19-flink-1.10.1-Table API 和 Flink SQL 的 函数
Posted 逃跑的沙丁鱼
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了19-flink-1.10.1-Table API 和 Flink SQL 的 函数相关的知识,希望对你有一定的参考价值。
目录
2.4 表聚合函数(Table AggregateFunction)
1 函数
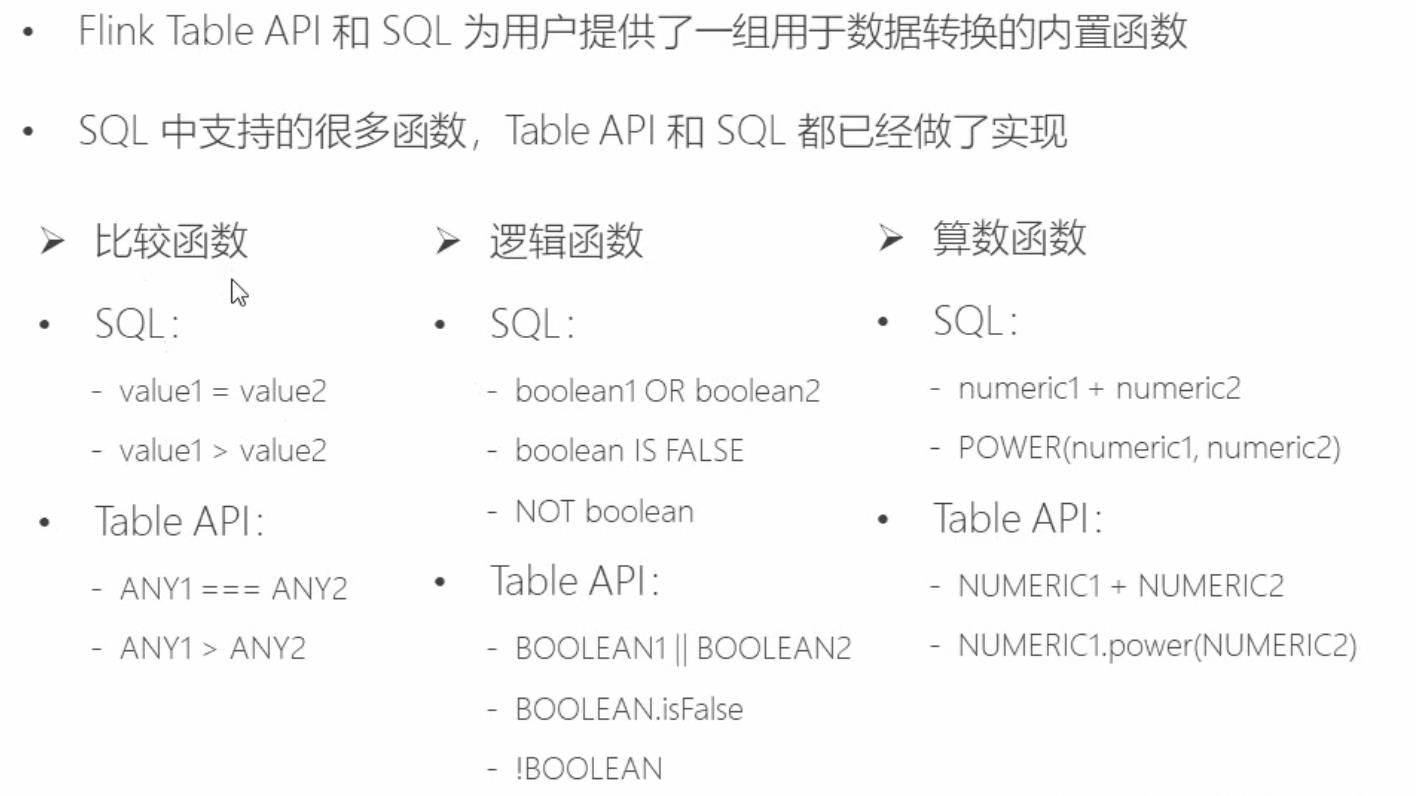
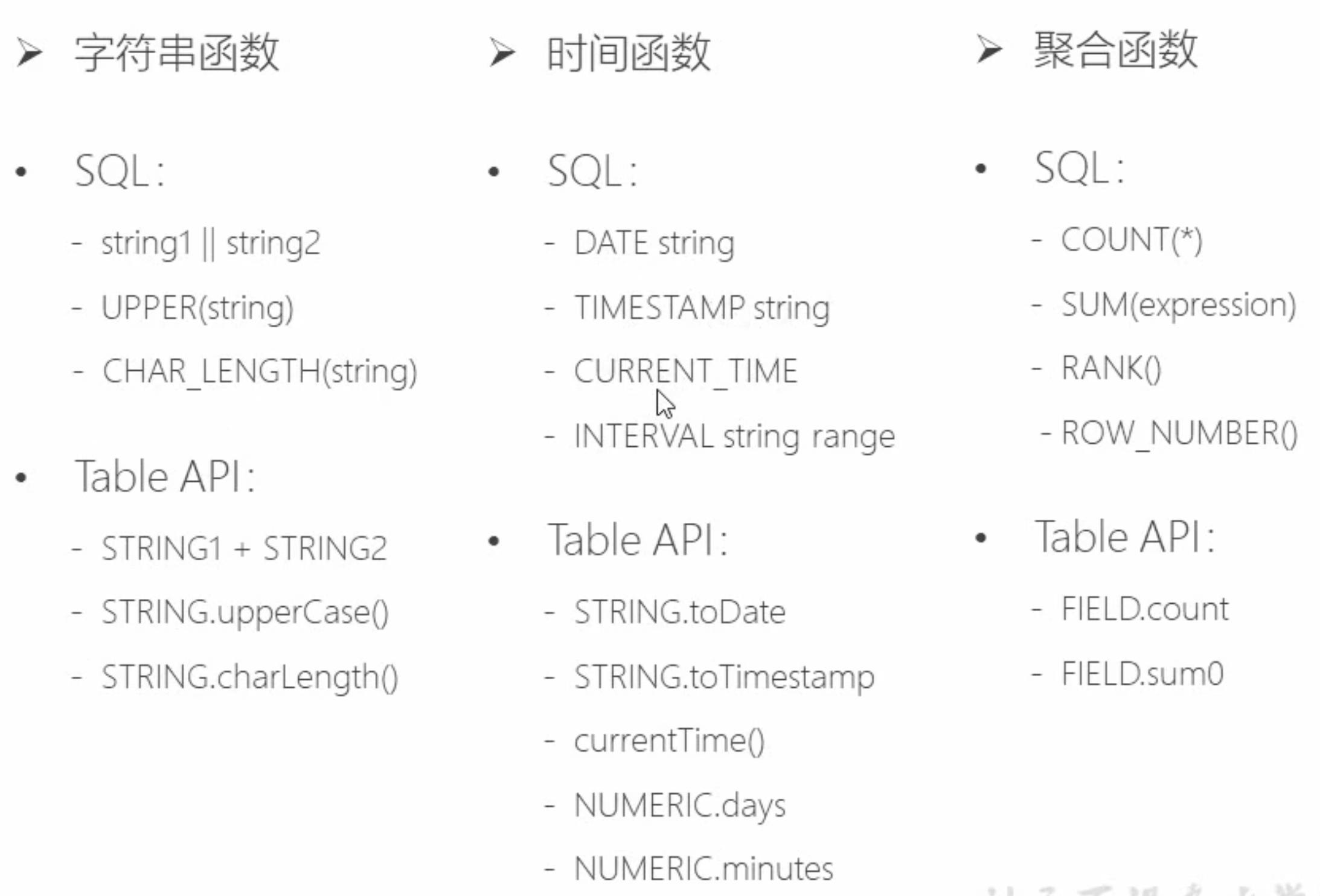
2 用户自定义函数(UDF)
 2.1 标量函数(Scalar Function)
2.1 标量函数(Scalar Function)
一对一

package com.study.liucf.table.udf
import com.study.liucf.bean.LiucfSensorReding
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.table.api.EnvironmentSettings, Table
import org.apache.flink.table.api.scala._
import org.apache.flink.table.functions.ScalarFunction
import org.apache.flink.types.Row
object LiucfTableUDFDemo
def main(args: Array[String]): Unit =
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
// env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime)
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
val inputStream: DataStream[String] = env.readTextFile("src\\\\main\\\\resources\\\\sensor.txt")
val inputDataStream: DataStream[LiucfSensorReding] = inputStream.map(r =>
val arr = r.split(",")
LiucfSensorReding(arr(0), arr(1).toLong, arr(2).toDouble)
).assignTimestampsAndWatermarks(
new BoundedOutOfOrdernessTimestampExtractor[LiucfSensorReding](Time.seconds(1))
override def extractTimestamp(element: LiucfSensorReding): Long = element.timestamp *1000
)
//定义表环境
val settings = EnvironmentSettings.newInstance()
.useBlinkPlanner()
.inStreamingMode()
.build()
val tableEnv = StreamTableEnvironment.create(env, settings)
//基于流创建一张表
// val flinkTable: Table = tableEnv.fromDataStream(inputDataStream,'id,'timestamp,'temperature,'pt.proctime)
val flinkTable: Table = tableEnv
.fromDataStream(inputDataStream, 'id, 'timestamp, 'temperature, 'timestamp.rowtime as 'tr)
// 使用自定义UDF函数
//先new 一个udf 实例
val hashCode = new HashCode(5)
// 1 在table api 里的应用
