Mybatis源码分析之Cache二级缓存原理
Posted 竹山一叶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Mybatis源码分析之Cache二级缓存原理 相关的知识,希望对你有一定的参考价值。
一:Cache类的介绍
讲解缓存之前我们需要先了解一下Cache接口以及实现MyBatis定义了一个org.apache.ibatis.cache.Cache接口作为其Cache提供者的SPI(ServiceProvider Interface) ,所有的MyBatis内部的Cache缓存,都应该实现这一接口
Cache的实现类中,Cache有不同的功能,每个功能独立,互不影响,则对于不同的Cache功能,这里使用了装饰者模式实现。
看下cache的实现类,如下图:
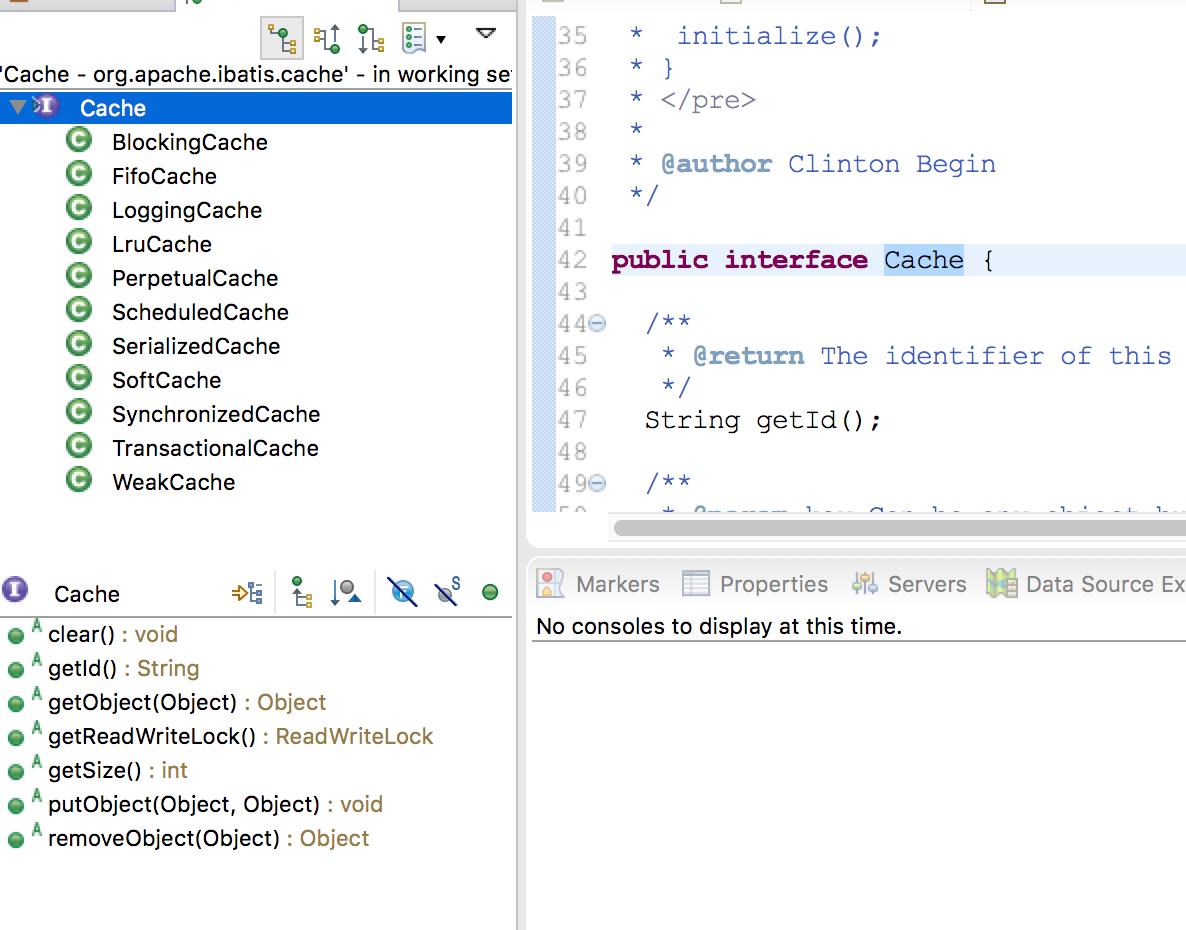
1.FIFOCache:先进先出算法 回收策略,装饰类,内部维护了一个队列,来保证FIFO,一旦超出指定的大小, 则从队列中获取Key并从被包装的Cache中移除该键值对。 2.LoggingCache:输出缓存命中的日志信息,如果开启了DEBUG模式,则会输出命中率日志。 3.LruCache:最近最少使用算法,缓存回收策略,在内部保存一个LinkedHashMap 4.ScheduledCache:定时清空Cache,但是并没有开始一个定时任务,而是在使用Cache的时候,才去检查时间是否到了。 5.SerializedCache:序列化功能,将值序列化后存到缓存中。该功能用于缓存返回一份实例的Copy,用于保存线程安全。 6.SoftCache:基于软引用实现的缓存管理策略,软引用回收策略,软引用只有当内存不足时才会被垃圾收集器回收 7.SynchronizedCache:同步的缓存装饰器,用于防止多线程并发访问 8.PerpetualCache 永久缓存,一旦存入就一直保持,内部就是一个HashMap 9.WeakCache:基于弱引用实现的缓存管理策略 10.TransactionalCache 事务缓存,一次性存入多个缓存,移除多个缓存 11.BlockingCache 可阻塞的缓存,内部实现是ConcurrentHashMap
二:二级缓存初始化
Mybatis默认对二级缓存是关闭的,一级缓存默认开启,如果需要开启只需在mapper上加入
二级缓存是怎么初始化的呢?
