快来看,快来看,关于Java集合,你想知道的,这里都有
Posted morning~
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了快来看,快来看,关于Java集合,你想知道的,这里都有相关的知识,希望对你有一定的参考价值。
大家好,我是Morning,在CSDN写文,分享一些Java基础知识,一些自己认为在学习过程中比较重要的东西,致力于帮助初学者入门,希望可以帮助你进步。感兴趣的欢迎关注博主,和博主一起学习Java知识。大家还可以去专栏查看之前的文章,希望未来能和大家共同探讨技术。
概述
我们为什么要学习集合呢?
说起集合就不得不说数组,那有数组了为什么还需要集合呢,当然是集合更加的强大了。
如果说我们需要保存一组一样(数据类型)的元素的时候,我们应该使用一个容器来存储,数组就是这样的一个容器,那么数组有什么缺点呢,数组最大的缺点就是它一旦定义,长度将无法改变,但是我们在实际的开发过程中,经常需要保存一些可变长度的数据集合,所以我们需要一些动态增长长度的容器来保存我们的数据。而我们需要对数据的保存的逻辑可能各种各样的,于是就有了各种各样的数据结构。Java中对于各种数据结构的实现,就是我们用到的集合
Java的集合框架是由很多的接口、抽象类,集体类组成的。
Java的集合类大体可以分为俩大类,分别是单列集合和双列集合。
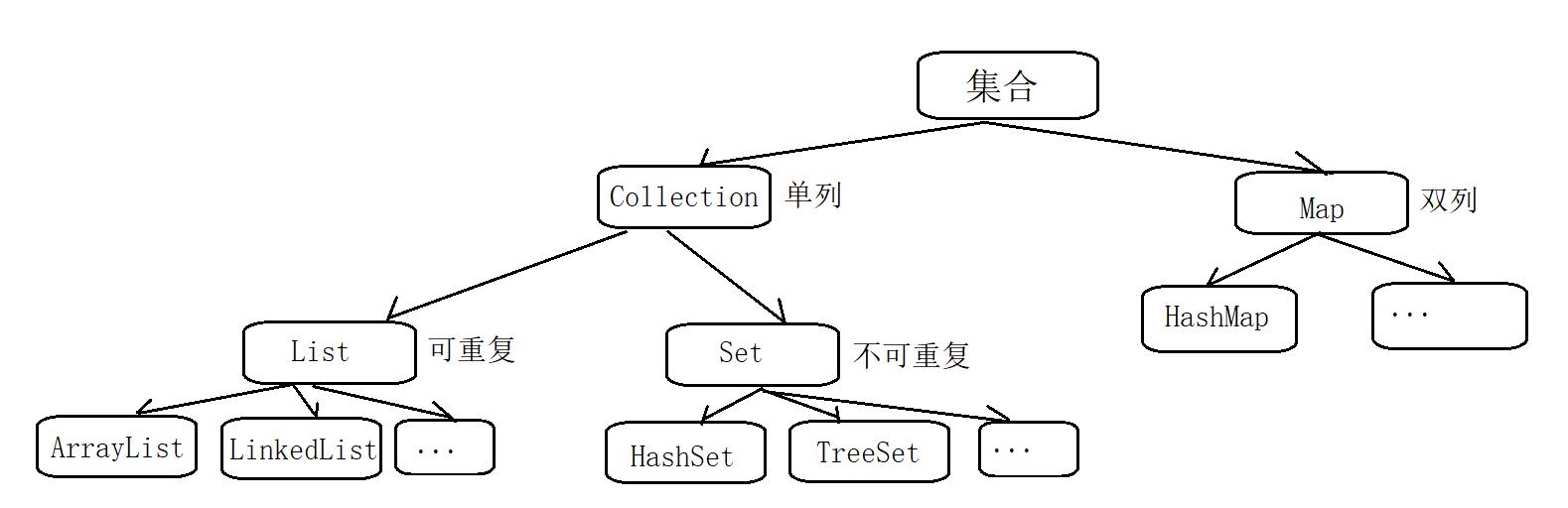
Collection接口
在Java类库中,集合类的基本接口是Collection,而实现这个类的都是单列集合。
这个接口有俩个基本方法(其他的方法功能都非常的明确,容易理解,在这里就不赘述了,大家感兴趣可以去看看网上的API文档):
public interface Collection<E> extends Iterable<E>
boolean add(E e);
Iterator<E> iterator();
add方法用于向集合中添加元素,如果集合因为添加元素改变了那就返回true,如果集合没改变就返回false,例如向Set中添加一个元素,而这个元素已经在集合中存在了,那就返回false,因为Set中不允许有重复的元素
iterator方法用于返回一个实现了Iterator接口的对象,使用这个迭代器对象可以依次访问集合中的元素。集合的遍历还有其他的三种方法:一种是我们熟悉的for循环,这种遍历方式支持增删,但是在增删的时候需要注意索引的变化,不然很可能漏掉一个元素;第二种是增强for循环,也就是for each,这种遍历方式不可以进行增删操作,如果一定要执行的话只能进行一次,而且还会报错,如果想执行一次增删操作还不想让它报错,可以使用break语句,让它停止遍历;还有一种是以流的方式遍历数组,这个可能大家有一点陌生,我用代码实现一下:
Collection<Integer> integerList = new ArrayList<Integer>();
integerList.add(0);
integerList.add(1);
integerList.add(2);
integerList.add(3);
integerList.add(4);
//以流的方式输出