val hashCodeTableAPI: Table = flinkTable.select('id, 'tr, 'temperature, hashCode('id))
hashCodeTableAPI.toAppendStream[Row].print("hashCodeTableAPI")
// 2 在 table sql 里的应用
tableEnv.createTemporaryView("flinkTable_view",flinkTable)
tableEnv.registerFunction("hashCode",hashCode)
val hashCodeTableSql = tableEnv.sqlQuery("select id,tr,temperature,hashCode(id) as hashCode_id from flinkTable_view")
hashCodeTableSql.toAppendStream[Row].print("hashCodeTableSql")
env.execute("LiucfTableUDFDemo")
/**
*
* @param 权重种子
*/
class HashCode(factor:Int) extends ScalarFunction
/**
* 注意:这个函数是自定义的,不是重写的,但是名字还必须叫eval
* str 是传入的数据字段,
* Int 是返回值的类型
* @param str
* @return
*/
def eval(str:String):Int=
str.hashCode * factor -10000
2.2 表函数(Table Function)
一对多

package com.study.liucf.table.udf
import com.study.liucf.bean.LiucfSensorReding
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.table.api.EnvironmentSettings, Table
import org.apache.flink.table.api.scala._
import org.apache.flink.table.functions.TableFunction
import org.apache.flink.types.Row
object LiucfSTableUDFDemo
def main(args: Array[String]): Unit =
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
// env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime)
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
val inputStream: DataStream[String] = env.readTextFile("src\\\\main\\\\resources\\\\sensor.txt")
val inputDataStream: DataStream[LiucfSensorReding] = inputStream.map(r =>
val arr = r.split(",")
LiucfSensorReding(arr(0), arr(1).toLong, arr(2).toDouble)
).assignTimestampsAndWatermarks(
new BoundedOutOfOrdernessTimestampExtractor[LiucfSensorReding](Time.seconds(1))
override def extractTimestamp(element: LiucfSensorReding): Long = element.timestamp *1000
)
//定义表环境
val settings = EnvironmentSettings.newInstance()
.useBlinkPlanner()
.inStreamingMode()
.build()
val tableEnv = StreamTableEnvironment.create(env, settings)
//基于流创建一张表
