hive的数据库和表操作
Posted 健鑫.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hive的数据库和表操作相关的知识,希望对你有一定的参考价值。
hive的数据库和表操作
数据库操作
创建数据库
create database if not exists myhive;
use myhive
hive表存放位置由 conf/hive-site.xml 的一个属性指定的
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
指定HDFS位置
create database myhive location '/myhive'
查看数据库信息
desc database myhive
删除数据库
- 删除一个空数据库,如果数据库中存在表,就会报错
drop database myhive;
- 删除一个数据库,包括数据库中的表
drop database myhive cascade
表操作
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
- EXTERNAL 创建一个外部表,建表的同时指定一个执行实际数据的location。hive创建内部表会将数据移动到数据仓库指向的路径。创建外部表,不会改变数据的位置。删除表的时候,内部表的元数据和数据会一起删除,外部表只删除元数据
- CLUSTERED BY 对每个表进行分桶(MR的分区),桶是更为细粒的数据范围的划分。hive针对某一列进行桶的划分,采用列值哈希,除以桶的个数求余来判断存放在哪个桶中
- ROW FORMAT 指定行分隔符
- STORED AS 表数据的存储格式,默认为TextFile
- LOCATION 表在HDFS上的存储位置
- LIKE 复制表结构但不复制数据
字段类型
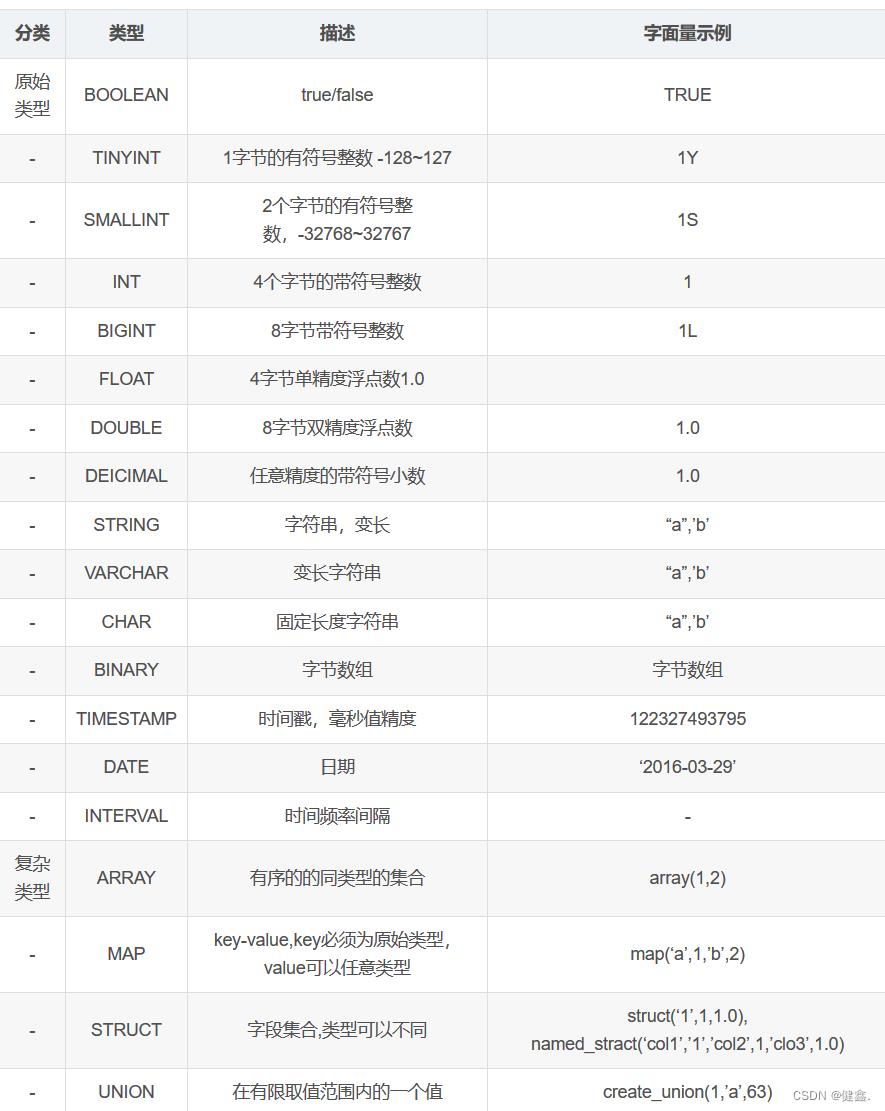
内部表操作
未被 external 修饰的是内部表,不适合和其他工具共享数据
创建内部表
create database myhive;
use myhive;
create table s(id int, name string);
insert into s values (1, "jx");
select * from s
指定分隔符
create table if not exists s(id, int, name string)
row format delimited fields terminated by '\\t'
根据查询结果创建表
create table s2 as select * from s;
根据已有的表创建表
create table s2 like s;
查看表的类型
desc formatted s;
删除表
drop table s;
外部表操作
通过external关键字来创建外部表,文件存储在location指定的HDFS目录下
数据装载指令 load
load data [local] inpath '' [overwrite] into table table_name [partition]
- local 表示从本地加载数据,否则从HDFS加载数据
- inpath:加载数据路径
复杂类型的操作
Array类型
Array是数组类型,存放相同类型的数据
-- 查询所有数据
select * from myhive;
-- 查询arr数组中的第一个元素
select name, arr[0] from myhive;
-- 查询arr数组中元素的个数
select name, size(arr) from myhive;
-- 查询arr数组中包含某一值的信息
select * from myhive where array_contains(name, 'jx');
分区表
分区可以理解成分类,将不同类型的数据放到不同的目录下
分区表可以优化查询,通过where来指定所需的分区
创建分区表
create table student(name string, age int)
partitioned by(score int)
row format delimited fields terminated by '\\t';
一个表带多个分区
create table student1(name string, age int)
partitioned by(score int, school string)
row format delimited fields terminated by '\\t';
加载数据
load data local inpath '/opt/data/student.csv' into table student partition(score = 90);
load data local inpath '/opt/data/student.csv' into table student1 partition(score = 90, school = 'one');
多分区表联合查询
select * from student where score = 90 union all select * from where score = 80;
查看分区
show partition student;
添加分区
alter table student add partition(score = 70);
alter table student add partition(score = 70) partition(score = 60);
删除分区
alter table student drop partition (score = 90);
分桶表
将数据划分到不同文件中(MR的分区)
将数据按照字段进行划分到多个文件中去
开启hive的分桶表
set hive.enforce.bucketing = true
-- 设置reduce个数
set mapreduce.job.reduces = 3
创建分桶表
create table person(name string, age int) clustered by (age) into 3 buckets
row format delimited fields terminated by '\\t'
桶表的数据加载通过HDFS,只能使用insert来加载数据
加载数据
insert overwrite table person select * from student cluster by (id);
修改表
基本语法
alter table old_table_name rename to new_table_name;
修改列信息
-- 查询表结构
desc person
-- 添加列
alter table person add columns(job string)
-- 更新列
alter table person change column job my_job string
删除表
drop table perosn
清空表结构
truncate table person
加载数据
向分区表中添加数据
insert into table person partition(score = 80) values ('jx', 20);
insert overwrite table person partition(score = 80) select name, age from student
load data local path '/opt/data/person.csv' overwrite into table person partition(score = 90);
数据导出
insert overwrite local directory '/opt/data/perosn.csv' select * from person
以上是关于hive的数据库和表操作的主要内容,如果未能解决你的问题,请参考以下文章