integerList.stream().forEach((a)->System.out.println(a));
可以看到,流的方式其实也用到了forEach。
迭代器
上文中我们提到了使用一个迭代器对象可以依次访问集合中的元素,那我们就来讨论一下迭代器。
Iterator接口包含四个方法,我们可以看一下它的源码:
public interface Iterator<E>
boolean hasNext();
E next();
default void remove()
throw new UnsupportedOperationException("remove");
default void forEachRemaining(Consumer<? super E> action)
Objects.requireNonNull(action);
while (hasNext())
action.accept(next());
我们可以通过调用next方法,来访问集合中的元素,如果到了集合的末尾,next方法就会抛出一个NoSuchElementException,所以,通常我们在调用next方法之前会先调用hasNext方法,该方法可以判断迭代器对象中还有没有元素,如果有就返回true。具体实现如下:
先来看一种错误示例:

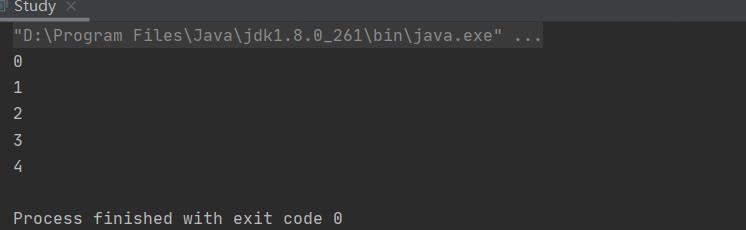
在调用next方法之前先调用hasNext方法:
public static void main(String[] args)
Collection<Integer> integerList = new ArrayList<Integer>();
integerList.add(0);
integerList.add(1);
integerList.add(2);
integerList.add(3);
integerList.add(4);
Iterator<Integer> it = integerList.iterator();
while (it.hasNext())
System.out.println(it.next());
就不会出错了:
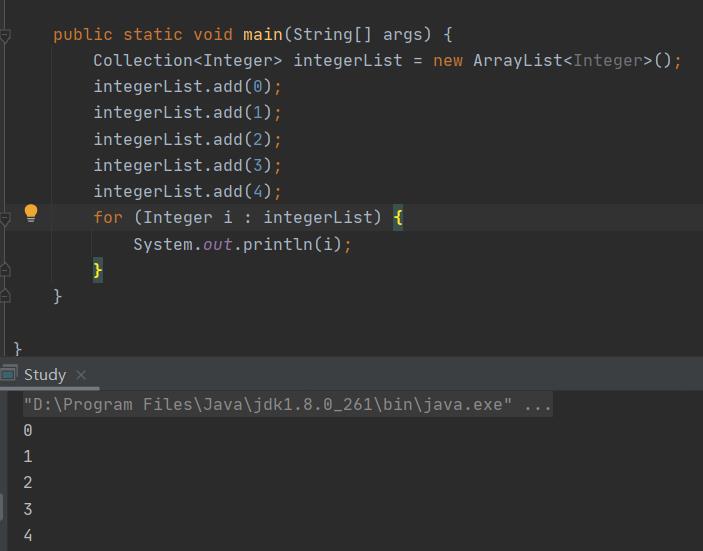
我们还可以使用for each更加简练的遍历它:
从最开始的Collection接口的源码可以看到,Collection接口扩展了Iterable接口,Iterable接口中只有一个抽象方法:
Iterator<T> iterator();
由于for each 循环可以处理任何实现了Iterable接口的对象,所以标准类库中的任何集合都可以用for each 循环。
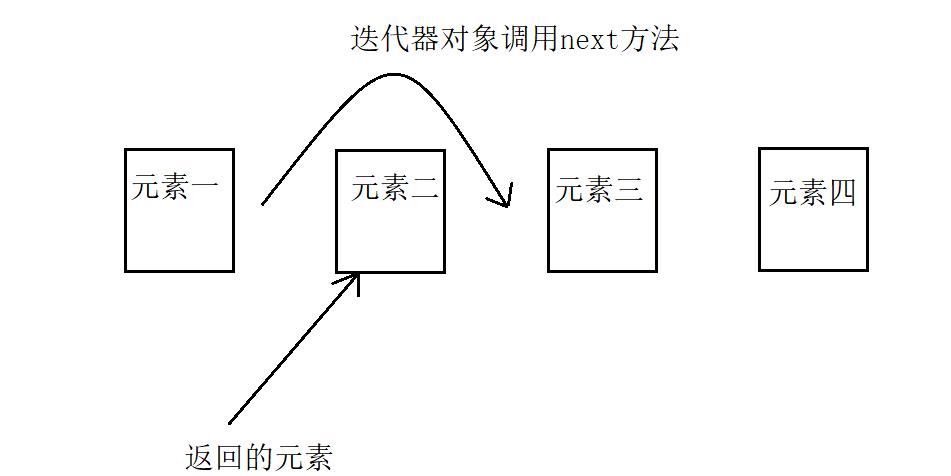
Java集合类库中的迭代器与其他类库中的迭代器在概念上有着重要的区别。在传统的集合类库中,例如,C++的标准模板库,迭代器是根据数组索引建模的。但是,Java迭代器并不是这样处理的。查找操作与位置变更紧密耦合。查找一个元素的唯一方法就是调用next,而在执行查找操作的同时,迭代器的位置就会随之向前移动。因此,可以认为Java迭代器位于俩个元素之间。当调用next时,迭代器就越过下一个元素,并返回刚刚越过的那个元素的引用。
——Java核心技术 卷一