我们在之前的文章里面(Mybatis源码分析之SqlSessionFactory(一))分析了配置文件的加载,我们回到那边来找到二级缓存的加载地方,一开始我就说了“如果需要开启只需在mapper上加入
XMLConfigBuilder.parse()-->parseConfiguration(XNode root)-->mapperElement(root.evalNode("mappers"))-->
mapperElement(XNode parent)看下mapperElement的方法
private void mapperElement(XNode parent) throws Exception {
if (parent != null) {
for (XNode child : parent.getChildren()) {
if ("package".equals(child.getName())) {
String mapperPackage = child.getStringAttribute("name");
configuration.addMappers(mapperPackage);
} else {
String resource = child.getStringAttribute("resource");
String url = child.getStringAttribute("url");
String mapperClass = child.getStringAttribute("class");
if (resource != null && url == null && mapperClass == null) {
ErrorContext.instance().resource(resource);
InputStream inputStream = Resources.getResourceAsStream(resource);
XMLMapperBuilder mapperParser = new XMLMapperBuilder(inputStream, configuration, resource, configuration.getSqlFragments());
mapperParser.parse();
} else if (resource == null && url != null && mapperClass == null) {
ErrorContext.instance().resource(url);
InputStream inputStream = Resources.getUrlAsStream(url);
XMLMapperBuilder mapperParser = new XMLMapperBuilder(inputStream, configuration, url, configuration.getSqlFragments());
mapperParser.parse();
} else if (resource == null && url == null && mapperClass != null) {
Class mapperInterface = Resources.classForName(mapperClass);
configuration.addMapper(mapperInterface);
} else {
throw new BuilderException("A mapper element may only specify a url, resource or class, but not more than one.");
}
}
}
}
}这个时候我已经找到了mapper节点了,我们在看向前走
XMLMapperBuilder.mapperParser.parse()
代码如下
public void parse() {
if (!configuration.isResourceLoaded(resource)) {
configurationElement(parser.evalNode("/mapper"));
configuration.addLoadedResource(resource);
bindMapperForNamespace();
}
parsePendingResultMaps();
parsePendingChacheRefs();
parsePendingStatements();
}看到configurationElement(parser.evalNode("/mapper"));看到mapper节点了继续走
private void configurationElement(XNode context) {
try {
String namespace = context.getStringAttribute("namespace");
if (namespace == null || namespace.equals("")) {
throw new BuilderException("Mapper\'s namespace cannot be empty");
}
builderAssistant.setCurrentNamespace(namespace);
cacheRefElement(context.evalNode("cache-ref"));
cacheElement(context.evalNode("cache"));
parameterMapElement(context.evalNodes("/mapper/parameterMap"));
resultMapElements(context.evalNodes("/mapper/resultMap"));
sqlElement(context.evalNodes("/mapper/sql"));
buildStatementFromContext(context.evalNodes("select|insert|update|delete"));
} catch (Exception e) {
throw new BuilderException("Error parsing Mapper XML. Cause: " + e, e);
}
}到这里终于见到了他cacheElement(context.evalNode("cache"));
看源码
private void cacheElement(XNode context) throws Exception {