// val flinkTable: Table = tableEnv.fromDataStream(inputDataStream,'id,'timestamp,'temperature,'pt.proctime)
val flinkTable: Table = tableEnv
.fromDataStream(inputDataStream, 'id, 'timestamp as 'timestamp_t, 'temperature, 'timestamp.rowtime as 'tr)
// 使用自定义UDF函数
val liucfSplit = new LiucfSplit("_")
// 1 table api 中的使用,我要把flinkTable这个表和调用了自定义函数生成的新表做一个侧向链接
val resultTable : Table = flinkTable
.joinLateral(liucfSplit('id) as ('word,'word_length,'word_hashcode)) // 连接的字段取别名'word,'word_length,'word_hashcode
// 然后resultTable就可以进行各种table 操作了
resultTable.printSchema()
resultTable.toRetractStream[Row].print("resultTable")
// 2 table sql 中的使用
tableEnv.createTemporaryView("flinkTable_view",flinkTable)
tableEnv.registerFunction("liucfSplit",liucfSplit)
/**
* lateral table( liucfSplit(id) ) as liucfSplit_table(word,word_length,word_hashcode)
* lateral table:侧连接
* liucfSplit(id):根据传入的id按照liucfSplit函数里的方法进行拆分,
* as liucfSplit_table:拆分的字表取个别名
* (word,word_length,word_hashcode):拆分的子表里的字段
* select:select 里面的字段可以根据需要从 (word,word_length,word_hashcode)里面选着
*/
val resultSqlTable: Table = tableEnv.sqlQuery(
"""
|select
| id,
| timestamp_t,
| temperature,
| tr,
| word,
| word_length,
| word_hashcode
|from flinkTable_view,lateral table( liucfSplit(id) ) as liucfSplit_table(word,word_length,word_hashcode)
|""".stripMargin)
// 然后resultSqlTable就可以进行各种table 操作了
resultSqlTable.printSchema()
resultSqlTable.toAppendStream[Row].print("resultSqlTable")
env.execute("LiucfTableUDFDemo")
/**
* 自定义TableFunction
* 输入一个字段输出一张表
* (String,Int,Long):返回表字段类型
* 我这个函数的作用是对输入的字符串使用分隔符切分,然后输出(切割后的部分,切割后的字符串长度,切割后的字符串的hashcode)
* @param separator 分隔符
*/
class LiucfSplit(separator:String) extends TableFunction[(String,Int,Long)]
/**
* 自定义函数eval,注意名称必须叫eval.
* 这个函数没有返回值,返回的数据是通过collect()返回出去的。
* @param str
*/
def eval(str:String):Unit=
val arr = str.split(separator)
arr.foreach(w=>collect(w,w.length,w.hashCode))
