C++内存管理全景指南
Posted 贺二公子
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了C++内存管理全景指南相关的知识,希望对你有一定的参考价值。
原文地址:https://mp.weixin.qq.com/s/YPIe4Nz_QASSiXqOgnFqnQ
导语 深入理解C++内存管理,一文了解所有C++内存问题,万字长文,建议收藏
随着人工智能,云计算等技术的迅猛发展,让Python,go等新兴语言流行了起来,很多人以为C++可能已经过时了,确实,C++编程语言走到今天已经有将近40年的历史了,但它依然是当今的主流语言,我们可以看一下世界权威编程语言排行榜,C++依然是属于第一梯队,C++在金融交易系统,游戏,数据库,编译器,大型桌面程序,高性能服务器,浏览器,各类编程比赛(ACM-ICPC,Topcoder,Codeforces,Google Code Jam)等领域任然是主力军。
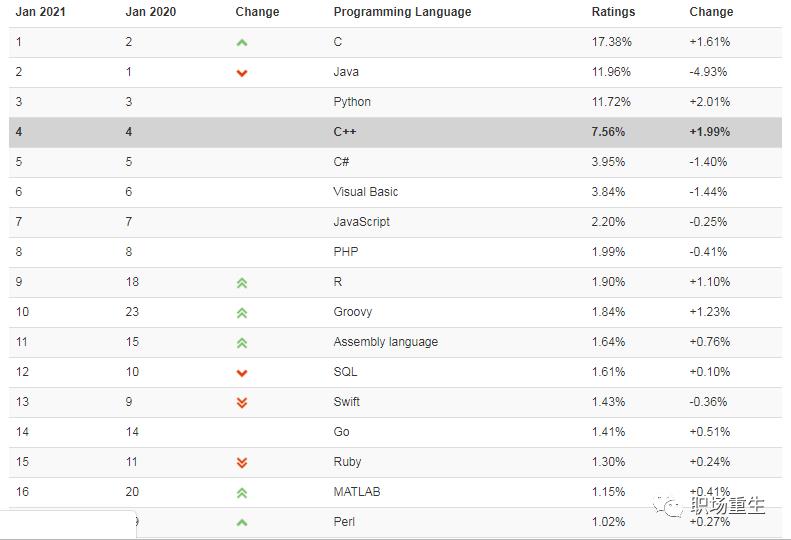
在各个大厂情况,C++也是很多大厂主力编程语言,国外google和微软大部分核心产品都是基于C++开发的;鹅厂编程语言TOP5,C++排第一:

C++的高抽象层次,又兼具高性能,是其他语言所无法替代的,C++标准保持稳定发展,更加现代化,更加强大,更加易用,熟练的 C++ 工程师自然也获得了“高水平、高薪资”的名声,但在各种活跃编程语言中,C++门槛依然很高,尤其C++的内存问题(内存泄露,内存溢出,内存宕机,堆栈破坏等问题),需要理解C++标准对象模型,C++标准库,标准C库,操作系统等内存设计,才能更加深入理解C++内存管理,这是跨越C++三座大山之一,我们必须拿下它。
Content
欢迎微信搜索「职场重生」,关注公众号「职场重生」,后续更多精彩内容发布;