if (context != null) {
String type = context.getStringAttribute("type", "PERPETUAL");
Class typeClass = typeAliasRegistry.resolveAlias(type);
String eviction = context.getStringAttribute("eviction", "LRU");
Class evictionClass = typeAliasRegistry.resolveAlias(eviction);
Long flushInterval = context.getLongAttribute("flushInterval");
Integer size = context.getIntAttribute("size");
boolean readWrite = !context.getBooleanAttribute("readOnly", false);
boolean blocking = context.getBooleanAttribute("blocking", false);
Properties props = context.getChildrenAsProperties();
builderAssistant.useNewCache(typeClass, evictionClass, flushInterval, size, readWrite, blocking, props);
}
}终于找到了cacheElement读取,这里builderAssistant.useNewCache构建了一个二级缓存对象
public Cache useNewCache(Class typeClass,
Class evictionClass,
Long flushInterval,
Integer size,
boolean readWrite,
boolean blocking,
Properties props) {
Cache cache = new CacheBuilder(currentNamespace)
.implementation(valueOrDefault(typeClass, PerpetualCache.class))
.addDecorator(valueOrDefault(evictionClass, LruCache.class))
.clearInterval(flushInterval)
.size(size)
.readWrite(readWrite)
.blocking(blocking)
.properties(props)
.build();
configuration.addCache(cache);
currentCache = cache;
return cache;
}
创建完成后放入configuration对象configuration.addCache(cache),上面代码看到 addDecorator(valueOrDefault(evictionClass, LruCache.class))LruCache被装饰到里面了,

最后得到的对象是SynchronizedCache可以在.build()里面找到,他内部装饰设计模式。
三:缓存查数据
通过之前的文章我们知道Executor是执行查询的最终接口,它有两个实现类一个是BaseExecutor另外一个是CachingExecutor。
我看下CachingExecutor实现类里面的query查询方法
@Override
public List query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
throws SQLException {
Cache cache = ms.getCache();//二级缓存对象
if (cache != null) {
flushCacheIfRequired(ms);
if (ms.isUseCache() && resultHandler == null) {
ensureNoOutParams(ms, parameterObject, boundSql);
@SuppressWarnings("unchecked")
List list = (List) tcm.getObject(cache, key);//从缓存中读取
if (list == null) {
//这段走到一级缓存或者DB
list = delegate. query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
tcm.putObject(cache, key, list); // issue #578 and #116 //数据放入缓存
}
return list;
}
}
return delegate. query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}在这里我们看一个实例如下图

发现我们的二级缓存没有生效,这个是为什么呢?我们仔细分下源代码
仔细看CachingExecutor的query代码,在查询二级缓存的时候用的是tcm先去找TransactionalCache然后采取getObject。问题就在这里,但我们在一个事物里查询三次,第一次查数据库,这不必说,第二次以后会判断二级缓存时候有。第一次查询完了有这么一句。
tcm.putObject(cache, key, list);
跟进去看:
getTransactionalCache(cache).putObject(key, value);
getTransactionalCache(cache)返回TransactionalCache对象,然后调用它的put,是什么呢
@Override
public void putObject(Object key, Object object) {
entriesToRemoveOnCommit.remove(key);
entriesToAddOnCommit.put(key, new AddEntry(delegate, key, object));
}封装cache在一个addEntry对象中去了。
put方法不是保存数据到TransactionalCache,而是保存cache到entriesToAddOnCommit;那这个entriesToAddOnCommit干吗用的呢?
