伪共享与CPU cache line
Posted 惜暮
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了伪共享与CPU cache line相关的知识,希望对你有一定的参考价值。
伪共享与CPU cache line
CPU缓存;
先看定义:
CPU 缓存(Cache Memory)是位于 CPU 与内存之间的临时存储器,它的容量比内存小的多但是交换速度却比内存要快得多。
高速缓存的出现主要是为了解决 CPU 运算速度与内存读写速度不匹配的矛盾,因为 CPU 运算速度要比内存读写速度快很多,这样会使 CPU 花费很长时间等待数据到来或把数据写入内存。
在缓存中的数据是内存中的一小部分,但这一小部分是短时间内 CPU 即将访问的,当 CPU 调用大量数据时,就可避开内存直接从缓存中调用,从而加快读取速度。
CPU 和主内存之间有好几层缓存,因为即使直接访问主内存也是非常慢的。如果你正在多次对一块数据做相同的运算,那么在执行运算的时候把它加载到离 CPU 很近的地方就有意义了。
下图是一个很经典的图:
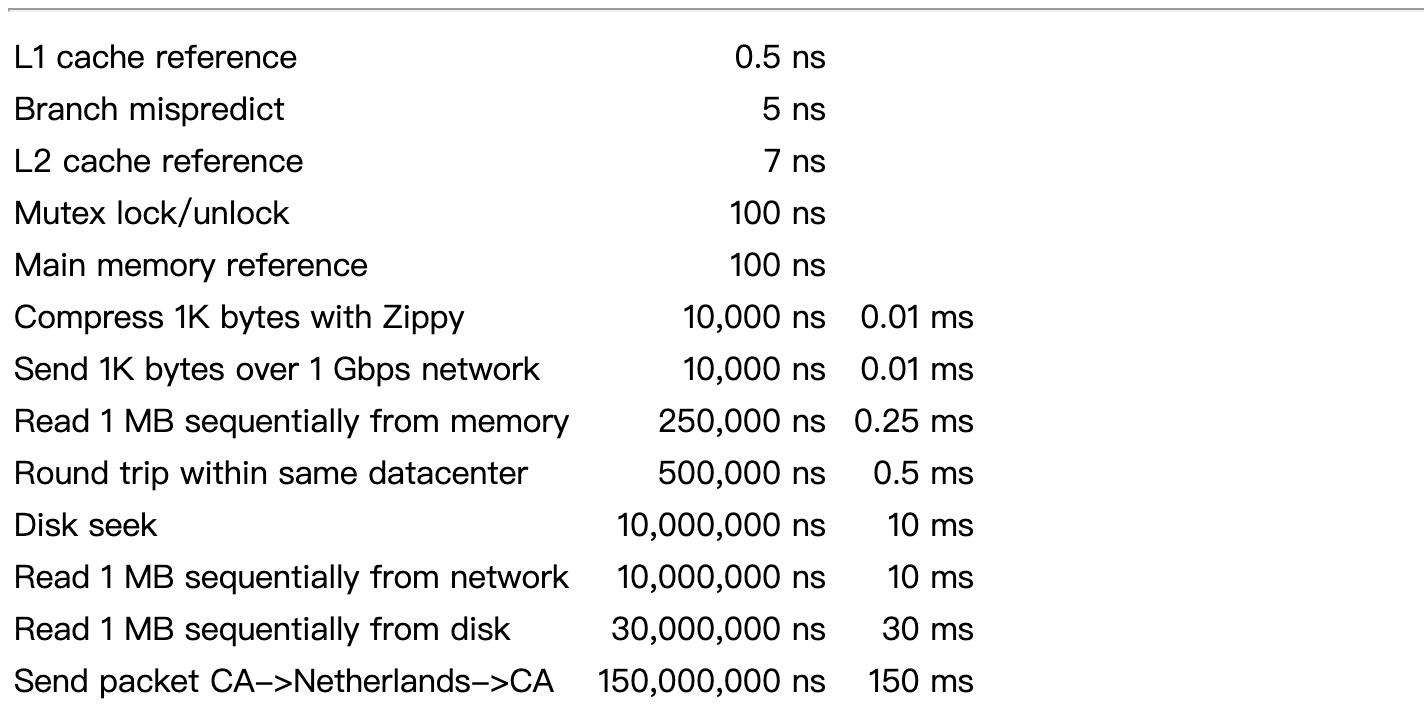
这个数据可能不准了(10年前的数据),但是整体还是能够说明问题:离CPU越近,读写数据就越快。
多核机器的存储结构如下图所示:
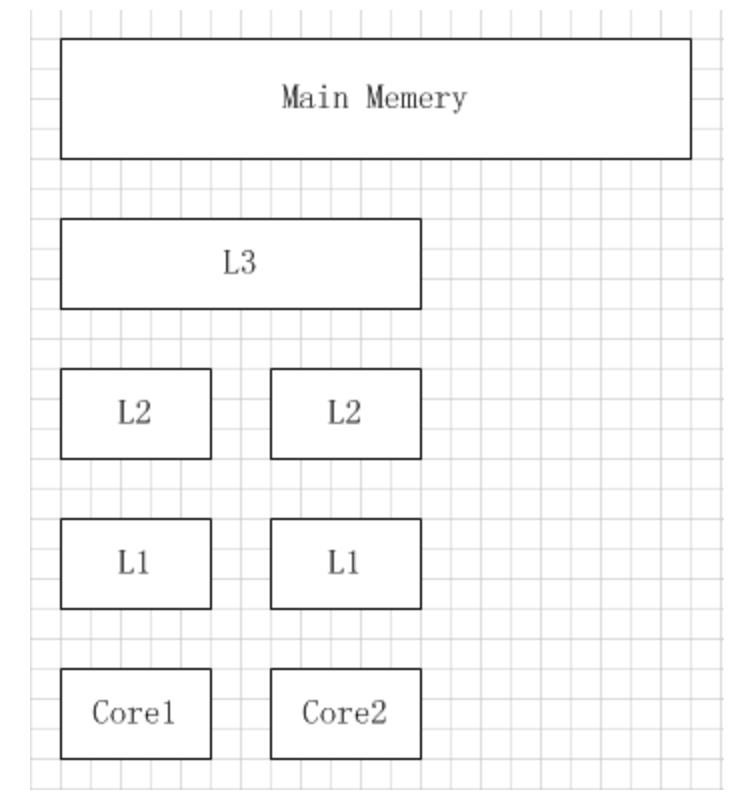
当 CPU 执行运算的时候,它先去 L1 查找所需的数据,再去 L2,然后是 L3,最后如果这些缓存中都没有,所需的数据就要去主内存拿。走得越远,运算耗费的时间就越长。所以如果你在做一些很频繁的事,你要确保数据在 L1 缓存中。
缓存行
缓存系统中是以缓存行(cache line)为单位存储的。缓存行通常是 64 字节(译注:本文基于 64 字节,其他长度的如 32 字节等不适本文讨论的重点),并且它有效地引用主内存中的一块地址。一个 Java 的 long 类型是 8 字节,因此在一个缓存行中可以存 8 个 long 类型的变量。所以,如果你访问一个 long 数组,当数组中的一个值被加载到缓存中,它会额外加载另外 7 个,以致你能非常快地遍历这个数组。事实上,你可以非常快速的遍历在连续的内存块中分配的任意数据结构。而如果你在数据结构中的项在内存中不是彼此相邻的(如链表),你将得不到免费缓存加载所带来的优势,并且在这些数据结构中的每一个项都可能会出现缓存未命中。