环境:
uname -a
Linux alexfeng 3.19.0-15-generic #15-Ubuntu SMP Thu Apr 16 23:32:37 UTC 2015 x86_64 x86_64 x86_64 GNU/Linux
cat /proc/cpuinfo
bugs :
bogomips : 4800.52
clflush size : 64
cache_alignment : 64
address sizes : 36 bits physical, 48 bits virtual
cat /proc/meminfo
MemTotal: 4041548 kB(4G)
MemFree: 216304 kB
MemAvailable: 2870340 kB
Buffers: 983360 kB
Cached: 1184008 kB
SwapCached: 54528 kB
GNU gdb (Ubuntu 7.9-1ubuntu1) 7.9
g++ (Ubuntu 4.9.2-10ubuntu13) 4.9.2
一 C++内存模型
C++11在标准库中引入了memory model,这应该是C++11最重要的特性之一了。C++11引入memory model的意义在于我们可以在high level language层面实现对在多处理器中多线程共享内存交互的控制。我们可以在语言层面忽略compiler,CPU arch的不同对多线程编程的影响了。我们的多线程可以跨平台。
内存模型
为 C++ 定义计算机内存存储的语义。可用于 C++ 程序的内存是一或多个相接的字节序列。内存中的每个字节拥有唯一的地址。
字节
字节是最小的可寻址内存单元。它被定义为相接的位序列,大到足以保有任何 UTF-8 编码单元( 256 个相异值)和 (C++14 起)基本执行字符集(要求为单字节的 96 个字符)的任何成员。类似 C , C++ 支持 8 位或更大的字节。char 、 unsigned char 和 signed char 类型把一个字节用于存储和值表示。字节中的位数可作为 CHAR_BIT 或 std::numeric_limits::digits 访问。
内存位置
内存位置是
- 一个标量类型(算术类型、指针类型、枚举类型或 std::nullptr_t )对象
- 或非零长位域的最大相接序列
注意:各种语言特性,例如引用和虚函数,可能涉及到程序不可访问,但为实现所管理的额外内存位置。
线程与数据竞争
- 执行线程是程序中的控制流,它始于 std::thread::thread 、 std::async 或以其他方式所做的顶层函数调用。
- 任何线程都能潜在地访问程序中的任何对象(拥有自动或线程局域存储期的对象仍可为另一线程通过指针或引用访问)。
- 始终允许不同的执行线程同时访问(读和写)不同的内存位置,而无冲突或同步要求。
一个表达式的求值写入内存位置,而另一求值读或写同一内存位置时,称这些表达式冲突。拥有二个冲突求值的程序有数据竞争,除非
- 两个求值都在同一线程上,或同一信号处理函数中执行,或
- 两个冲突求值都是原子操作(见 std::atomic ),或
- 一个冲突求值先发生于( happens-before )另一个(见内存顺序–std::memory_order )
若出现数据竞争,则程序的行为未定义。
内存顺序(std::memory_order)
如果不使用任何同步机制(例如 mutex 或 atomic),在多线程中读写同一个变量,那么程序的结果是难以预料的。简单来说,编译器以及 CPU 的一些行为,会影响到C++程序的执行结果
- 即使是简单的语句,C++ 也不保证是原子操作。
- CPU 可能会调整指令的执行顺序。
- 在 CPU cache 的影响下,一个 CPU 执行了某个指令,不会立即被其它 CPU 看见。
- Intel x86, x86-64等属于强排序CPU,x86-64的强内存模型总能保证按顺序执行,遵从数据依赖顺序,但PowerPC和ARM是弱排序CPU,有时需要依赖内存栅栏指令。
多线程读写同一变量需要使用同步机制,最常见的同步机制就是std::mutex和std::atomic。然而从性能角度看,通常使用std::atomic会获得更好的性能.
C++11 提供6 种可以应用于原子变量的内存次序:
- momory_order_relaxed,
- memory_order_consume,
- memory_order_acquire,
- memory_order_release,
- memory_order_acq_rel,
- memory_order_seq_cst
虽然共有 6 个选项,但它们表示的是四种内存模型:
- Relaxed ordering
- Release-Acquire ordering
- Release-Consume ordering
- Sequentially-consistent ordering
顺序一致次序(sequential consistent ordering)
对应memory_order_seq_cst. SC作为默认的内存序,是因为它意味着将程序看做是一个简单的序列。如果对于一个原子变量的操作都是顺序一致的,那么多线程程序的行为就像是这些操作都以一种特定顺序被单线程程序执行。从同的角度来看,一个顺序一致的 store 操作 synchroniezd-with 一个顺序一致的需要读取相同的变量的 load 操作。除此以外,顺序模型还保证了在 load 之后执行的顺序一致原子操作都得表现得在 store 之后完成。非顺序一致内存次序(non-sequentially consistency memory ordering)强调对同一事件(代码),不同线程可以以不同顺序去执行,不仅是因为编译器可以进行指令重排,也因为不同的 CPU cache 及内部缓存的状态可以影响这些指令的执行。但所有线程仍需要对某个变量的连续修改达成顺序一致。
松弛次序(relaxed ordering)
在这种模型下,std::atomic的load()和store()都要带上memory_order_relaxed参数。Relaxed ordering 仅仅保证load()和store()是原子操作,除此之外,不提供任何跨线程的同步。
获取-释放次序(acquire-release ordering)
在这种模型下,store()使用memory_order_release,而load()使用memory_order_acquire。这种模型有两种效果,第一种是可以限制 CPU 指令的重排:
- 在store()之前的所有读写操作,不允许被移动到这个store()的后面。
- 在load()之后的所有读写操作,不允许被移动到这个load()的前面。
数据依赖(Release-Consume ordering)
memory_order_consume 是 acquire-release 顺序模型中的一种,但它比较特殊,它为 inter-thread happens-before 引入了数据依赖关系:dependency-ordered-before ,一个使用memory_order_consume的操作具有消费语义(consume semantics)。我们称这个操作为消费操作(consume operations),对于memory_order_consume最的价值的观察结果就是总是可以安全的将它替换成memory_order_acquire,消费和获取都为了同一个目的:帮助非原子信息在线程间安全的传递。就像获取操作一样,消费操作必须与另一个线程的释放操作一起使用。它们之间主要的区别在于消费操作可以正确起作用的案例更少。相对于它的使用不便,反过来也就意味着消费操作在某些平台使用更有效。

