快来,我悄悄的给你说几个HashCode的破事。
Posted why技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了快来,我悄悄的给你说几个HashCode的破事。相关的知识,希望对你有一定的参考价值。
这是why技术的第 72 篇原创文章
Hash冲突是怎么回事
在这个文章正式开始之前,先几句话把这个问题说清楚了:我们常说的 Hash 冲突到底是怎么回事?
直接上个图片:
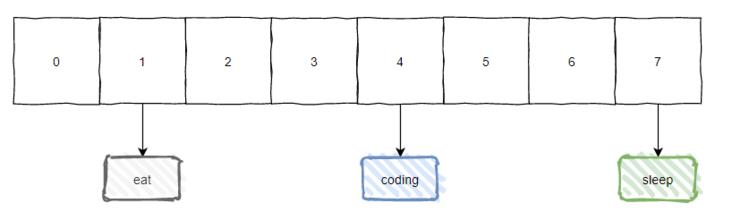
你说你看到这个图片的时候想到了什么东西?
有没有想到 HashMap 的数组加链表的结构?
对咯,我这里就是以 HashMap 为切入点,给大家讲一下 Hash 冲突。
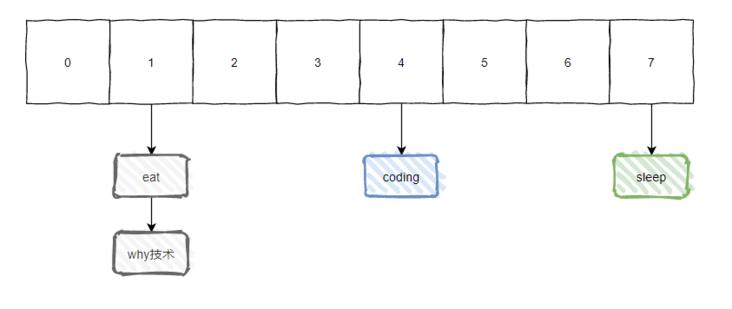
接着我们看下面这张图:

假设现在我们有个值为 [why技术] 的 key,经过 Hash 算法后,计算出值为 1,那么含义就是这个值应该放到数组下标为 1 的地方。
但是如图所示,下标为 1 的地方已经挂了一个 eat 的值了。这个坑位已经被人占着了。
那么此时此刻,我们就把这种现象叫为 Hash 冲突。
HashMap 是怎么解决 Hash 冲突的呢?
链地址法,也叫做拉链法。
数组中出现 Hash 冲突了,这个时候链表的数据结构就派上用场了。
链表怎么用的呢?看图:
这样问题就被我们解决了。
其实 hash 冲突也就是这么一回事:不同的对象经过同一个 Hash 算法后得到了一样的 HashCode。
那么写到这里的时候我突然想到了一个面试题:
请问我上面的图是基于 JDK 什么版本的 HashMap 画的图?
为什么想到了这个面试题呢?
因为我画图的时候犹豫了大概 0.3 秒,往链表上挂的时候,我到底是使用头插法还是尾插法呢?

众所周知,JDK 7 中的 HashMap 是采用头插法的,即 [why技术] 在 [eat] 之前,JDK 8 中的 HashMap 采用的是尾插法。
这面试题怎么说呢,真的无聊。但是能怎么办呢,八股文该背还是得背。
面试嘛,背一背,不寒碜。
构建 HashCode 一样的 String
前面我们知道了,Hash 冲突的根本原因是不同的对象经过同一个 Hash 算法后得到了一样的 HashCode。
这句话乍一听:嗯,很有道理,就是这么一回事,没有问题。
比如我们常用的 HashMap ,绝大部分情况 key 都是 String 类型的。要出现 Hash 冲突,最少需要两个 HashCode 一样的 String 类。
那么我问你:怎么才能快速弄两个 HashCode 一样的 String 呢?

