论文阅读和分析:《DeepGCNs: Can GCNs Go as Deep as CNNs?》
Posted KPer_Yang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文阅读和分析:《DeepGCNs: Can GCNs Go as Deep as CNNs?》相关的知识,希望对你有一定的参考价值。
更深的图卷积神经网络,相当于residual在CNN中的应用,使得可以构建更深层次的卷积网络而不会造成梯度消失无法训练的问题。
算法原理:
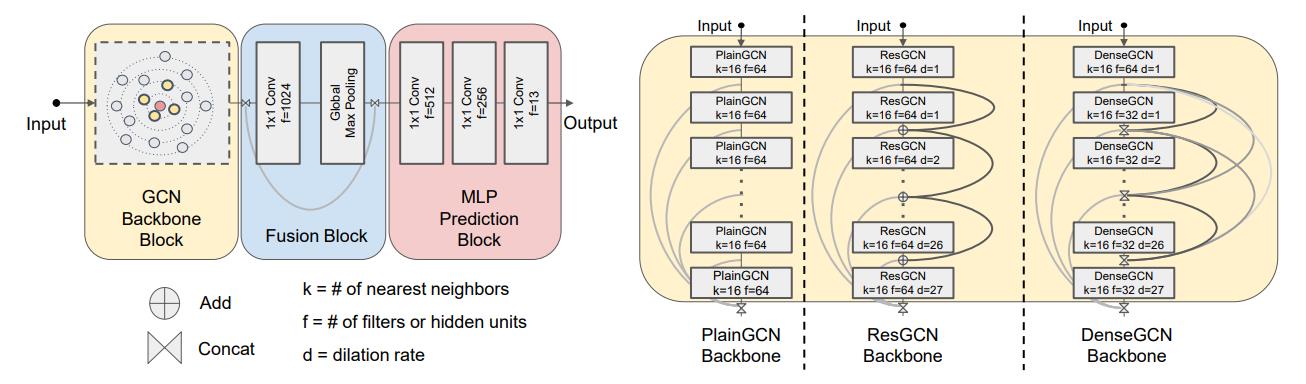
学习过Resnet去理解DeepGCNs就会很容易,看图片基本就能明白。
提出了用于点云语义分割的GCN架构。(左)我们的框架由三个块组成:GCN骨干块(输入点云的特征转换)、融合块(全局特征生成和融合)和MLP预测块(逐点标签预测)。(右)我们研究了三种类型的GCN骨干块(PlainGCN、ResGCN和DenseGCN),并使用了两种层连接(ResGCN中使用的逐顶点加法或DenseGCN中使用的按顶点级联)。
geometric的实现
torch_geometric.nn — pytorch_geometric documentation (pytorch-geometric.readthedocs.io)
The implemented skip connections includes the pre-activation residual connection ("res+"), the residual connection ("res"), the dense connection ("dense") and no connections ("plain").
- Res+ (
"res+"):
Normalization → Activation → Dropout → GraphConv → Res \\textNormalization\\to\\textActivation\\to\\textDropout\\to \\textGraphConv\\to\\textRes Normalization→Activation→Dropout→GraphConv→Res
- Res (:obj:
"res") / Dense (:obj:"dense") / Plain(:obj:"plain"):
GraphConv → Normalization → Activation → Res/Dense/Plain → Dropout \\textGraphConv\\to\\textNormalization\\to\\textActivation\\to \\textRes/Dense/Plain\\to\\textDropout GraphConv→Normalization→Activation→Res/Dense/Plain→Dropout
geometric库的实现两种相关架构的网络单元,Res+和Res,需要输入卷积、激活和归一化等子单元,就是说可以用户定制化的实现,这一点很值得学习。一种延迟策略,实现良好的泛化性。
from typing import Optional
import torch
import torch.nn.functional as F
from torch import Tensor
from torch.nn import Module
from torch.utils.checkpoint import checkpoint
class DeepGCNLayer(torch.nn.Module):
"""
Args:
conv (torch.nn.Module, optional): the GCN operator.