默认情况下,std::atomic使用的是 Sequentially-consistent ordering。但在某些场景下,合理使用其它三种 ordering,可以让编译器优化生成的代码,从而提高性能。
思考问题:
1. C++正常程序可以访问到哪些内存和不能访问到哪些内存(这些内存属于该程序)?
2. 内存对程序并发执行有什么影响?
3. std::memory_order 的作用是什么?
二 C++对象内存模型
1 空类对象(一般作为模板的tag来使用)
class A ;
sizeof(A) = 1
C++标准要求C++的对象大小不能为0,C++对象必须在内存里面有唯一的地址,
但又不想浪费太多内存空间,所以标准规定为1byte,
2 非空类
class A
public:
int a;
;
sizeof(A ) = 8 ,align=8

3 非空虚基类
class A
public:
int a;
virtual void v();
;
sizeof(A ) = 16 ,align=8

4 单继承
class A
public:
int a;
virtual void v();
;
class B : public A
public:
int b;
;
sizeof(B) = 16, align = 8

5 简单多继承
class A
public:
int a;
virtual void v();
;
class B
public:
int b;
virtual void w();
;
class C : public A, public B
public:
int c;
;
sizeof(C) = 32 ,align = 8

6 简单多继承-2
class A
public:
int a;
virtual void v();
;
class B
public:
int b;
virtual void w();
;
class C : public A, public B
public:
int c;
void w();
;
sizeof(C) = 32 ,align = 8

7 The Diamond: 多重继承 (没有虚继承)
class A
public:
int a;
virtual void v();
;
class B : public A
public:
int b;
virtual void w();
;
class C : public A
public:
int c;
virtual void x();
;
class D : public B, public C
public:
int d;
virtual void y();
;
sizeof(D) = 40 align = 8

注意点:此种继承存在两份基类成员,使用时候需要指定路径,不方便,易出错。
8 The Diamond: 钻石类虚继承
解决上面的问题,让基类只有存在一份,共享基类;
class A
public:
int a;
virtual void v();
;
class B : public virtual A
public:
int b;
virtual void w();
;
class C : public virtual A
public:
int c;
virtual void x();
;
class D : public B, public C
public:
int d;
virtual void y();
;
sizeof(D) = 48,align = 8