怎么样,有点懵逼了吧?
从很有道理,到有点懵逼只需要一个问题。
来,我带你分析一波。
我先问你:长度为 1 的两个不一样的 String,比如下面这样的代码,会不会有一样的 HashCode?
`String a = "a";
String b = "b";
`
肯定是不会的,对吧。
如果你不知道的话,建议你去 ASCII 码里面找答案。
我们接着往下梳理,看看长度为 2 的 String 会不会出现一样的 HashCode?
要回答这个问题,我们要先看看 String 的 hashCode 计算方法,我这里以 JDK 8 为例:
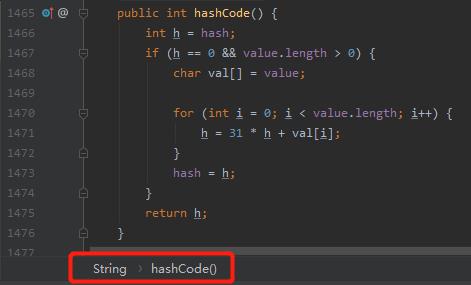
我们假设这两个长度为 2 的 String,分别是 xy 和 ab 吧。
注意这里的 xy 和 ab 都是占位符,不是字符串。
类似于小学课本中一元二次方程中的未知数 x 和 y,我们需要带入到上面的 hashCode 方法中去计算。
hashCode 算法,最主要的就是其中的这个 for 循环。
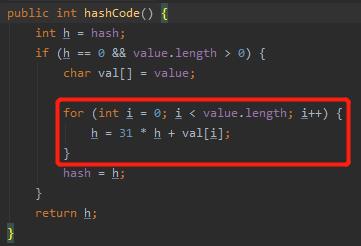
for 循环里面的有三个我们不知道是啥的东西:h,value.length 和 val[i]。我们 debug 看一下:
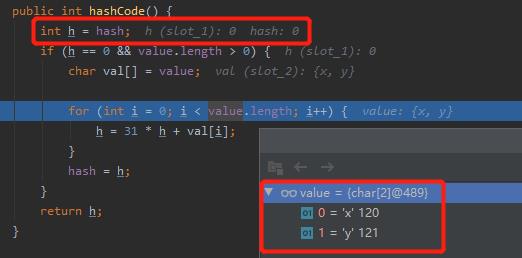
h 初始情况下等于 0。
String 类型的底层结构是 char 数组,这个应该知道吧。
所以,value.length 是字符串的长度。val[] 就是这个 char 数组。
把 xy 带入到 for 循环中,这个 for 循环会循环 2 次。
第一次循环:h=0,val[0]=x,所以 h=31*0+x,即 h=x。
第二次循环:h=x,val[1]=y,所以 h=31*x+y。
所以,经过计算后, xy 的 hashCode 为 31*x+y。
同理可得,ab 的 hashCode 为 31*a+b。
由于我们想要构建 hashCode 一样的字符串,所以可以得到等式:
31_x+y=31_a+b
那么问题就来了:请问 x,y,a,b 分别是多少?
你算的出来吗?
你算的出来个锤子!黑板上的排列组合你不是舍不得解开,你就是解不开。
但是我可以解开,带大家看看这个题怎么搞。
数学课开始了。注意,我要变形了。

31_x+y=31_a+b 可以变形为:
31_x-31_a=b-y。
即,31(x-a)=b-y。
这个时候就清晰很多了,很明显,上面的等式有一个特殊解:
x-a=1,b-y=31。
因为,由上可得:对于任意两个字符串 xy 和 ab,如果它们满足 x-a=1,即第一个字符的 ASCII 码值相差为 1,同时满足 b-y=31,即第二个字符的 ASCII 码值相差为 -31。那么这两个字符的 hashCode 一定相等。
都已经说的这么清楚了,这样的组合对照着 ASCII 码表来找,不是一抓一大把吗?
Aa 和 BB,对不对?
Ab 和 BC,是不是?
Ac 和 BD,有没有?
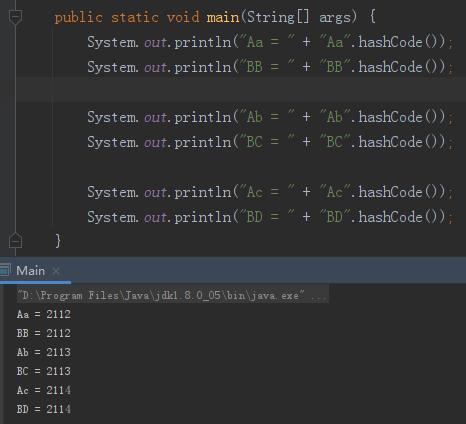
好的。现在,我们可以生成两个 HashCode 一样的字符串了。
我们在稍微加深一点点难度。假设我要构建 2 个以上 HashCode 一样的字符串该怎么办?
我们先分析一下。
Aa 和 BB 的 HashCode 是一样的。我们把它两一排列组合,那不还是一样的吗?
比如这样的:AaBB,BBAa。