Java迭代器(向后移动):
Iterator接口中还有一个remove方法,该方法会删除上次调用next方法时返回的那个元素,所以调用remove方法之前需要先调用next方法,先看一下这个元素,更重要的是,如果你在调用remove方法之前没有调用next方法,这是不合法的,会抛出一个异常:IllegalStateException

如果我们先调用一下next方法就不会出现这个问题了:

但是如果在上次访问之后集合发生了变化,那 remove 方法还是调用不成功:
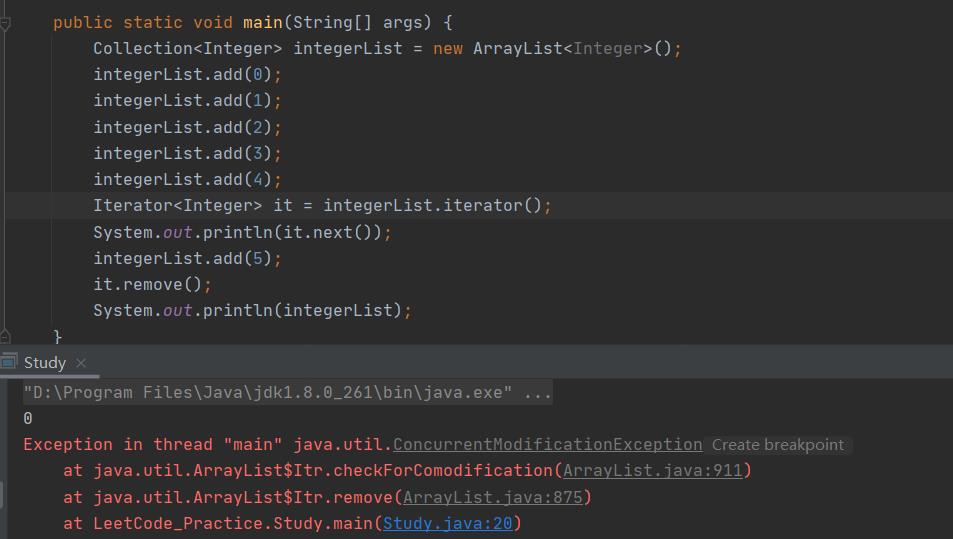
这里还有一个问题需要注意,我们发现Collection和Iterator接口,还有本文接下来要提到的具体集合类都是泛型接口,这里如果我们不给指定的类型的话,它会默认为Object类型。
List接口
public interface List<E> extends Collection<E>
//一些方法
List接口实现了Collection接口,是一个有序的集合,元素会增加到容器的特定位置,它可以使用一个整数的索引来访问,由于这样可以按任意顺序访问元素,所以这种方法叫做随机访问,这一点就与迭代器有差异,迭代器只能顺序的访问集合中的元素。List接口中的用于随机访问的方法有:
E get(int index); //拿到给定位置的元素
E set(int index, E element); //用一个新的元素替换给定位置的元素,并返回原来的元素
void add(int index, E element);//在给定位置添加一个元素
E remove(int index); //删除并返回给定位置的元素
ListIterator<E> listIterator(int index); //第一次调用这个迭代器的next方法会返回指定位置的元素
ListIterator接口是Iterator接口的一个子接口,它扩展了Iterator接口,它可以从后往前遍历集合。
public interface ListIterator<E> extends Iterator<E>
boolean hasPrevious(); //从后往前迭代时,判断前面还有没有元素,有就返回true
E previous(); //返回前一个元素
具体使用如下:

ArrayList
ArrayList实现了List接口,ArrayList封装了一个动态再分配的对象数组。底层是由数组实现的,数组实现的就有一个好处:查询快,但是随之而来就是它的缺点:删除数组中间的元素,或者在数组中间位置增加一个元素效率就会很低,因为要想在数组中间位置增加一个元素的话,就必须把增加位置之后的所有元素往后移一个位置。同理,如果你想要删除数组中间某个位置的元素,就必须把该位置之后的元素都向前移一个位置。所以效率就不太高。
还记得我们在本文开头讲的吗,集合,它可以动态的增长长度,接下来我们就看看它是如何动态增加长度的。

ArrayList类中定义了一个静态变量,注释说明默认初始化容量为10。如果你在创建集合对象时,不给定初始容量的话,这个集合的初始容量就为10。
在你添加元素时调用如下方法:
public boolean add(E e)
ensureCapacityInternal(size + 1);