2.3 聚合函数 (AggregateFunction)
多对一


package com.study.liucf.table.udf
import com.study.liucf.bean.LiucfSensorReding
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.table.api.EnvironmentSettings, Table
import org.apache.flink.table.api.scala._
import org.apache.flink.table.functions.AggregateFunction
import org.apache.flink.types.Row
object LiucfAggregateUDFDemo
def main(args: Array[String]): Unit =
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
// env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime)
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
val inputStream: DataStream[String] = env.readTextFile("src\\\\main\\\\resources\\\\sensor.txt")
val inputDataStream: DataStream[LiucfSensorReding] = inputStream.map(r =>
val arr = r.split(",")
LiucfSensorReding(arr(0), arr(1).toLong, arr(2).toDouble)
).assignTimestampsAndWatermarks(
new BoundedOutOfOrdernessTimestampExtractor[LiucfSensorReding](Time.seconds(1))
override def extractTimestamp(element: LiucfSensorReding): Long = element.timestamp *1000
)
//定义表环境
val settings = EnvironmentSettings.newInstance()
.useBlinkPlanner()
.inStreamingMode()
.build()
val tableEnv = StreamTableEnvironment.create(env, settings)
//基于流创建一张表
// val flinkTable: Table = tableEnv.fromDataStream(inputDataStream,'id,'timestamp,'temperature,'pt.proctime)
val flinkTable: Table = tableEnv
.fromDataStream(inputDataStream, 'id, 'timestamp as 'timestamp_t, 'temperature, 'timestamp.rowtime as 'tr)
//1 table api 方式
val liucfAvgtemp = new LiucfAvgtemp()
val aggregatedTable = flinkTable
.groupBy("id")
.aggregate(liucfAvgtemp('temperature) as 'avgTemp)
.select('id,'avgTemp)
aggregatedTable.printSchema()
aggregatedTable.toRetractStream[Row].print("aggregatedTable")
// 2 table sql 方式
tableEnv.createTemporaryView("flinkTable_view",flinkTable)
tableEnv.registerFunction("liucfAvgtemp",liucfAvgtemp)
val aggregatedSqlTable = tableEnv.sqlQuery(
