HBaseFlumeNginxRedisKafka基础
Posted 回忆过去,是最美好的事情。
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HBaseFlumeNginxRedisKafka基础相关的知识,希望对你有一定的参考价值。
文章目录
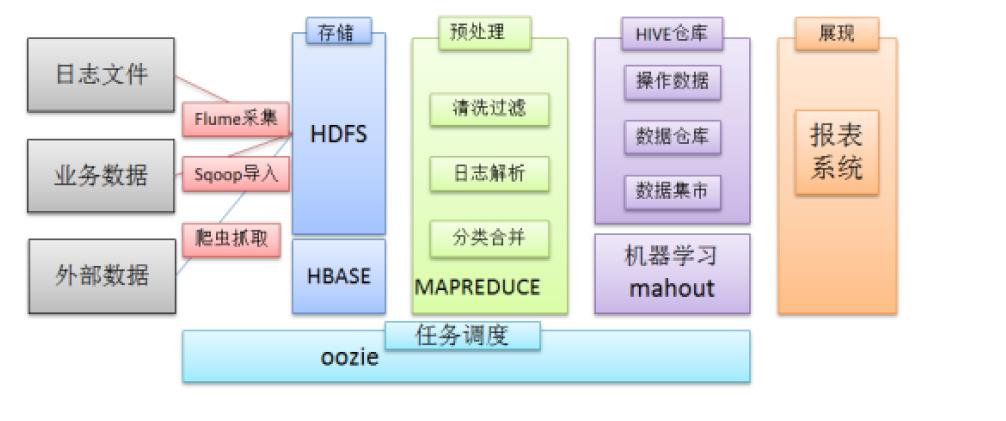
1. HBase
概念
- 建立在HDFS上,提供高可靠性、高性能、列存储、可伸缩、实时读写 的分布式数据库系统
- 在需要实时读写随机访问超大规模数据集时,可以使用HBase
HBase特点
- 海量存储
- 可以存储大批量数据
- 列式存储
- HBase表的数据是基于列族进行存储的,列族是在列的方向上进行存储
- 极易扩展
- 底层依赖HDFS,当磁盘空间不足时,只需动态增加datanode结点就可
- 可以通过服务器来对集群的存储进行扩容
- 高并发
- 支持高并发读写请求
- 稀疏
- 系统主要是针对HBase列的灵活性,在列族中,可以指定任意列,在列数据为空的情况下,不会占用存储空间
- 数据的多个版本
- HBase表的数据可以有多个版本值,默认情况下是根据版本号去区分,版本号就是插入数据的时间戳
- 数据类型单一
- 所有的数据在HBase中是以字节数据进行存储
HBase数据类型
- rowKey 行键,table按照rowKey的字典序进行排序
- Column Family 列族
- HBase表中每列都归属于某个列族
- Column列
- 列是列族下的一个列,用
列族名:列名,表示为info:name
- 列是列族下的一个列,用
- cell单元格
- 指定row key行键、列族、列,可以确定一个cell单元格
- cell中的数据是没有类型的,全部是以字节数组存储
- TimeStamp 时间戳
- 可以对表中的cell多次赋值,每次赋值操作时时间戳,可看做cell值的版本号,一个cell可以有多个版本值
HBase整体架构

- client客户端是操作HBase集群的入口
- 对管理类的操作,如表的增删改操作,Client通过RPC和HMaster通信完成
- 对表数据的读写操作,Client通过RPC和RegionServer交互,读写数据
- Client类型
- HBase shell
- Java编程接口
- Thrift、Avro、Rest等
- ZooKeeper集群
- 实现了HMaster的高可用,多HMaster间进行主备选举
- 保存了HBase的源信息meta表,提供了HBase表中region的寻址入口
- 对HMaster和HRegionServer实现了监控
- HMaster
- HBase集群也是主从架构,HMaster是主的角色
- 主要负责Table表和Region的相关管理工作
- 关于Table
- 管理Client对table的增删改操作
- 关于Region
- 在Region分裂后,负责新Region分配到指定的HRegionServer上
- 管理HRegionServer间的负责均衡,迁移region分布
- 当HRegionServer宕机之后,负责其上的region的迁移
- HRegionServer