再比如我之前《震惊!ConcurrentHashMap里面也有死循环?》这篇文章中出现过的例子,AaAa,BBBB:
你看,神奇的事情就出现了。
我们有了 4 个 hashCode 一样的字符串了。
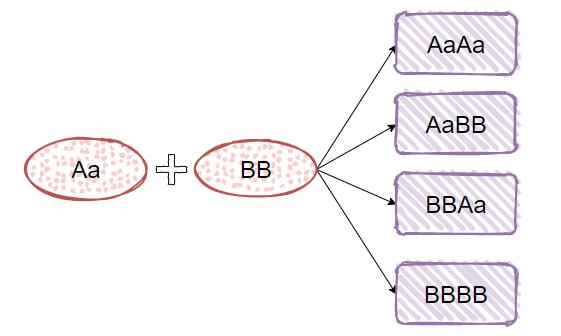
有了这 4 个字符串,我们再去和 Aa,BB 进行组合,比如 AaBBAa,BBAaBB......
4*2=8 种组合方式,我们又能得到 8 个 hashCode 一样的字符串了。
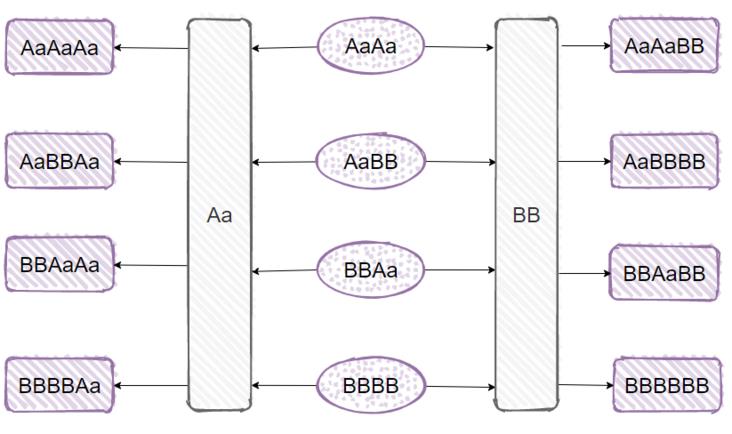
等等,我好像发现了什么规律似的。
如果我们以 Aa,BB 为种子数据,经过多次排列组合,可以得到任意个数的 hashCode 一样的字符串。字符串的长度随着个数增加而增加。
文字我还说不太清楚,直接 show you code 吧,如下:
`public class CreateHashCodeSomeUtil {
/**
* 种子数据:两个长度为 2 的 hashCode 一样的字符串
*/
private static String[] SEED = new String[]{"Aa", "BB"};
/**
* 生成 2 的 n 次方个 HashCode 一样的字符串的集合
*/
public static List<String> hashCodeSomeList(int n) {
List<String> initList = new ArrayList<String>(Arrays.asList(SEED));
for (int i = 1; i < n; i++) {
initList = createByList(initList);
}
return initList;
}
public static List<String> createByList(List<String> list) {
List<String> result = new ArrayList<String>();
for (int i = 0; i < SEED.length; ++i) {
for (String str : list) {
result.add(SEED[i] + str);
}
}
return result;
}
}
`
通过上面的代码,我们就可以生成任意多个 hashCode 一样的字符串了。
就像这样:

所以,别再问出这样的问题了:


有了这些 hashCode 一样的字符串,我们把这些字符串都放到HashMap 中,代码如下:
`public class HashMapTest {
public static void main(String[] args) {
Map<String, String> hashMap = new HashMap<String, String>();
hashMap.put("Aa", "Aa");
hashMap.put("BB", "BB");
hashMap.put("AaAa", "AaAa");
hashMap.put("AaBB", "AaBB");
hashMap.put("BBAa", "BBAa");
hashMap.put("BBBB", "BBBB");
hashMap.put("AaAaAa", "AaAaAa");
hashMap.put("AaAaBB", "AaAaBB");
hashMap.put("AaBBAa", "AaBBAa");
hashMap.put("AaBBBB", "AaBBBB");
hashMap.put("BBAaAa", "BBAaAa");
hashMap.put("BBAaBB", "BBAaBB");
hashMap.put("BBBBAa", "BBBBAa");
hashMap.put("BBBBBB", "BBBBBB");
}
}
`
最后这个 HashMap 的长度会经过两次扩容。扩容之后数组长度为 64:
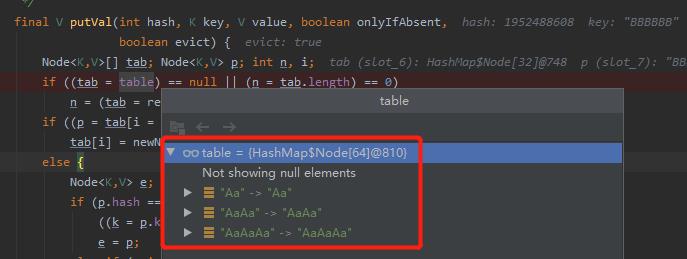
但是里面只被占用了三个位置,分别是下标为 0,31,32 的地方:

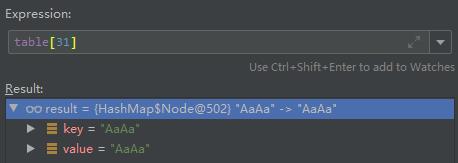
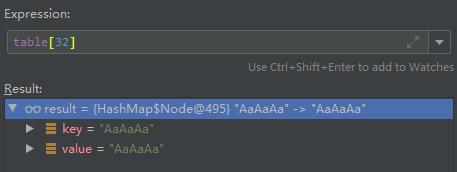
画图如下:
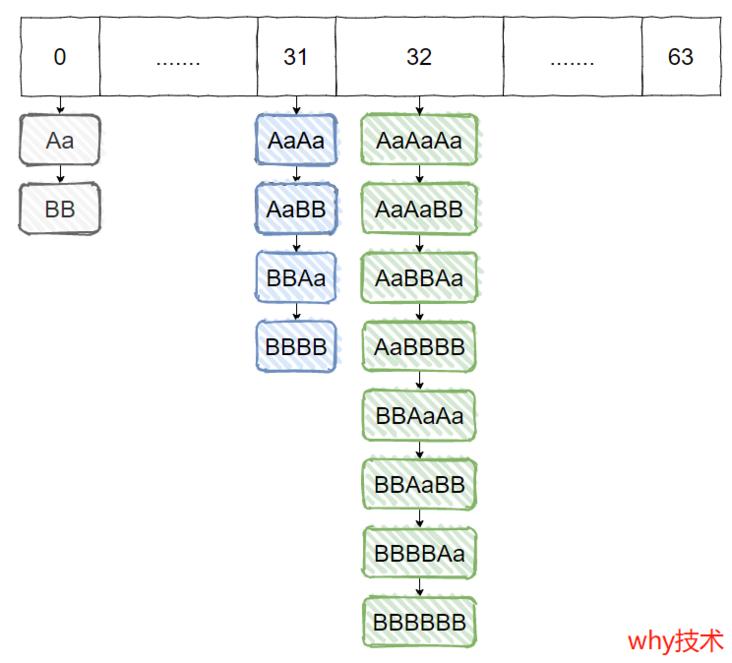
看到了吧,刺不刺激,长度为 64 的数组,存 14 个数据,只占用了 3 个位置。
这空间利用率,也太低了吧。
所以,这样就算是 hack 了 HashMap。恭喜你,掌握了一项黑客攻击技术:hash 冲突 Dos 。
如果你想了解的更多。可以看看石头哥的这篇文章:《没想到 Hash 冲突还能这么玩,你的服务中招了吗?》。
看到上面的图,不知道大家有没有觉得有什么不对劲的地方?
如果没有,那么我再给你提示一下:数组下标为 32 的位置下,挂了一个长度为 8 的链表。
是不是,恍然大悟了。在 JDK 8 中,链表转树的阈值是多少?

所以,在当前的案例中,数组下标为 32 的位置下挂的不应该是一个链表,而是一颗红黑树。
对不对?

