Python入门自学进阶——11-协程
Posted kaoa000
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python入门自学进阶——11-协程相关的知识,希望对你有一定的参考价值。
协程,又叫做微线程,纤程。Coroutine。协程是一种用户态的轻量级线程。
协程拥有自己的寄存器上下文和栈,调度切换时,将寄存器上下文和栈保存,在切换回来时,恢复寄存器山下文和栈。协程能保留上一次调用时的状态(即所有局部状态的一个特定组合),每次重入时,就相当于进入上一次调用的状态,也就是进入上一次离开时所处的逻辑流的位置。
协程的优点:
- 无需线程上下文切换的开销
- 无需原子操作锁定及同步的开销
- 方便切换控制流,简化编程模型
- 高并发+高扩展性+低成本:一个CPU支持上万的协程都不成问题,适合用于高并发处理。
协程的缺点:
- 无法利用多核资源:协程本质是个单线程,不能同时将单个CPU的多个核用上,需要与进程配合才能运行在多CPU上。
- 进行阻塞(Blocking)操作(如IO时)会阻塞掉整个程序。
def consumer(name):
print('----->%s into baozi shop...'%name)
while True:
new_baozi = yield
print('[%s] is eating baozi %s' %(name,new_baozi))
def producer():
next(con)
next(con2)
n = 0
while n < 5:
n += 1
print("\\033[32;1m[producer]\\033[0m is making baozi %s " % n)
con.send(n)
con2.send(n)
if __name__ == '__main__':
con = consumer('c1') #创建一个生成器对象con
con2 = consumer('c2') #又创建一个生成器对象con2
p = producer() #执行producer函数,p是函数的返回值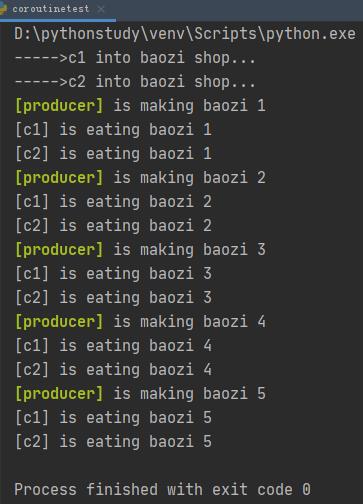
这里,两个生成器对象con和con2,类似于两个线程,程序在两个生成器之间切换执行。
对上述程序进行以下修改,使其更符合吃包子的实际,顾客要有名字,还有要要吃的包子数:
def consumer(name,n): #顾客姓名和要吃的包子数
print('----->%s into baozi shop,want to eat %s baozis...'%(name,n))
new_baozi = 0
while new_baozi < n:
new_baozi = yield
print('[%s] is eating baozi %s' %(name,new_baozi))
def producer():
next(con)
next(con2)
n = 0
while True:
n += 1
if len(con_list) == 0:
return
print("\\033[32;1m[producer]\\033[0m is making baozi %s " % n)
for i in range(con_list.__len__()):
try:
con_list[i].send(n)
except Exception as e:
del(con_list[i])
if __name__ == '__main__':
con = consumer('c1',5) #创建一个生成器对象con
con2 = consumer('c2',3) #又创建一个生成器对象con2
con_list = []
con_list.append(con)
con_list.append(con2)
producer() #执行producer函数,p是函数的返回值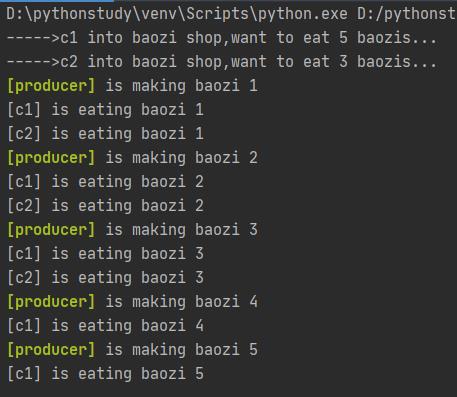
通过引入greenlet包进行协程开发:
from greenlet import greenlet
def test1():
print(12)
gr2.switch()
print(34)
gr2.switch()
def test2():
print(56)
gr1.switch()
print(78)
gr1 = greenlet(test1) #生成一个greenlet对象,类似生成器对象:
# <greenlet.greenlet object at 0x00000000004A3BF8 (otid=0x000000000050D268) pending>
gr2 = greenlet(test2)
gr1.switch() #switch方法类似next或send方法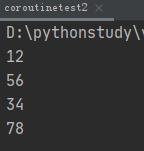
结果看出,程序在test1和test2之间切换执行。
通过gevent第三方库开发协程,通过gevent能实现并发同步或异步编程,主要是IO阻塞时切换:
import gevent
import time
def foo():