注意点:
- top_offset 表示this指针对子类的偏移,用于子类和继承类之间dynamic_cast转换(还需要typeinfo数据),实现多态,vbase_offset 表示this指针对基类的偏移,用于共享基类;
- gcc为了每一个类生成一个vtable虚函数表,放在程序的.rodata段,其他编译器(平台)比如vs,实现不太一样.
- gcc还有VTT表,里面存放了各个基类之间虚函数表的关系,最大化利用基类的虚函数表,专门用来为构建最终类vtable;
- 在构造函数里面设置对象的vtptr指针。
- 虚函数表地址的前面设置了一个指向type_info的指针,RTTI(Run Time Type Identification)运行时类型识别是由编译器在编译器生成的特殊类型信息,包括对象继承关系,对象本身的描述,RTTI是为多态而生成的信息,所以只有具有虚函数的对象才会生成。
- 在C++类中有两种成员数据:static、nonstatic;三种成员函数:static、nonstatic、virtual。 C++成员非静态数据需要占用动态内存,栈或者堆中,其他static数据存在全局变量区(数据段),编译时候确定。虚函数会增加用虚函数表大小,也是存储在数据区的.rodada段,编译时确定,其他函数不占空间。
- G++选项 -fdump-class-hierarchy 可以生成C++类层结构,虚函数表结构,VTT表结构。
- GDB调试选项:
set p obj <on/off> :在C++中,如果一个对象指针指向其派生类, 如果打开这个选项,GDB会现在类对象结构的规则显示输出。
set p pertty <on/off>: 按照层次打印结构体。
思考问题:
- Why don’t we have virtual constructors?
From Bjarne Stroustrup’s C++ Style and Technique FAQ
A virtual call is a mechanism to get work done given partial information. In particular, “virtual” allows us to call a function knowing only any interfaces and not the exact type of the object. To create an object you need complete information. In particular, you need to know the exact type of what you want to create. Consequently, a “call to a constructor” cannot be virtual. - 为什么不要在构造函数或者析构函数中调用虚函数?
对于构造函数:此时子类的对象还没有完全构造,编译器会去虚函数化,只会用当前类的函数, 如果是纯虚函数,就会调用到纯虚函数,会导致构造函数抛异常:pure virtual method called;对于析构函数:同样,由于对象不完整,编译器会去虚函数化,函数调用本类的虚函数,如果本类虚函数是纯虚函数,就会导致析构函数抛出异常: pure virtual method called; - C++对象构造顺序?
- 构造子类构造函数的参数
- 子类调用基类构造函数
- 基类设置vptr
- 基类初始化列表内容进行构造
- 基类函数体调用
- 子类设置vptr
- 子类初始化列表内容进行构造
- 子类构造函数体调用
- 为什么虚函数会降低效率?
是因为虚函数调用执行过程中会跳转两次,首先找到虚函数表,然后再查找对应函数地址,这样CPU指令就会跳转两次,而普通函数指跳转一次,CPU每跳转一次,预取指令都可能作废,这会导致分支预测失败,流水线排空,所以效率会变低。设想一下,如果说不是虚函数,那么在编译时期,其相对地址是确定的,编译器可以直接生成jmp/invoke指令;如果是虚函数,多出来的一次查找vtable所带来的开销,倒是次要的,关键在于,这个函数地址是动态的,譬如 取到的地址在eax里,则在call eax之后的那些已经被预取进入流水线的所有指令都将失效。流水线越长,一次分支预测失败的代价也就越大。
三 C++程序运行内存空间模型
1. C++程序大致运行内存空间:
32位:

64位:

2 Linux虚拟内存内部实现

关键点:
1. 各个分区的意义
-
内核空间:在32位系统中,Linux会留1G空间给内核,用户进程是无法访问的,用来存放进程相关数据和内存数据,内核代码等;在64位系统里面,Linux会采用最低48位来表示虚拟内存,这可通过 /proc/cpuinfo 来查看address sizes :
- address sizes : 36 bits physical, 48 bits virtual,总的虚拟地址空间为256TB( 2^48 ),在这256TB的虚拟内存空间中, 0000000000000000 - 00007fffffffffff(128TB)为用户空间,ffff800000000000 - ffffffffffffffff(128TB)为内核空间。目前常用的分配设计:
| Virtual memory map with 4 level page tables: | |
|---|---|
| 0000000000000000 - 00007fffffffffff (=47 bits) | user space, different per mmhole caused by [47:63] sign extension |
| ffff800000000000 - ffff87ffffffffff (=43 bits) | guard hole, reserved for hypervisor |
| ffff880000000000 - ffffc7ffffffffff (=64 TB) | direct mapping of all phys. memory |
| ffffc80000000000 - ffffc8ffffffffff (=40 bits) | hole |
| ffffc90000000000 - ffffe8ffffffffff (=45 bits) | vmalloc/ioremap space |
| ffffe90000000000 - ffffe9ffffffffff (=40 bits) | hole |
| ffffea0000000000 - ffffeaffffffffff (=40 bits) | virtual memory map (1TB) |
| … unused hole … | |
| ffffec0000000000 - fffffbffffffffff (=44 bits) | kasan shadow memory (16TB) |
| … unused hole … | |
| vaddr_end for KASLR | |
| fffffe0000000000 - fffffe7fffffffff (=39 bits) | cpu_entry_area mapping |
| fffffe8000000000 - fffffeffffffffff (=39 bits) | LDT remap for PTI |
| ffffff0000000000 - ffffff7fffffffff (=39 bits) | %esp fixup stacks |
| … unused hole … | |
| ffffffef00000000 - fffffffeffffffff (=64 GB) | EFI region mapping space |
| … unused hole … | |
| ffffffff80000000 - ffffffff9fffffff (=512 MB) | kernel text mapping, from phys 0 |
| ffffffffa0000000 - fffffffffeffffff (1520 MB) | module mapping space |
| [fixmap start] - ffffffffff5fffff | kernel-internal fixmap range |
| ffffffffff600000 - ffffffffff600fff (=4 kB) | legacy vsyscall ABI |
| ffffffffffe00000 - ffffffffffffffff (=2 MB) | unused hole |
http://www.kernel.org/doc/Documentation/x86/x86_64/mm.txt
- 剩下的是用户内存空间:
- stack栈区:专门用来实现函数调用-栈结构的内存块。相对空间下(可以设置大小,Linux 一般默认是8M,可通过 ulimit –s 查看),系统自动管理,从高地址往低地址,向下生长。
- 内存映射区:包括文件映射和匿名内存映射, 应用程序的所依赖的动态库,会在程序执行时候,加载到内存这个区域,一般包括数据(data)和代码(text);通过mmap系统调用,可以把特定的文件映射到内存中,然后在相应的内存区域中操作字节来访问文件内容,实现更高效的IO操作;匿名映射,在glibc中malloc分配大内存的时候会用到匿名映射。这里所谓的“大”表示是超过了MMAP_THRESHOLD 设置的字节数,它的缺省值是 128 kB,可以通过 mallopt() 去调整这个设置值。还可以用于进程间通信IPC(共享内存)。
- heap堆区:主要用于用户动态内存分配,空间大,使用灵活,但需要用户自己管理,通过brk系统调用控制堆的生长,向高地址生长。
- BBS段和DATA段:用于存放程序全局数据和静态数据,一般未初始化的放在BSS段(统一初始化为0,不占程序文件的空间),初始化的放在data段,只读数据放在rodata段(常量存储区)。
- text段:主要存放程序二进制代码。
2. 为了防止内存被攻击,比如栈溢出攻击和堆溢出攻击等,Linux在特定段之间使用随机偏移,使段的起始地址是随机值, Linux 系统上的ASLR 等级可以通过文件 /proc/sys/kernel/randomize_va_space 来进行设置,它支持以下取值:
- 0 - 关闭的随机化。一切都是静止的。
- 1 - 保守的随机化。共享库、栈、mmap()、VDSO以及堆将被随机化。
- 2 - 完全的随机化。除了上面列举的要素外,通过 brk() 分配得到的内存空间也将被随机化。
3. 每个段都有特定的安全控制(权限):
| vm_flags | 第三列,如r-xp | 此段虚拟地址空间的属性。每种属性用一个字段表示,r表示可读,w表示可写,x表示可执行,p和s共用一个字段,互斥关系,p表示私有段,s表示共享段,如果没有相应权限,则用’-’代替 |
4 Linux虚拟内存是按页分配,每页大小为4KB或者2M,1G等(大页内存), 默认是4K;
5 例子-通过pmap 查看程序内存布局(综合proc/x/maps与proc/x/smaps数据):
#include<iostream>
#include <unistd.h>
using namespace std;
//long a[1024*1024] = 0;
int main()
void *heap;
int *x = new int[1024]();
cout << hex <<"x: " << x <<endl;
heap = sbrk(0);
//cout << hex << "a:" << (long) &a <<endl;