对个锤子对!有的同学,上课不认真,稍不留神就被带偏了。

这是不对的。链表转红黑树的阈值是节点大于 8 个,而不是等于 8 的时候。
也就是说需要再来一个经过 hash 计算后,下标为 32 的、且 value 和之前的 value 都不一样的 key 的时候,才会触发树化操作。
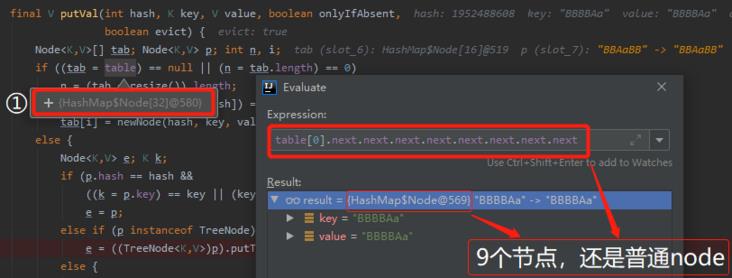
不信,我给你看看现在是一个什么节点:
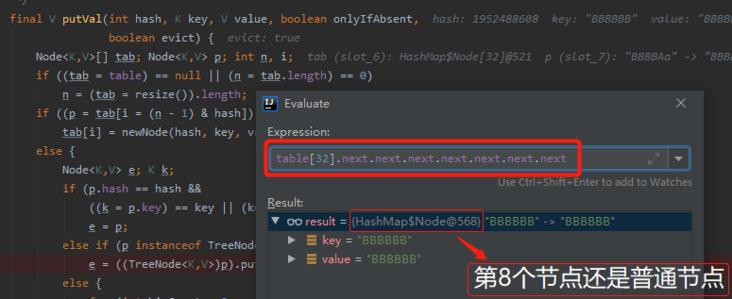
没有骗你吧?从上面的图片可以清楚的看到,第 8 个节点还是一个普通的 node。
而如果是树化节点,它应该是长这样的:
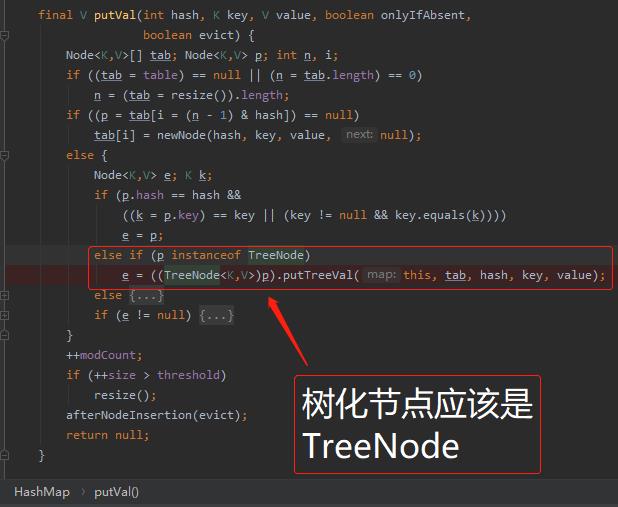
不信,我们再多搞一个 hash 冲突进来,带你亲眼看一下,代码是不会骗人的。
那么怎么多搞一个冲突出来呢?
最简单的,这样写:
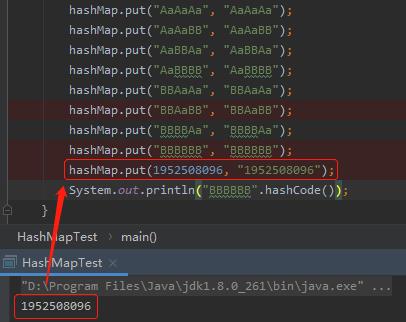
这样冲突不就多一个了吗?我真是一个天才,情不自禁的给自己鼓起掌来。
好了,我们看一下现在的节点状态是怎么样的:
怎么样,是不是变成了 TreeNode ,没有骗你吧?
另外,我还想多说一句,关于一个 HashMap 的面试题的一个坑。
面试官问:JDK 8 的 HashMap 链表转红黑树的条件是什么?
绝大部分背过面试八股文的朋友肯定能答上来:当链表长度大于 8 的时候。
这个回答正确吗?
是正确的,但是只正确了一半。
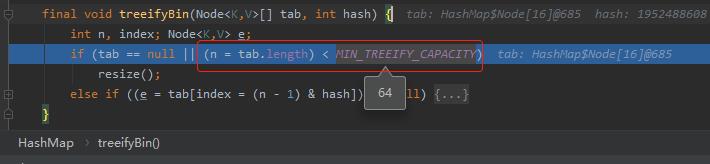
还有一个条件是数组长度大于 64 的时候才会转红黑树。
源码里面写的很清楚,数组长度小于 64,直接扩容,而不是转红黑树:
感觉很多人都忽略了“数组长度大于 64 ”这个条件。
背八股文,还是得背全了。
比如下面这种测试用例:
它们都会落到数组下标为 0 的位置上。
当第 9 个元素 BBBBAa 落进来的时候,会走到 treeifyBin 方法中去,但是不会触发树化操作,只会进行扩容操作。
因为当前长度为默认长度,即 16。不满足转红黑树条件。
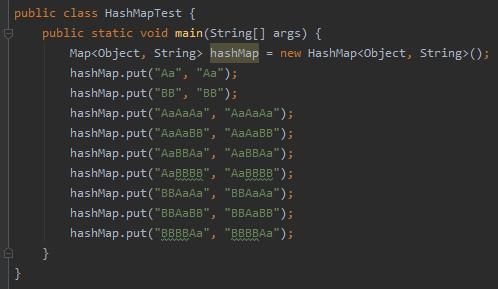
所以,从下面的截图,我们可以看到,标号为 ① 的地方,数组长度变成了 32,链表长度变成了 9 ,但是节点还是普通 node:
怎么样,有点意思吧,我觉得这样学 HashMap 有趣多了。