- HBase集群中从的角色
- 作用
- 响应客户端的读写数据请求
- 负责管理一系列的Region
- 切分在运行过程中变大的Region
- Region
- HBase集群中分布式存储的最小单元
- 一个Region对应一个Table表中的部分数据
2. Flume
概念
- flume是cloudera提供的一个高可用的、高可靠、分布式的海量日志采集、聚合和传输的系统
- Flume支持在日志系统中定制各类数据发送方,用于收集数据
- Flume提供对数据进行简单处理,并写到各种数据接收方(可定制)的能力。
Flume架构

- Flume的核心是把数据从数据源收集过来,再送到目的地。为了保证输送一定成功,在送到目的地之前,会先缓存数据,待数据真正送到目的地之后,删除自己本地缓存的数据。
- Flume分布式系统中最核心的角色是agent,fluem采集系统就是若干个agent连接起来形成。
- 每个agent相当于一个数据传送员,内部有三个组件
- source
- 采集组件,用于跟数据源对接,以获取数据
- channel
- 传输通道组件,缓存数据,用于从source将数据传递到sink
- sink
- 下沉组件,数据发送给最终存储系统或下一级agent
- source
3. nginx
概念
- 一个高性能的文本服务器和反向代理服务器,也可作为邮件代理服务器
- 特点是占有内存少,并发处理强,以高性能、低系统资源消耗而闻名,
正向代理和反向代理
- 正向代理。类似一个跳板机,代理访问外部资源。如科学上网,国内网络连不上某网站,但是能访问一个代理服务器,使用这个代理服务器访问不能访问的网站,然后代理服务器返回访问的内容
- 反向代理。以代理服务器接受internet上的连接请求,然后将请求转发给内部网络上的服务器,并将从服务器上返回的结果返回给internet上请求连接的客户端,此时代理服务器对外表现为一个反向代理服务器。
Nginx主要应用
nginx主要通过配置nginx.conf文件完成以下功能。
- 应用部署
- 负载均衡
- 静态代理
- 动静分离
4. Redis
Redis是内存数据库,作为热门的NoSQL数据库之一被很多互联网公司使用,是一个key-value存储系统,类似于Java中的Map; 同时Redis还可以通过实现数据的持久化来防止数据丢失;Redis可以周期性的将更新的数据写入磁盘中。
4.1 概述
Redis是一个支持lua脚本、LRU内存回收、内存复制机制、事务和不同级别磁盘持久化特点的开源内存数据结构存储库。它支持散列、字符串、集合、列表、范围查询的有序集、位图和具有半径查询的地理空间索引等数据结构,通常用作数据库、缓存和消息代理。另外,它还可以通过Redis Sentinel提供高可用性,并通Redis Cluster进行自动分区。Redis是一个高性能的、开源的、基于key-value键值对的缓存和存储系统。Redis使用起来很方便,可以提供多种键值数据来适应不同场景下的缓存和存储要求。
4.2 特点
Redis是内存数据库,从内存中读取数据的速度远远快于从硬盘中读取。
Redis特点
- 数据读取性能高,速度快,主要适合存储一些读取频繁、变化较小的数据。