elementData[size++] = e;
return true;
该方法第一行调用了一个ensureCapacityInternal方法,传入参数为当前集合内元素的数量加一,这个方法的作用就时判断这个集合的容量还允不允许我们再添加一个元素。
//add中调用这个方法
private void ensureCapacityInternal(int minCapacity)
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
//ensureCapacityInternal中调用这个方法
private void ensureExplicitCapacity(int minCapacity)
modCount++;
//如果集合中不能在添加一个元素的话
if (minCapacity - elementData.length > 0)
grow(minCapacity);
然后我们可以看到,当集合长度不够时,会调用grow方法,grow方法的源码如下:
private void grow(int minCapacity)
//拿到旧的数组长度
int oldCapacity = elementData.length;
//将旧的长度增加到1.5倍,拿到一个新的长度
int newCapacity = oldCapacity + (oldCapacity >> 1);
//判断特殊情况
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
//生成一个新的数组,这个新的数组是原来数组的1.5倍,将原来的数组内的元素放到新的数组中
elementData = Arrays.copyOf(elementData, newCapacity);
根据我写的注释,我相信大家一定都看懂了集合的扩容过程。最核心的方法就是这个grow方法。
看到这里大家有没有想到一个问题,如果说我在集合满了之后只需要再添加一个元素的话,那集合已经扩容到原来的1.5倍,会不会有一点浪费呢?其实这个问题是没有办法避免的,因为我们不可能在原来的长度基础上只增加一,如果这样的,满了之后每添加一个元素都需要扩容,这样的话就会影响性能,也不能增加的太多,所以就取了一个可以接受的长度(原来的1.5倍),所以这就体现了它的另一个缺点:有些情况下浪费空间
Vector
这个类也实现 List 接口,底层也是数组实现,那它和 ArrayList 有什么区别呢。
首先让我们看一下它的add方法:
public synchronized boolean add(E e)
modCount++;
ensureCapacityHelper(elementCount + 1);
elementData[elementCount++] = e;
return true;
这里就可以看到 Vector 与 ArrayList 最大的区别,Vector 的 add 方法是被 synchronized 关键字修饰的,而ArrayList的add方法没有,所以 Vector 是线程安全的,ArrayList 不是。还有值得一提的就是Vector扩容时,会扩到原来的2倍(这里就不给大家看源码了,和ArrayList大同小异),而ArrayList只是1.5倍。