观察名字就知道是提交事务的时候需要用的。一个方法执行结束,事务提交,session提交,提交是层层调用的。最终调用到CachingExecutor的commit:
public void commit(boolean required) throws SQLException {
delegate.commit(required);
tcm.commit();
}tcm的commit:
public void commit() {
for (TransactionalCache txCache : transactionalCaches.values()) {
txCache.commit();
}
}把所有TransactionalCache提交,
public void commit() {
if (clearOnCommit) {
delegate.clear();
} else {
for (RemoveEntry entry : entriesToRemoveOnCommit.values()) {
entry.commit();
}
}
for (AddEntry entry : entriesToAddOnCommit.values()) {
entry.commit();
}
reset();
}AddEntry的commit方法:
public void commit() {
cache.putObject(key, value);
}就是把缓存数据放到二级缓存。
总结就是:
一个事务方法运行时,结果查询出来,缓存在一级缓存了,但是没有到二级缓存,事务cache只是保存了二级缓存的引用以及需要缓存的数据key和数据。当事务提交后,事务cache重置,之前保存的本该在二级缓存的数据在此刻真正放到二级缓存。
于是我们在这个方法中反复查询,二级缓存启用了却不能命中,只能返回一级缓存的数据。要想命中必须提交事务才行,第二个测试每次打开事务,查询,释放事务,在获得事务查询。所以二级缓存能命中。
我们调整下代码方法,把事物提交放到前面
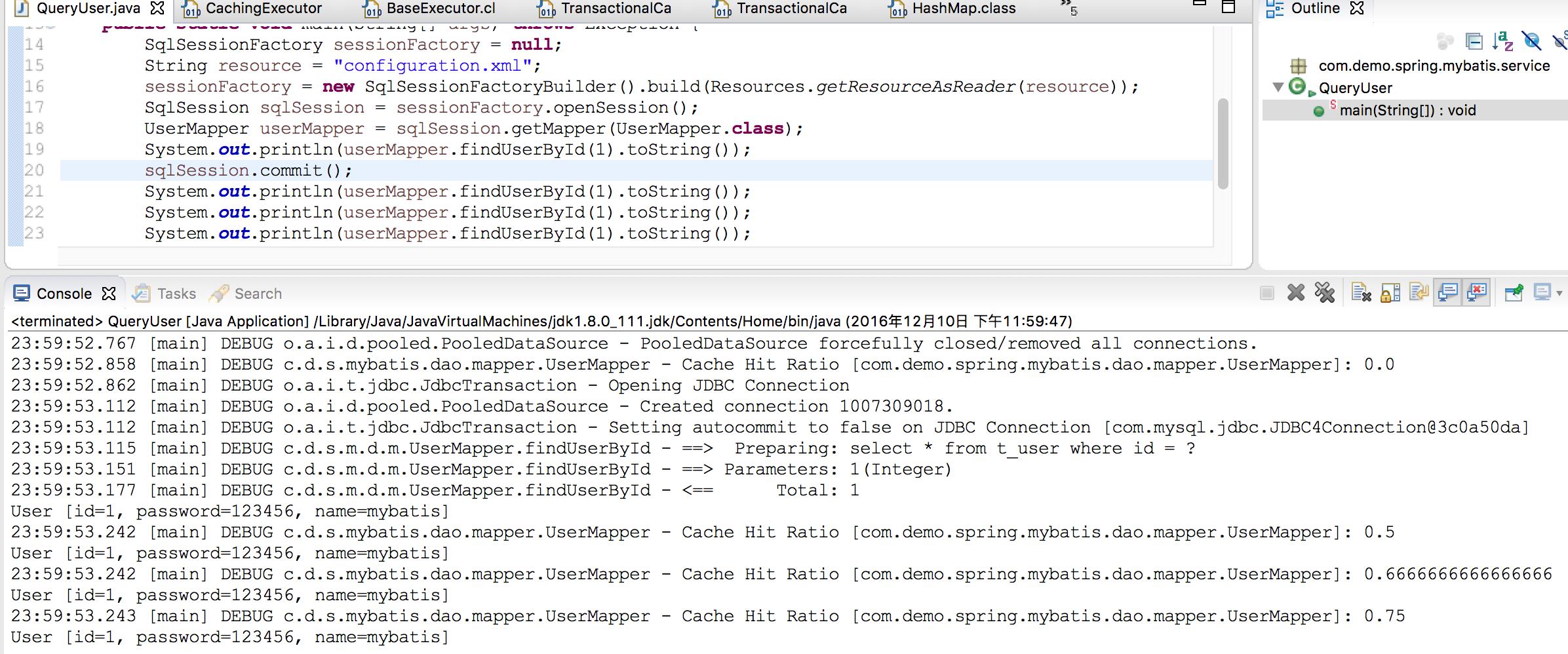
这下正常了
四:一级和二级缓存的先后顺序
二级缓存———> 一级缓存——> 数据库
五:使用二级缓存需要注意:
想要使用二级缓存时需要想好三个问题:
1)对该表的操作与查询都在同一个namespace下,其他的namespace如果有操作,就会发生数据过时。因为二级缓存是以namespace为单位的,不同namespace下的操作互不影响。
2)对关联表的查询,关联的所有表的操作都必须在同一个namespace。
3)不能直接操作数据库,否则数据查询结果会存在问题
总之,操作与查询在同一个namespace下的查询才能缓存,其他namespace下的查询都可能出现问题。
以上是关于Mybatis源码分析之Cache二级缓存原理 的主要内容,如果未能解决你的问题,请参考以下文章