 此时redo log buffer 就真的写入文件当中
后续刷新到数据磁盘是在MySQL后台完成的
为什么还有binlog这个日志文件
因为最开始 MySQL 里并没有 InnoDB 引擎。MySQL 自带的引擎是 MyISAM,但是 MyISAM 没有 crash-safe 的能力,binlog 日志只能用于归档。而 InnoDB 是另一个公司以插件形式引入 MySQL 的,既然只依靠 binlog 是没有 crash-safe 能力的,所以 InnoDB 使用另外一套日志系统——也就是 redo log 来实现 crash-safe 能力。
这两者是有不同的:
- binlog是server层的,所有存储引擎都可以使用,而redo log只能用于Innodb。
- redo log是物理日志,直接记录的是在某个数据页改了什么,而binlog是逻辑日志,记录的是执行语句的逻辑。
- redo log是循环写,空间大小固定,是会写完的,而binlog是追加的,满了就换下一个binlog。
至此再来看一下一条SQL执行的过程:
- 假设是一条更新语句,就会先去取到这个数据,假设id为2
- 判断在不在内存的数据页(buffer)中,有就往下执行,没有就从磁盘中读取更新到数据页中
- 将数据跟新,假设为就是自增1,然后写回buffer
- 然后就写入redo log,此时redo log处于prepare阶段
- 写入binlog当中
- 提交事务,此时处于commit阶段
这样数据就完整的写入日志磁盘当中,至于真正写回数据磁盘就是MySQL自己啥时候比较闲就去做的事情了。
这个prepare和commit就是两阶段提交了
两阶段提交
为毛数据库要这样搞呢,这是为了保证两个日志文件数据一致性的问题
- redo log写入磁盘时候,事务就是prepare
- binlog写入之后就是commit
这两都有一个共同的数据字段叫做XID,当数据崩溃进行恢复时候会先按顺序扫描redo log:
- 如果碰到既有 prepare、又有 commit 的 redo log,就直接提交;
- 如果说只有prepare,这个时候就要看binlog有没有记录了,拿着XID去binlog中找对应的事务。有记录就提交,没有就回滚。
所以保证持久性使用redo log日志,在更新之前会先写入日志,再去刷新buffer。而且,这是基于一个顺序IO追加的方式写入,效率很搞,buffer写入磁盘是随机的IO,并且buffer是以数据页为单位写入,MySQL中默认数据页大小为16k,一点点修改,也会让整个数据页的数据加载进buffer或者写入磁盘。
MVCC实现隔离性
在并发的情况下会出现一些问题,比如脏读,不可重复读,幻读。
- 脏读:两个人读取数据,假设A改了数据,但是没有真的把这个数据提交,但是B去读却可以读到这个数据,而这个数据就属于脏数据。
- 不可重复读:同样的,假设A读取一次数据,然后B改动了这个数据并且提交了,这个时候A再读取发现跟第一次读取不一样了。
- 幻读:A读取几行数据,然后B插入或者删除几条数据,A再次读取发现数据变多了或者变少了。
对应的为了解决这几个问题,就引出了几种隔离级别:读未提交,读已提交,可重复读,串行化。
- 读未提交:显然就是什么都解决不了,脏读后面的一系列问题都会出现。

-
读已提交:显然可以解决脏读,但是不可重复读后面的解决不了。

-
可重复读:就是为了解决不可重复读。

-
串行化:都别急,一行一行的执行,都能解决但是速度太慢。
读已提交和可重复读(MVCC就是解决这两个之间的问题)
简单的介绍这个过程,每个数据行都有一个隐藏的数据字段,trx_id,用于记录当前这个更新是哪个事务更新的。
然后就是read view这个东西,就是一个快照,也就是比如开启事务就会生成一个快照,这个事务使用的数据以哪个最新更新的事务数据为标准。(每个事务开启都会有一个事务id,这个事务id是按照开启的时间严格递增的)
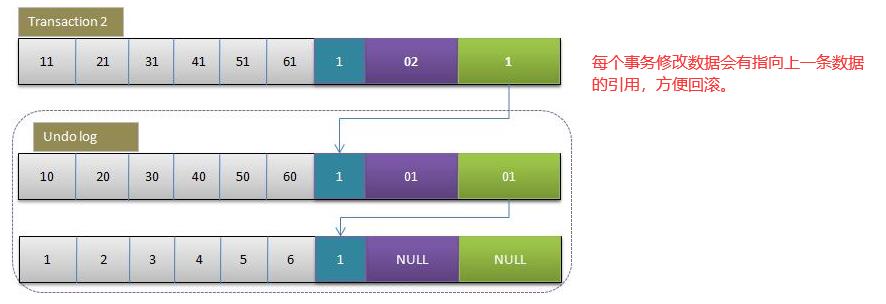
假设此时事务数据指向的事务id为90
如果设置的隔离级别为读已提交,那么每条SQL执行前都会生成一个readview:
- 如果事务1开启,查询A的值为1(查询之前生成一个ReadView),事务1的id为91
- 然后事务2开启,事务id为92,然后更新A的值为2并且提交,那么此时的A指向的事务就是92
- 然后事务1再次读取数据A,又会生成ReadView,生成的ReadView会获取到最新的值,也就是A=2,所以会出现不可重复读
如果设置的隔离级别为可重复读,那么RaedView会在事务开启的时候生成。
- 如果事务1开启(生成的readview,此时最新的记录就是A为1),查询A的值为1,A为91
- 事务2开启(同样最新的记录就是A为1),然后更新这个值并且提交
- 事务1再读取,同样会读取到A为2,但是此时A指向的事务id为92,大于自己的,说明这个是在我开启之后更新的,所以不会要,会拿着这个数据在undo log中找上一条记录,直到找到一个事务id比我小的。
所以读已提交和可重复读在这里面的区别就是ReadView生成的时机不同。
这里再来一个事务,假设为3,在事务2修改前修改了,然后事务2去修改会在事务3的基础上去修改,这种读取方式叫做当前读。当然可以推理如果事务1读取而不是修改,读取到的值依然是生成快照的那个值。
最后,我这里的MVCC可能说的非常的简陋,我的理解大概就是这么个意思吧。
以上是关于MySQL事务原理的主要内容,如果未能解决你的问题,请参考以下文章