"""
|select
| id,
| liucfAvgtemp(temperature) as avgTemperature
|from flinkTable_view
|group by id
|""".stripMargin)
aggregatedSqlTable.toRetractStream[Row].print("aggregatedSqlTable")
env.execute("LiucfAggregateUDFDemo")
class AvgTempAc
var sum = 0.0
var count = 0
//自定义一个聚合函数求每个传感器的平均值,保存状态(tempSum,tempCount)
class LiucfAvgtemp extends AggregateFunction[Double,AvgTempAc]
// 返回结果在这里定义,并处理就可以了
override def getValue(accumulator: AvgTempAc): Double = if(accumulator.count==0) 0 else accumulator.sum / accumulator.count
// 创建一个状态
override def createAccumulator(): AvgTempAc = new AvgTempAc()
/**
* 还需要定义一个具体处理函数,修改保存的状态
* @param accumulator 要保存的状态
* @param temp 传入新采集到的新温度值
*/
def accumulate(accumulator: AvgTempAc,temp:Double): Unit =
accumulator.sum += temp
accumulator.count += 1
2.4 表聚合函数(Table AggregateFunction)
多对多
top N 场景使用
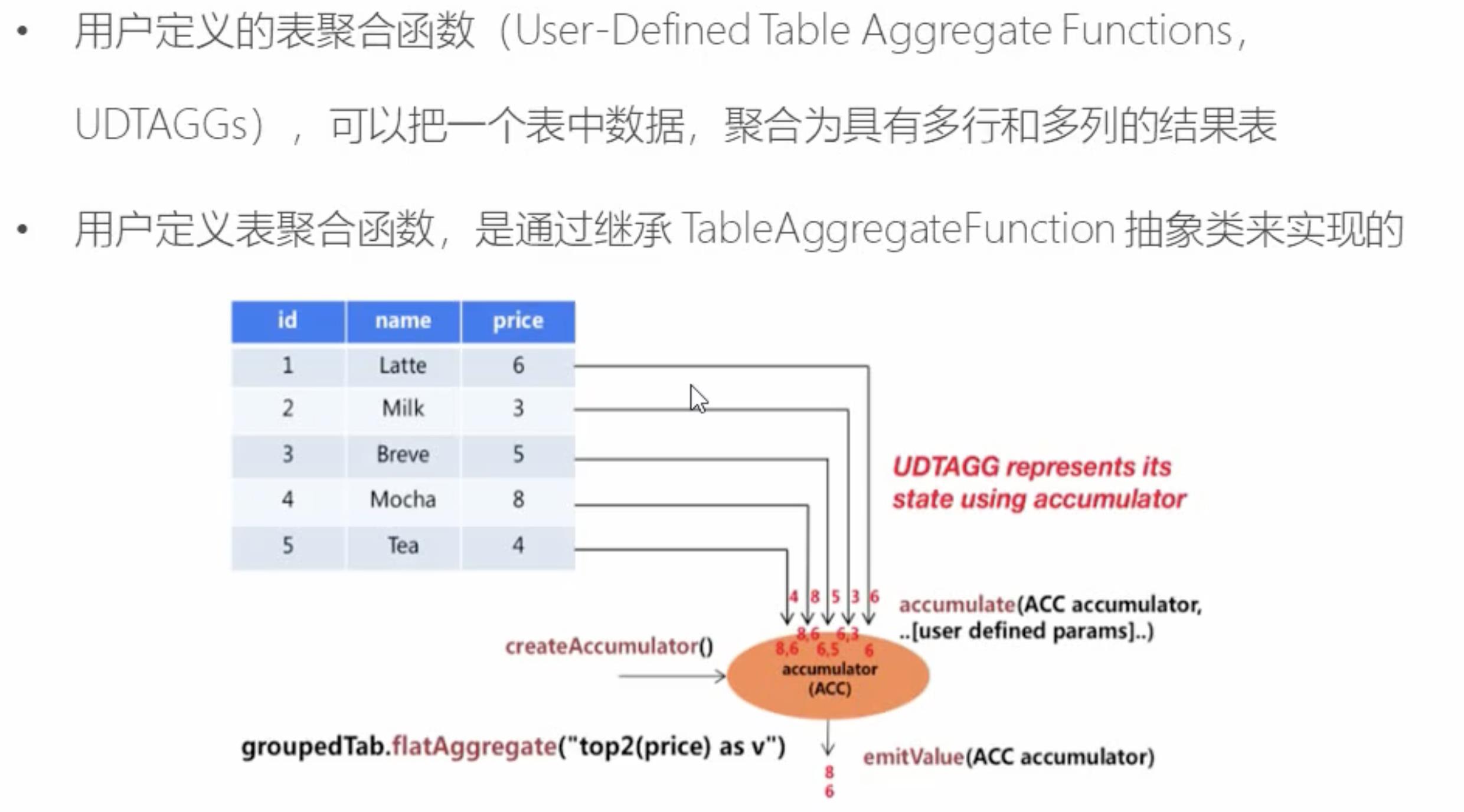

package com.study.liucf.table.udf
import com.study.liucf.bean.LiucfSensorReding
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.table.api.EnvironmentSettings, Table
import org.apache.flink.table.api.scala._
import org.apache.flink.table.functions.TableAggregateFunction
import org.apache.flink.types.Row
import org.apache.flink.util.Collector
object LiucfTableAggregateUDFDemo
def main(args: Array[String]): Unit =
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
// env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime)
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
val inputStream: DataStream[String] = env.readTextFile("src\\\\main\\\\resources\\\\sensor.txt")
val inputDataStream: DataStream[LiucfSensorReding] = inputStream.map(r =>
val arr = r.split(",")
LiucfSensorReding(arr(0), arr(1).toLong, arr(2).toDouble)
).assignTimestampsAndWatermarks(
new BoundedOutOfOrdernessTimestampExtractor[LiucfSensorReding](Time.seconds(1))
override def extractTimestamp(element: LiucfSensorReding): Long = element.timestamp *1000