- 支持丰富的数据类型。Redis支持二进制的String、List、Hash和Set等数据类型操作,并且对不同的数据类型提供了很方便的操作方式。例如,Redis支持的String存储类型可以包含任何数据,可以是JPG图片,也可以是序列化的对象,同时Hash类型可以通过key对应多个value的存储形势,可避免key值过多而消耗大量内存的情况。
- 原子性。Redis的操作是原子性的,支持事务。所谓原子性就是指一系列对数据的操作要么都成功,要么都失败。原子性的特点不需要我们考虑并发的问题。
- Redis还有一个特点就是可以设置key的过期时间,一旦到了过期时间,Redis会自动删除缓存信息。另外,redis也可以将内存中的数据以异步的方式写入硬盘中,从而可以避免内存数据丢失的问题。
5. Kafka
概述
kafka是一个分布式消息队列,具有高性能、持久化、多副本备份、横向扩展能力。生产者往队列中写消息,消费者从队列中取消息进行业务逻辑。Kafka是一种发布-订阅模式。将消息保存在磁盘中,以顺序方式读写方式读取磁盘,避免随机读写导致性能瓶颈。
集群架构
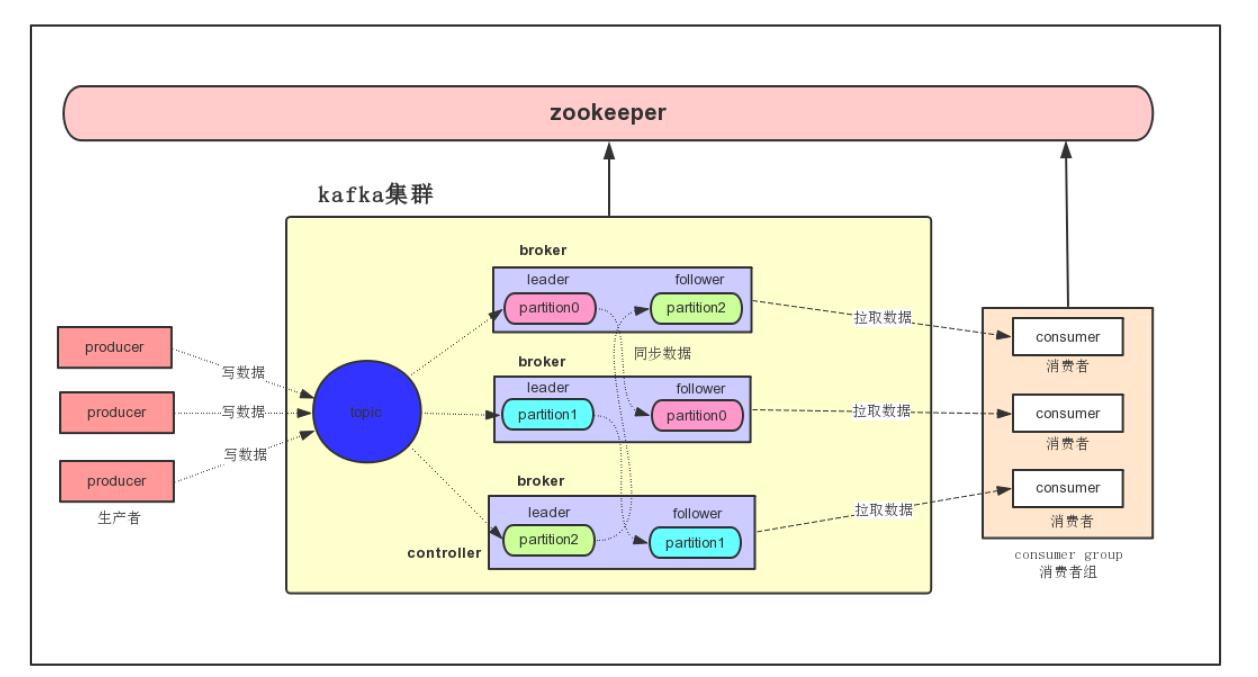
kafka集群架构
- producer
- 消息生产者,发布消息到kafka集群的终端或服务
- broker
- kafka集群中包含的服务器,一个broker表示kafka集群中的一个节点
- topic
- 每条发布到kafka集群的消息属于的类别,即kafka是面向topic的。更通俗的说topic就像一个消息队列,生产者可以向其写入消息,消费者从中读取消息,一个topic支持多个生产者和多个订阅者同时订阅,所以扩展性好。
- pritition
- 每个topic包含一个或多个partition。kafka分配的单位是partition
- replica
- partition的副本,保障partition的高可用
- consumer
- 从kafka集群中消费消息的终端或服务
- consumer group
- 每个consumer都属于一个consumer group,每条消息只能比consumer group中的一个consumer消费,但可以被多个consumer group消费。
- leader
- 每个partition有多个副本,其中有且仅有一个作为leader,leader是当前负责数据读写的partition。producer和consumer只能leader交互。
- follower
- follower跟随leader,所有写请求由leader路由,数据变更会广播到所有follower,follower与leader保持数据同步。如果leader失效,则从follower中选举出一个新的leader。
- controller
- 负责监控kafka集群范围内的所有东西
- zookeeper
- kafka通过zookeeper存储集群中meta元数据信息
- 一旦controller所在的broker宕机了,此时临时节点消失,集群里其他broker会一直监听这个临时节点,发现临时节点消失了,就争抢再次创建临时节点,保证有一台新的broker会成为controller角色
- offset
- 消费者在对应分区上已经消费的消息数