print('Running in foo',time.ctime())
gevent.sleep(1)
print('Explicit context switch to foo again',time.ctime())
def bar():
print('Explicit context to bar',time.ctime())
gevent.sleep(2)
print('Implicit context switch back to bar',time.ctime())
gevent.joinall([ #这里的函数进行协程切换,模拟并行
gevent.spawn(foo),
gevent.spawn(bar),
])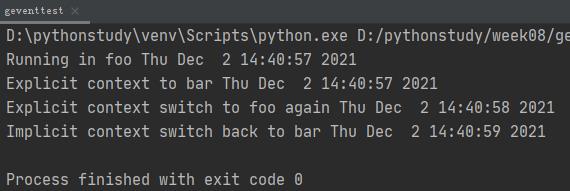
看时间,foo的第一个print和bar的第一个print是并行的,然后暂停1秒,foo的第二个print打印,再经过1秒,bar的第二个print打印。原来串行需要3秒,现在2秒运行完毕。gevent.sleep()用来模拟IO阻塞。这里不能用time模块的sleep(),因为这个sleep()是使CPU空闲,类似真实的IO阻塞,会造成线程或进程的切换,而协程是一个线程,所以不会因为time.sleep()切换。
简单的爬网页模拟程序,测试gevent协程的效果:
import gevent
from urllib.request import urlopen #一个库,用于网页操作
import time
def openweb(url):
print('GET:%s'%url)
resp = urlopen(url) #打开对应的网址,生成结果对象
#resp是一个Response对象,<http.client.HTTPResponse object atxxx >
data = resp.read()
print('%d bytes received from %s.' %(len(data),url))
l = ['https://www.python.org/','https://www.yahoo.com/','https://www.sohu.com/','https://www.sina.com/']
starttime = time.time()
# for url in l:
# openweb(url) #串行操作,操作完一个网站,再到下一个
gevent.joinall([
gevent.spawn(openweb,'https://www.python.org/'),
gevent.spawn(openweb,'https://www.yahoo.com/'),
gevent.spawn(openweb,'https://www.sohu.com/'),
gevent.spawn(openweb,'https://www.sina.com/'),
]) #协程并行操作,在访问一个网站时阻塞,切换到下一个,并行访问多个网站
print(time.time() - starttime)在windows系统下,效果并不是太明显,这是因为windows对IO阻塞的监控问题,解决方法:
import gevent
from urllib.request import urlopen #一个库,用于网页操作
import time
from gevent import monkey
monkey.patch_all() #加快协程的切换
def openweb(url):
print('GET:%s'%url)
resp = urlopen(url) #打开对应的网址,生成结果对象
#resp是一个Response对象,<http.client.HTTPResponse object atxxx >
data = resp.read()
print('%d bytes received from %s.' %(len(data),url))
l = ['https://www.python.org/','https://www.yahoo.com/','https://www.sohu.com/','https://www.sina.com/']
starttime = time.time()
# for url in l:
# openweb(url) #串行操作,操作完一个网站,再到下一个
gevent.joinall([
gevent.spawn(openweb,'https://www.python.org/'),
gevent.spawn(openweb,'https://www.yahoo.com/'),
gevent.spawn(openweb,'https://www.sohu.com/'),
gevent.spawn(openweb,'https://www.sina.com/'),
]) #协程并行操作,在访问一个网站时阻塞,切换到下一个,并行访问多个网站
print(time.time() - starttime)引入monkey模块,使用patch_all()方法。
以上是关于Python入门自学进阶——11-协程的主要内容,如果未能解决你的问题,请参考以下文章