)
//定义表环境
val settings = EnvironmentSettings.newInstance()
.useBlinkPlanner()
.inStreamingMode()
.build()
val tableEnv = StreamTableEnvironment.create(env, settings)
//基于流创建一张表
// val flinkTable: Table = tableEnv.fromDataStream(inputDataStream,'id,'timestamp,'temperature,'pt.proctime)
val flinkTable: Table = tableEnv
.fromDataStream(inputDataStream, 'id, 'timestamp as 'timestamp_t, 'temperature, 'timestamp.rowtime as 'tr)
val liucfTableAggregateTop3 = new LiucfTableAggregateTop3()
//1 table api 方式
val tableApiRes: Table = flinkTable
.groupBy('id)
.flatAggregate(liucfTableAggregateTop3('temperature) as ('temp,'rang))
.select('id,'temp,'rang)
tableApiRes.toRetractStream[Row].print("tableApiRes")
//2 table sql 方式 不容易实现,这里不演示了
env.execute("LiucfTableAggregateUDFDemo")
// 定义一个类用来专门保存状态
class TempTop3Acc
var firstTemp=Double.MinValue
var secondTemp=Double.MinValue
var thirsTemp=Double.MinValue
// 自定义聚合函数,提取每个传感器温度值最高的三个温度
class LiucfTableAggregateTop3 extends TableAggregateFunction[(Double,Int),TempTop3Acc]
//创建一个状态实例
override def createAccumulator(): TempTop3Acc = new TempTop3Acc()
/**
* 还需要定义一个具体处理函数,修改保存的状态
* @param accumulator 要保存的状态
* @param temp 传入新采集到的新温度值
*/
def accumulate(accumulator: TempTop3Acc,temp:Double): Unit =
if(accumulator.firstTemp<temp)
accumulator.thirsTemp = accumulator.secondTemp
accumulator.secondTemp=accumulator.firstTemp
accumulator.firstTemp=temp
else if(accumulator.secondTemp<temp)
accumulator.thirsTemp=accumulator.secondTemp
accumulator.secondTemp=temp
else if(accumulator.thirsTemp<temp)
accumulator.thirsTemp = temp
// 把结果返回出去,通过这个方法实现的
def emitValue(accumulator: TempTop3Acc,out:Collector[(Double,Int)]): Unit =
out.collect((accumulator.firstTemp,1))
out.collect((accumulator.secondTemp,2))
out.collect((accumulator.thirsTemp,3))
以上是关于19-flink-1.10.1-Table API 和 Flink SQL 的 函数的主要内容,如果未能解决你的问题,请参考以下文章