(default: :obj:`None`)
norm (torch.nn.Module): the normalization layer. (default: :obj:`None`)
act (torch.nn.Module): the activation layer. (default: :obj:`None`)
block (string, optional): The skip connection operation to use
(:obj:`"res+"`, :obj:`"res"`, :obj:`"dense"` or :obj:`"plain"`).
(default: :obj:`"res+"`)
dropout (float, optional): Whether to apply or dropout.
(default: :obj:`0.`)
ckpt_grad (bool, optional): If set to :obj:`True`, will checkpoint this
part of the model. Checkpointing works by trading compute for
memory, since intermediate activations do not need to be kept in
memory. Set this to :obj:`True` in case you encounter out-of-memory
errors while going deep. (default: :obj:`False`)
"""
def __init__(
self,
conv: Optional[Module] = None,
norm: Optional[Module] = None,
act: Optional[Module] = None,
block: str = 'res+',
dropout: float = 0.,
ckpt_grad: bool = False,
):
super().__init__()
self.conv = conv
self.norm = norm
self.act = act
self.block = block.lower()
assert self.block in ['res+', 'res', 'dense', 'plain']
self.dropout = dropout
self.ckpt_grad = ckpt_grad
def reset_parameters(self):
self.conv.reset_parameters()
self.norm.reset_parameters()
def forward(self, *args, **kwargs) -> Tensor:
""""""
args = list(args)
x = args.pop(0)
if self.block == 'res+':
h = x
if self.norm is not None:
h = self.norm(h)
if self.act is not None:
h = self.act(h)
h = F.dropout(h, p=self.dropout, training=self.training)
if self.conv is not None and self.ckpt_grad and h.requires_grad:
# checkpoint不保存中间变量,而是在后向更新的时候重新计算一遍。
h = checkpoint(self.conv, h, *args, **kwargs)
else:
h = self.conv(h, *args, **kwargs)
return x + h
else:
if self.conv is not None and self.ckpt_grad and x.requires_grad:
h = checkpoint(self.conv, x, *args, **kwargs)
else:
h = self.conv(x, *args, **kwargs)
if self.norm is not None:
h = self.norm(h)
if self.act is not None:
h = self.act(h)
if self.block == 'res':
h = x + h
elif self.block == 'dense':
h = torch.cat([x, h], dim=-1)
elif self.block == 'plain':
pass
return F.dropout(h, p=self.dropout, training=self.training)
def __repr__(self) -> str:
return f'self.__class__.__name__(block=self.block)'
注释:pytoch checkpoint
torch.utils.checkpoint — PyTorch 1.13 documentation
torch.utils.checkpoint 简介 和 简易使用_ONE_SIX_MIX的博客-CSDN博客
pytorch 的 checkpoint 是一种用时间换显存的技术,一般训练模式下,pytorch 每次运算后会保留一些中间变量用于求导,而使用 checkpoint 的函数,则不会保留中间变量,中间变量会在求导时再计算一次,因此减少了显存占用,这个 checkpoint 用的好的话,训练时相比不使用 checkpoint 的模型可以增加 30% 的批量大小。
参考:
[2006.07739] DeeperGCN: All You Need to Train Deeper GCNs (arxiv.org)
[1904.03751] DeepGCNs: Can GCNs Go as Deep as CNNs? (arxiv.org)
torch_geometric.nn — pytorch_geometric documentation (pytorch-geometric.readthedocs.io)
torch.utils.checkpoint — PyTorch 1.13 documentation
torch.utils.checkpoint 简介 和 简易使用_ONE_SIX_MIX的博客-CSDN博客
geometric/blob/master/examples/ogbn_proteins_deepgcn
以上是关于论文阅读和分析:《DeepGCNs: Can GCNs Go as Deep as CNNs?》的主要内容,如果未能解决你的问题,请参考以下文章