每一个缓存行都有自己的状态维护,假设一个CPU缓存行中有8个long型变量:a, b, c, d, e, f, g, h。这8个数据中的a被修改了之后又修改了b,那么当再次读取a的时候这个缓存行就失效了,需要重新从主内存中load。
举个例子:有多个线程操作不同的成员变量,但是这些变量在相同的缓存行,这个时候会发生什么?。没错,伪共享(False Sharing)问题就发生了!有张 Disruptor 项目的经典示例图,如下:
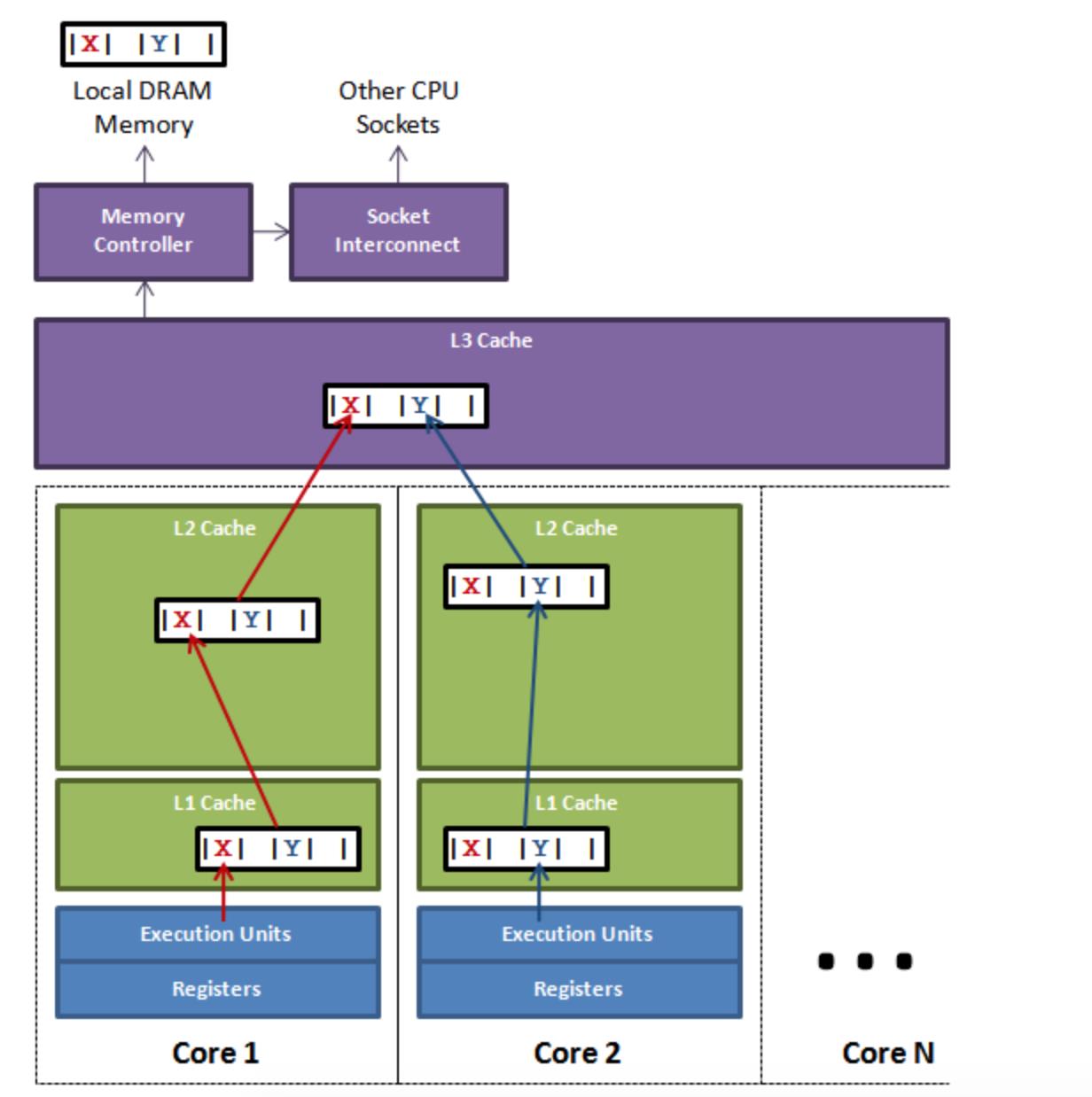
上图中,一个运行在处理器 core1上的线程想要更新变量 X 的值,同时另外一个运行在处理器 core2 上的线程想要更新变量 Y 的值。但是,这两个频繁改动的变量都处于同一条缓存行。两个线程就会轮番发送 RFO(Request for owner) 消息,占得此缓存行的拥有权。当 core1 取得了拥有权开始更新 X,则 core2 对应的缓存行需要设为 I 状态(缓存行失效状态)。当 core2 取得了拥有权开始更新 Y,则 core1 对应的缓存行需要设为 I 状态(失效态)。轮番夺取拥有权不但带来大量的 RFO 消息,而且如果某个线程需要读此行数据时,L1 和 L2 缓存上都是失效数据,只有 L3 缓存上是同步好的数据。从前一篇我们知道,读 L3 的数据非常影响性能。更坏的情况是跨槽读取,L3 都要 miss,只能从内存上加载。
表面上 X 和 Y 都是被独立线程操作的,而且两操作之间也没有任何关系。只不过它们共享了一个缓存行,但所有竞争冲突都是来源于共享。
伪共享
伪共享的非标准定义为:缓存系统中是以缓存行(cache line)为单位存储的,当多线程修改互相独立的变量时,如果这些变量共享同一个缓存行,就会无意中影响彼此的性能,这就是伪共享。
下面是一个跑的例子:
package test
import (
"sync/atomic"
"testing"
)
type NoPad struct
a uint64