Vector类的所有方法都是同步的,可以安全的从俩个线程访问一个Vector对象,但是,如果只从一个线程访问Vector,代码就会在同步操作上白白浪费大量时间,而与之不同,ArrayList方法不是同步的,因此,建议在不需要同步时使用ArrayList,而不要使用Vector。
——Java核心技术 卷一
LinkedList
LinkedList底层则与ArrayList和Vector不同,它使用的是另外一种数据结构——链表,我相信大家一定都了解,数组是在连续的存储位置上存放对象引用,而链表则是将每个对象存放在单独的链接中,每个链接中还存放着序列中下一个和上一个链接的引用。我们现在所说的LinkedList底层就是一个双向链表。

这种链表结构比数组结构最突出的优势就是,从链表中间删除一个元素是一个很轻松的操作,只需要修改所删除元素周围的链接就好,在链表中间添加一个元素也是如此。

LinkedList 源码我们就看一部分吧:
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
//一些方法
//将某个元素添加到链表的头部
private void addFirst(E e)
//具体实现
//将某个元素添加到链表的尾部
private void addLast(E e)
//具体实现
//得到链表头部的元素
private E getFirst()
//具体实现
//得到链表尾部的元素
private E getLast()
//具体实现
...
LinkedList类也是实现了List接口,让我们先来看LinkedList集合类中的add方法
//add方法
public boolean add(E e)
linkLast(e);
return true;
//add方法中调用的方法
void linkLast(E e)
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
LinkedList中的add方法会直接把元素加在链表的末尾。

上文中我们提到,在链表的中间添加一个元素很方便,那么如何在链表的中间添加一个元素呢?由于迭代器描述了集合中的位置,所以这种指定位置的add方法由迭代器负责。而 Iterator 接口中没有add方法,但是我们上文中提到过的 ListIterator 中包含add方法。
void add(E e);
这个add方法和LinkedList中的add方法不同,它是没有返回值的,它会认为调用这个add方法之后一定会改变链表。ListIterator中的add方法会在迭代器的位置之前添加一个新元素:
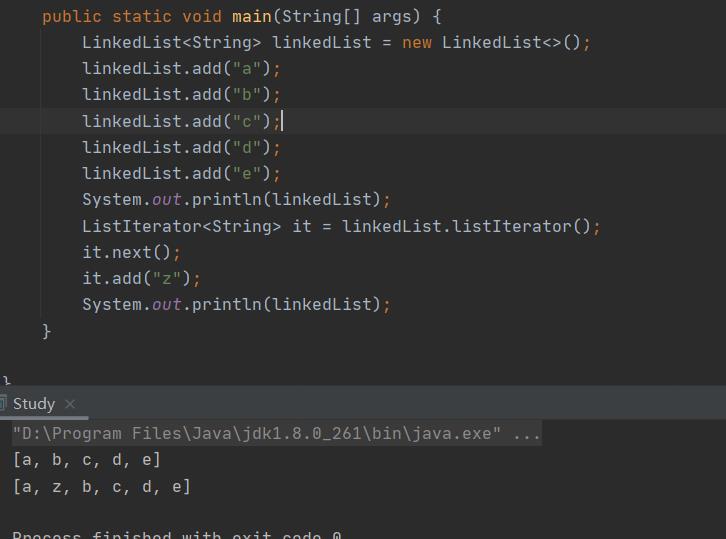
如果在调用add方法之前,没有调用next方法,那么新添加的这个元素会成为链表的表头。
好了,本次的分享到这里就结束了。如果大家对Set、Map感兴趣,可以关注博主🙏🙏🙏,博主会在日后给大家分享,和大家一起探讨。文中有什么不当的地方,欢迎大家在评论区指出,大家一起探讨、学习。🤞🤞🤞
参考书籍:Java核心技术 卷一(第11版)
以上是关于快来看,快来看,关于Java集合,你想知道的,这里都有的主要内容,如果未能解决你的问题,请参考以下文章