- kafka0.8版本之前offset保存在zookeeper上
- kafka0.8之后offset保存在kafka集群上
- ISR机制
- 保证follower和leader数据的同步。
6 推荐系统
推荐分类
- 社会化推荐,例如向亲朋好友推荐
- 基于内容的推荐,根据搜索结果返回的内容
- 基于流行度的推荐,根据近期视频热度排行榜
- 基于协同过滤的推荐,根据用户历史内容推荐
推荐模型构建流程
- 数据获取
- 特征构建
- 算法选择
- 输出预测
推荐系统的核心算法基本逻辑是
-
和你有相似爱好的人所喜欢的物品,也是你所喜欢的,user-based 协同过滤
-
和你所喜欢的物品类似的物品,你也是喜欢的,item-based 协同过滤
计算相似度的方法
-
Jaccard相似度 J ( a , b ) = ∣ a ∩ b ∣ ∣ a ∪ b ∣ \\displaystyle J(a,b)=\\frac\\vert a\\cap b\\vert \\vert a\\cup b\\vert J(a,b)=∣a∪b∣∣a∩b∣
-
余弦相似度 c o s θ = a b ∣ a ∣ ∣ b ∣ \\displaystyle cos\\theta =\\fraca b\\vert a \\vert\\vert b \\vert cosθ=∣a∣∣b∣ab
-
对数似然相似度 s i m i l a r i t y = 2 × ( m a t r i x E n t r o p y − r o w E n t r o p y − c o l u m n E n t r o p y ) \\displaystyle similarity=2\\times (matrixEntropy-rowEntropy-columnEntropy) similarity=2×(matrixEntropy−rowEntropy−columnEntropy)
-
皮尔逊相似度 c o r r ( a , b ) = C o v ( a , b ) σ a 2 σ b 2 \\displaystyle corr(a,b)=\\fracCov(a,b)\\sqrt\\sigma_a^2\\sqrt\\sigma_b^2 corr(a,b)=σa2σb2Cov(a,b)
-
如果基于user-based的协同过滤算法,那么我们需要求出所有用户间的皮尔逊相似度,然后通过k近邻算法找到和被推荐用户最相似的k个用户,将他们评分高且被推荐用户未购买过的商品推荐给这些用户。
-
如果使用基于item-based的协同过滤算法,我们需求出所有商品之间的皮尔逊相似度,然后找到和被推荐用户购买过的商品相似度最大的商品,推荐给这些用户。
Lambda架构

在lambda架构中,主要包括离线数据层,实时处理层和服务层。在离线处理层部分将产生的数据存储到HDFS上,通过MapReduce进行离线处理,MapReduce将处理完的模型存储到Redis中,在实时处理部分SparkStreaming基于Kafka实时得到的数据写入redis并从redis中获得推荐结果。服务层通过restful完成推荐结果的呈现,将结果推荐给用户。
以上是关于HBaseFlumeNginxRedisKafka基础的主要内容,如果未能解决你的问题,请参考以下文章