cout << hex << "heap: " << (long) heap <<endl;
cout << hex << "heap: " << (long)heap - (long)x <<endl;
while(1);
return 0;
g++ -g -std=c++11 -o main mem.cpp
./main
关闭内存地址随机化
pmap -X 8117
8117: ./main
Address Perm Offset Device Inode Size Rss Pss Referenced Anonymous Swap Locked Mapping
00400000 r-xp 00000000 08:11 43014235 4 4 4 4 0 0 0 main
00601000 r--p 00001000 08:11 43014235 4 4 4 4 4 0 0 main
00602000 rw-p 00002000 08:11 43014235 4 4 4 4 4 0 0 main
//程序的text段,只读数据段,和全局/静态数据段;
00603000 rw-p 00000000 00:00 0 136 8 8 8 8 0 0 [heap]
//程序的堆内存段;
7ffff71e2000 r-xp 00000000 08:11 266401 88 88 18 88 0 0 0 libgcc_s.so.1
7ffff71f8000 ---p 00016000 08:11 266401 2044 0 0 0 0 0 0 libgcc_s.so.1
7ffff73f7000 rw-p 00015000 08:11 266401 4 4 4 4 4 0 0 libgcc_s.so.1
7ffff73f8000 r-xp 00000000 08:11 266431 1052 224 3 224 0 0 0 libm-2.21.so
7ffff74ff000 ---p 00107000 08:11 266431 2044 0 0 0 0 0 0 libm-2.21.so
7ffff76fe000 r--p 00106000 08:11 266431 4 4 4 4 4 0 0 libm-2.21.so
7ffff76ff000 rw-p 00107000 08:11 266431 4 4 4 4 4 0 0 libm-2.21.so
7ffff7700000 r-xp 00000000 08:11 266372 1792 1152 8 1152 0 0 0 libc-2.21.so
7ffff78c0000 ---p 001c0000 08:11 266372 2048 0 0 0 0 0 0 libc-2.21.so
7ffff7ac0000 r--p 001c0000 08:11 266372 16 16 16 16 16 0 0 libc-2.21.so
7ffff7ac4000 rw-p 001c4000 08:11 266372 8 8 8 8 8 0 0 libc-2.21.so
7ffff7ac6000 rw-p 00000000 00:00 0 16 12 12 12 12 0 0
7ffff7aca000 r-xp 00000000 08:11 46146360 960 856 283 856 0 0 0 libstdc++.so.6.0.20
7ffff7bba000 ---p 000f0000 08:11 46146360 2048 0 0 0 0 0 0 libstdc++.so.6.0.20
7ffff7dba000 r--p 000f0000 08:11 46146360 32 32 32 32 32 0 0 libstdc++.so.6.0.20
7ffff7dc2000 rw-p 000f8000 08:11 46146360 8 8 8 8 8 0 0 libstdc++.so.6.0.20
7ffff7dc4000 rw-p 00000000 00:00 0 84 16 16 16 16 0 0
7ffff7dd9000 r-xp 00000000 08:11 266344 144 144 1 144 0 0 0 ld-2.21.so
//程序的内存映射区,主要是动态库加载到该内存区,包括动态库的text代码段和数据data段。
//中间没有名字的,属于程序的匿名映射段,主要提供大内存分配。
7ffff7fd4000 rw-p 00000000 00:00 0 20 20 20 20 20 0 0
7ffff7ff5000 rw-p 00000000 00:00 0 12 12 12 12 12 0 0
7ffff7ff8000 r--p 00000000 00:00 0 8 0 0 0 0 0 0 [vvar]
7ffff7ffa000 r-xp 00000000 00:00 0 8 4 0 4 0 0 0 [vdso]
//vvar page,kernel的一些系统调用的数据会映射到这个页面,用户可以直接在用户空间访问;
//vDSO -virtual dynamic shared object,is a small shared library exported by the kernel to accelerate the execution of certain system calls that do not necessarily have to run in kernel space, 就是内核实现了glibc的一些系统调用,然后可以直接在用户空间执行,提高系统调用效率和减少与glibc的耦合。
7ffff7ffc000 r--p 00023000 08:11 266344 4 4 4 4 4 0 0 ld-2.21.so
7ffff7ffd000 rw-p 00024000 08:11 266344 4 4 4 4 4 0 0 ld-2.21.so
7ffff7ffe000 rw-p 00000000 00:00 0 4 4 4 4 4 0 0
7ffffffde000 rw-p 00000000 00:00 0 136 8 8 8 8 0 0 [stack]
//此段为程序的栈区
ffffffffff600000 r-xp 00000000 00:00 0 4 0 0 0 0 0 0 [vsyscall]
//此段是Linux实现vsyscall系统调用vsyscall库代码段
===== ==== === ========== ========= ==== ======
12744 2644 489 2644 172 0 0 KB
思考问题:
1 栈为什么要由高地址向低地址扩展,堆为什么由低地址向高地址扩展?
- 历史原因:在没有MMU的时代,为了最大的利用内存空间,堆和栈被设计为从两端相向生长。那么哪一个向上,哪一个向下呢?人们对数据访问是习惯于向上的,比如你在堆中new一个数组,是习惯于把低元素放到低地址,把高位放到高地址,所以堆 向上生长比较符合习惯, 而栈则对方向不敏感,一般对栈的操作只有PUSH和pop,无所谓向上向下,所以就把堆放在了低端,把栈放在了高端. 但现在已经习惯这样了。这个和处理器设计有关系,目前大多数主流处理器都是这样设计,但ARM 同时支持这两种增长方式。
2 如何查看进程虚拟地址空间的使用情况?
3 对比堆和栈优缺点?加粗样式
四 C++栈内存空间模型
C++程序运行调用栈示意图:

函数调用过程中,栈(有俗称堆栈)的变化:

from https://zhuanlan.zhihu.com/p/25816426
- 当主函数调用子函数的时候:
- 在主函数中,将子函数的参数按照一定调用约定(参考调用约定),一般是从右向左把参数push到栈中;
- 然后把下一条指令地址,即返回地址(return address)push入栈(隐藏在call指令中);
- 然后跳转到子函数地址处执行:call 子函数;此时
- 子函数执行:
- push %rbp : 把当前rbp的值保持在栈中;
- mov %rsp, %rbp:把rbp移到最新栈顶位置,即开启子函数的新帧;
- [可选]sub $xxx, %esp: 在栈上分配XXX字节的临时空间。(抬高栈顶)(编译器根据函数中的局部变量的总大小确定临时空间的大小);
- [可选]push XXX: 保存(push)一些寄存器的值;
- 子函数调用返回:
- 保持返回值:一般将函数函数值保持在eax寄存器中;
- [可选]恢复(pop)一些寄存器的值;
- mov %rbp,%rsp: 收回栈空间,恢复主函数的栈顶;
- pop %rbp;恢复主函数的栈底;
在AT&T中:
以上两条指令可以被leave指令取代
- leave
- ret;从栈顶获取之前保持的返回地址(return address),并跳转到此位置执行;
栈攻击
由上面栈内存布局可以看出,栈很容易被破坏和攻击,通过栈缓冲器溢出攻击,用攻击代码首地址来替换函数帧的返回地址,当子函数返回时,便跳转到攻击代码处执行,获取系统的控制权,所以操作系统和编译器采用了
以上是关于C++内存管理全景指南的主要内容,如果未能解决你的问题,请参考以下文章