实体类当做 key
上面的示例中,我们用的是 String 类型当做 HashMap 中的 key。
这个场景能覆盖我们开发场景中的百分之 95 了。
但是偶尔会有那么几次,可能会把实体类当做 key 放到 HashMap 中去。
注意啊,面试题又来了:在 HashMap 中可以用实体类当对象吗?
那必须的是可以的啊。但是有坑,注意别踩进去了。
我拿前段时间看到的一个新闻给大家举个例子吧:
假设我要收集学生的家庭信息,用 HashMap 存起来。
那么我的 key 是学生对象, value 是学生家庭信息对象。
他们分别是这样的:
`public class HomeInfo {
private String homeAddr;
private String carName;
//省略改造方法和toString方法
}
public class Student {
private String name;
private Integer age;
//省略改造方法和toString方法
}
`
然后我们的测试用例如下:
`public class HashMapTest {
private static Map<Student, HomeInfo> hashMap = new HashMap<Student, HomeInfo>();
static {
Student student = new Student("why", 7);
HomeInfo homeInfo = new HomeInfo("大南街", "自行车");
hashMap.put(student, homeInfo);
}
public static void main(String[] args) {
updateInfo("why", 7, "滨江路", "摩托");
for (Map.Entry<Student, HomeInfo> entry : hashMap.entrySet()) {
System.out.println(entry.getKey()+"-"+entry.getValue());
}
}
private static void updateInfo(String name, Integer age, String homeAddr, String carName) {
Student student = new Student(name, age);
HomeInfo homeInfo = hashMap.get(student);
if (homeInfo == null) {
hashMap.put(student, new HomeInfo(homeAddr, carName));
}
}
}
`
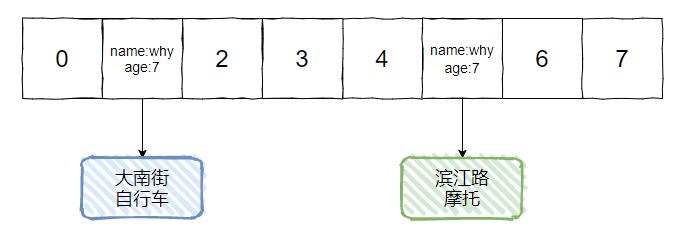
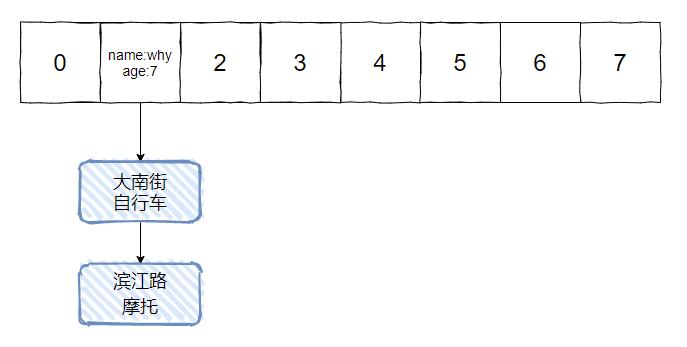
初始状态下,HashMap 中已经有一个名叫 why 的 7 岁小朋友了,他家住大南街,家里的交通工具是自行车。
然后,有一天他告诉老师,他搬家了,搬到了滨江路去,而且家里的自行车换成了摩托车。
于是老师就通过页面,修改了 why 小朋友的家庭信息。
最后调用到了 updateInfo 方法。
嘿,你猜怎么着?
我带你看一下输出:

更新完了之后,他们班上出现了两个叫 why 的 7 岁小朋友了,一个住在大南街,一个住在滨江路。
更新变新增了,你说神奇不神奇?
现象出来了,那么根据现象定位问题代码不是手到擒来的事儿?
很明显,问题就出在这个地方:
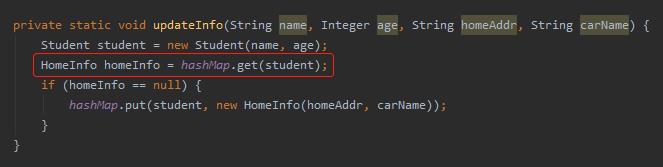
这里取出来的 homeInfo 为空了,所以才会新放一个数据进去。
那么我们看看为啥这里为空。
跟着 hashMap.get() 源码进去瞅一眼:
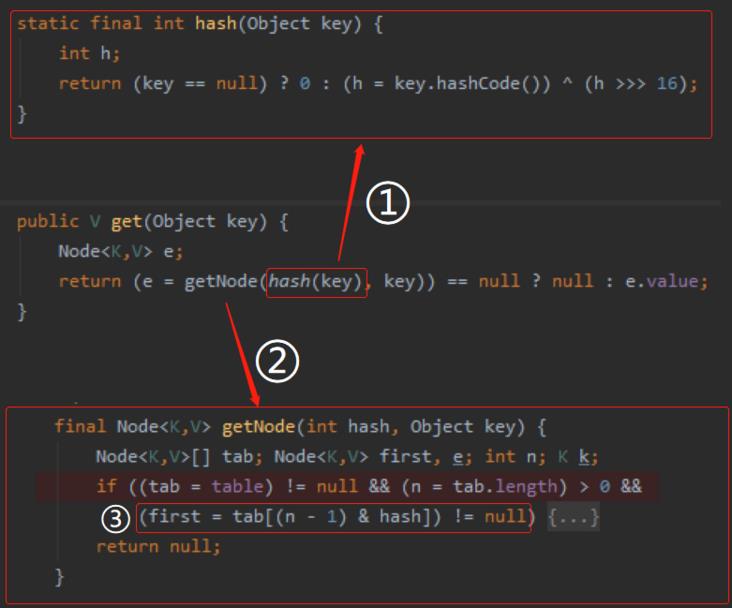
标号为 ① 的地方是计算 key ,也就是 student 对象的 hashCode。而我们 student 对象并没有重写 hashCode,所以调用的是默认的 hashCode 方法。
这里的 student 是 new 出来的:
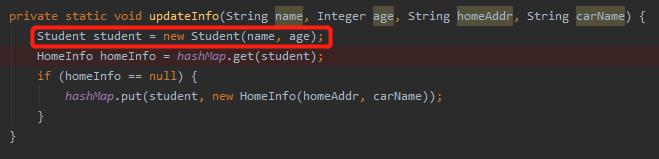
所以,这个 student 的 hashCode 势必和之前在 HashMap 里面的 student 不是一样的。
因此,标号为 ③ 的地方,经过 hash 计算后得出的 tab 数组下标,对应的位置为 null。不会进入 if 判断,这里返回为 null。
那么解决方案也就呼之欲出了:重写对象的 hashCode 方法即可。
是吗?
等等,你回来,别拿着半截就跑。我话还没说完呢。
接着看源码:
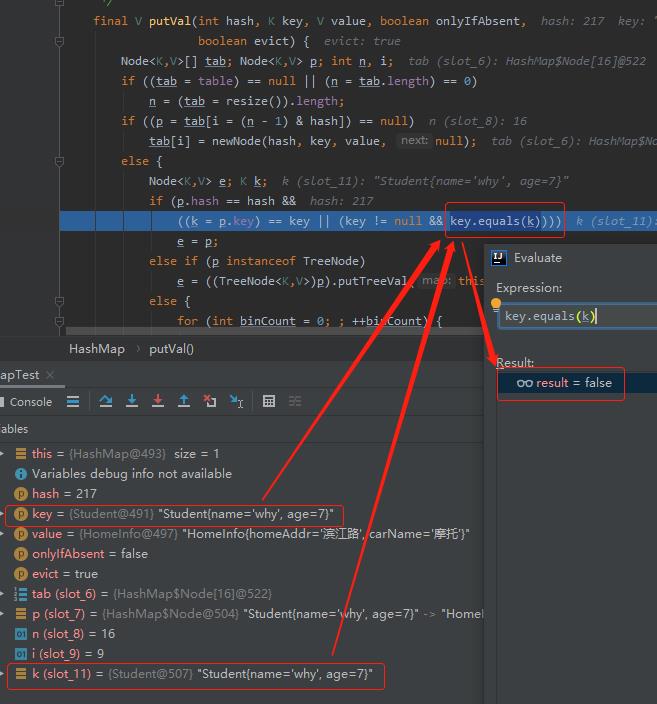
HashMap put 方法执行的时候,用的是 equals 方法判断当前 key 是否与表中存在的 key 相同。
我们这里没有重写 equals 方法,因此这里返回了 false。
所以,如果我们 hashCode 和 equals 方法都没有重写,那么就会出现下面示意图的情况:
如果,我们重写了 hashCode,没有重写 equals 方法,那么就会出现下面示意图的情况:
总之一句话:在 HashMap 中,如果用对象做 key,那么一定要重写对象的 hashCode 方法和 equals 方法。否则,不仅不能达到预期的效果,而且有可能导致内存溢出。
比如上面的示例,我们放到循环中去,启动参数我们加上 -Xmx10m,运行结果如下:
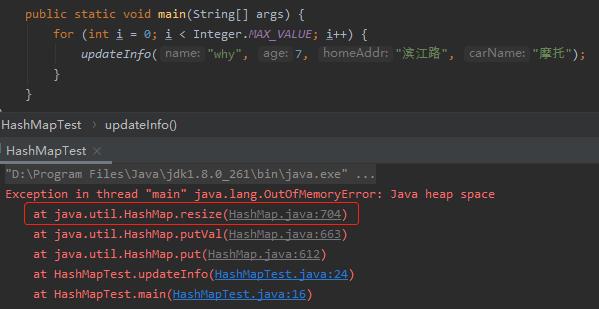
因为每一次都是 new 出来的 student 对象,hashCode 都不尽相同,所以会不停的触发扩容的操作,最终在 resize 的方法抛出了 OOM 异常。
奇怪的知识又增加了
写这篇文章的时候我翻了一下《Java 编程思想(第 4 版)》一书。
奇怪的知识又增加了两个。
第一个是在这本书里面,对于 HashMap 里面放对象的示例是这样的:

Groundhog:土拨鼠、旱獭。
Prediction:预言、预测、预告。
考虑一个天气预报系统,将土拨鼠和预报联系起来。
这 TM 是个什么读不懂的神仙需求?

幸好 why 哥学识渊博,闭上眼睛,去我的知识仓库里面搜索了一番。
原来是这么一回事。
在美国的宾西法尼亚州,每年的 2 月 2 日,是土拨鼠日。
根据民间的说法,如果土拨鼠在 2 月 2 号出洞时见到自己的影子,然后这个小东西就会回到洞里继续冬眠,表示春天还要六个星期才会到来。如果见不到影子,它就会出来觅食或者求偶,表示寒冬即将结束。
这就呼应上了,通过判断土拨鼠出洞的时候是否能看到影子,从而判断冬天是否结束。
这样,需求就说的通了。

第二个奇怪的知识是这样的。
关于 HashCode 方法,《Java编程思想(第4版)》里面是这样写的:

我一眼就发现了不对劲的地方:result=37*result+c。
前面我们才说了,基数应该是 31 才对呀?
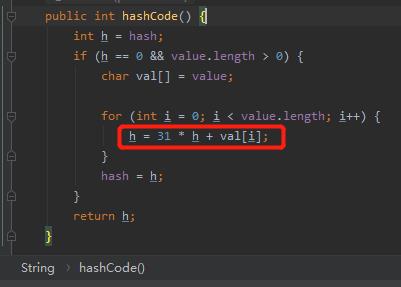
作者说这个公式是从《Effective Java(第1版)》的书里面拿过来的。
这两本书都是 java 圣经啊,建议大家把梦幻联动打在留言区上。
《Effective Java(第1版)》太久远了,我这里只有第 2 版和第 3 版的实体书。
于是我在网上找了一圈第 1 版的电子书,终于找到了对应描述的地方:

可以看到,书里给出的公式确实是基于 37 去计算的。
翻了一下第三版,一样的地方,给出的公式是这样的:

而且,你去网上搜:String 的 hashCode 的计算方法。
都是在争论为什么是 31 。很少有人提到 37 这个数。
其实,我猜测,在早期的 JDK 版本中 String 的 hashCode 方法应该用的是 37 ,后来改为了 31 。
我想去下载最早的 JDK 版本去验证一下的,但是网上翻了个底朝天,没有找到合适的。
书里面为什么从 37 改到 31 呢?
作者是这样解释的,上面是第 1 版,下面是第 2 版:

用方框框起来的部分想要表达的东西是一模一样的,只是对象从 37 变成了 31 。
而为什么从 37 变成 31 ,作者在第二版里面解释了,也就是我用下划线标注的部分。
31 有个很好的特许,即用位移和减法来代替乘法,可以得到更好的性能:
31*i==(i<<5)-1。现代的虚拟机可以自动完成这种优化。
从 37 变成 31,一个简单的数字变化,就能带来性能的提升。
个中奥秘,很有意思,有兴趣的可以去查阅一下相关资料。
真是神奇的计算机世界。
好了,这次的文章就到这里啦。
才疏学浅,难免会有纰漏,如果你发现了错误的地方,可以在留言区提出来,我对其加以修改。
感谢您的阅读,我坚持原创,十分欢迎并感谢您的关注。
我是 why 哥,一个被代码耽误的文学创作者,不是大佬,但是喜欢分享,是一个又暖又有料的四川好男人。
欢迎关注我呀。

以上是关于快来,我悄悄的给你说几个HashCode的破事。的主要内容,如果未能解决你的问题,请参考以下文章