b uint64
c uint64
func (np *NoPad) Increase()
atomic.AddUint64(&np.a, 1)
atomic.AddUint64(&np.b, 1)
atomic.AddUint64(&np.c, 1)
type Pad struct
a uint64
_p1 [7]uint64
b uint64
_p2 [7]uint64
c uint64
_p3 [7]uint64
func (p *Pad) Increase()
atomic.AddUint64(&p.a, 1)
atomic.AddUint64(&p.b, 1)
atomic.AddUint64(&p.c, 1)
func BenchmarkPad_Increase(b *testing.B)
pad := &Pad
b.RunParallel(func(pb *testing.PB)
for pb.Next()
pad.Increase()
)
func BenchmarkNoPad_Increase(b *testing.B)
nopad := &NoPad
b.RunParallel(func(pb *testing.PB)
for pb.Next()
nopad.Increase()
)
测试结果:
goos: darwin
goarch: amd64
BenchmarkPad_Increase
BenchmarkPad_Increase-4 31773807 39.6 ns/op
BenchmarkNoPad_Increase
BenchmarkNoPad_Increase-4 22885161 52.6 ns/op
PASS
每次跑的结果不一样,但是加了Padding的性能肯定是比没有Padding的要好得多。
解决伪共享的方案就是padding。现在分析上面的例子,我们知道一条缓存行有 64 bytes,go里面uint64是8个字节,我们通过在a、b、c后面pading保证每个变量处于不同的缓存行,就避免了伪共享( 64 位系统超过缓存行的 64 字节也无所谓,只要保证不同线程不操作同一缓存行就可以)。
以上是关于伪共享与CPU cache line的主要内容,如果未能解决你的问题,请参考以下文章