ZooKeeper分析-Leader选举
Posted suixinm
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ZooKeeper分析-Leader选举相关的知识,希望对你有一定的参考价值。
Zookeeper的整体分析,了解了基本的运作原理和整体架构,即分布式系统中协调之力的重要性。本篇我们就来深入分析这个协调服务的服务器启动和Leader选举,带你更深入解读什么叫迷之自信的“自荐式”选举逻辑。
服务器启动
注:ZooKeeper分为单机启动和集群启动两种方式。本文仅分析集群启动这种方式。
DatadirCleanupManager
历史文件清理器。从3.4.0版本开始,ZooKeeper增加了自动清理历史数据文件的机制,包括对事务日志和快照数据文件进行定时清理。
判断该当前是集群模式还是单机模式启动
根据zoo.cfg中配置的多个服务器地址来判断。
QuorumPeer
集群模式下,ZooKeeper服务器实例(ZooKeeperServer)的托管者。代表着集群中的一台机器。在运行期间,它会不断检测当前服务器实例的运行状态,同时根据情况发起Leader选举。
恢复本地数据
暂时不做分析。
Leader选举
具体实现在后面章节进行分析。
源码分析
由ZooKeeper的启动脚本中,可以得知,启动器为QuorumPeerMain。继续进入initializeAndRun(args)方法中。
从配置文件中,可以得知,是否为集群启动方式。当配置为单机启动方式时,默认走ZooKeeperServerMain.main(args)分支。关于单机启动,本文暂时不做分析。继续进入runFromConfig(config)方法中。
上文已经提到,从3.4.0版本开始,ZooKeeper引入了Netty。可以通过zookeeper.serverCnxnFactory来指定使用具体的实现。静态方法createFactory()方法就是通过反射,调用默认构造函数,获取一个连接工厂的实例。
QuorumPeer意为托管者。在ZooKeeper实例启动时,还未确定身份时,由托管者引导ZooKeeper的启动流程。(它是线程Thread的一个实现类)
接着看runFromConfig(config)的后半段。
很明显,上面的逻辑就是将参数设置到QuorumPeer的实例中。并由start()方法启动整个ZooKeeper实例。
接着看,start()方法。
进到这里,主逻辑已经全部展现在眼前了。恢复本地数据暂时不做分析,Leader选举在后面进行分析。
接着,进入startServerCnxnFactory()方法。
如果选择Netty的实现作为连接工厂,那么,进入NettyServerCnxnFactory的start()方法。
此时,只有一步操作,就是绑定端口。当然了,仅仅绑定端口,是不足以处理发送过来的请求的。那么,关注一下NettyServerCnxnFactory的构造函数。
上文提到过,连接工厂是通过反射获取实例的。也就是说,早在runFromConfig(config)方法中,channelHandler(CnxnChannelHandler是非常重要的类。它是NettyServerCnxnFactory的内部类,实现了Netty的接口,来响应网络事件。)已经设置到Netty中,只是还没有绑定端口。
接着,回到QuorumPeer的start()方法中。
在startLeaderElection()方法执行完后,所有逻辑结束了吗?答案是,没有结束。因为QuorumPeer还重写了run()方法。
接着进入run()方法中。
这段逻辑几乎可以忽略。
下面这段逻辑是根据选举后的状态来进行不同角色的初始化流程的。
在选举结束后,判断自己的选举结果。举例来说,当实例成为Leader时,会走LEADING分支,makeLeader就是创建一个Leader对象。在创建Leader过程中,同时创建了LeaderZooKeeperServer(LeaderZooKeeperServer是非常重要的一个类,它是ZooKeeperServer的一个拓展。)。最后,调用Leader的lead()方法。
接着,进入lead()方法中。
Leader的lead()方法非常的长,也非常的复杂,其中有一个操作,是将LeaderZooKeeperServer设置到QuorumPeer实例中。Leader对象在创建时,便绑定了QuorumPeer,其变量名为self。(推测:在没有确定服务器的身份时,QuorumPeer作为托管者,来引导服务器的启动,当确定了Leader身份后,程序在QuorumPeer的基础上构建了Leader对象,并认为两者在认知上,是同一个概念。)
接着,进入setZooKeeperServer(zk)方法中。
为ServerCnxnFactory (NettyServerCnxnFactory的实例)设置ZooKeeperServer(LeaderZooKeeperServer的实例),所有逻辑便能够串联起来了。
关于Leader和Follower流程,具体的源码实现,暂时不再展开。
Leader选举
在上文提到过,ZooKeeper提供了三种Leader选举的算法,分别是LeaderElection、UDP版本的FastLeaderElection和TCP版本的FastLeaderElection,可以通过配置文件zoo.cfg中使用electionAlg属性来指定,分别使用数字0~3来表示。从3.4.0版本开始,ZooKeeper废弃了前两种选举算法。下文只介绍第三种算法。
选举的场景
1.服务器初始化启动。
2.服务器运行期间无法和Leader保持连接。
算法简述
1.处于LOOKING状态的服务器,将自己作为被推举的对象来进行投票,向集群中的所有其他机器发送消息。在这个投票消息中,包含两个最基本的信息:服务器的SID和ZXID,分别表示了被推举服务器的唯一标识和事务ID。
2.集群中的每台机器在发出自己的投票后,也会接收到来自集群中的其他机器的投票。接着,将收到的和自己的投票进行比较,选择ZXID大的投票重新作为自己的投票(当ZXID一致时,则以SID大的为判断条件),重新发起投票。
3.经过这两次投票后,再次统计投票。如果一台机器收到了超过半数的相同的投票,那么这个投票对应的SID机器即为Leader。
图示
交互过程
QuorumCnxManager
负责每台服务器之间底层Leader选举过程中的网络通信的管理器。在这个类的内部维护了一系列的队列,用于保存接收到的、待发送的消息,以及消息的发送器。
SendWorker
消息发送器,对应一台远程的ZooKeeper服务器,负责消息的发送。
RecvWorker
消息接收器,不断从TCP连接中读取消息,并将其保存到recvQueue队列中。
WorkerSender
选票发送器,会不断从sendqueue队列中获取待发送的选票,并将其传递到底层QuorumCnxManager中去。
WorkerReceiver
选票接收器。负责不断从QuorumCnxManager中获取出其他服务器发来的选举消息,并将其转化成一个选票,保存到recvqueue队列中去。
选举算法
源码分析
进入QuorumPeer的start()方法中,关注startLeaderElection()方法。在上文中,我们跳过了选举的过程,现在开始从这个方法开始切入。
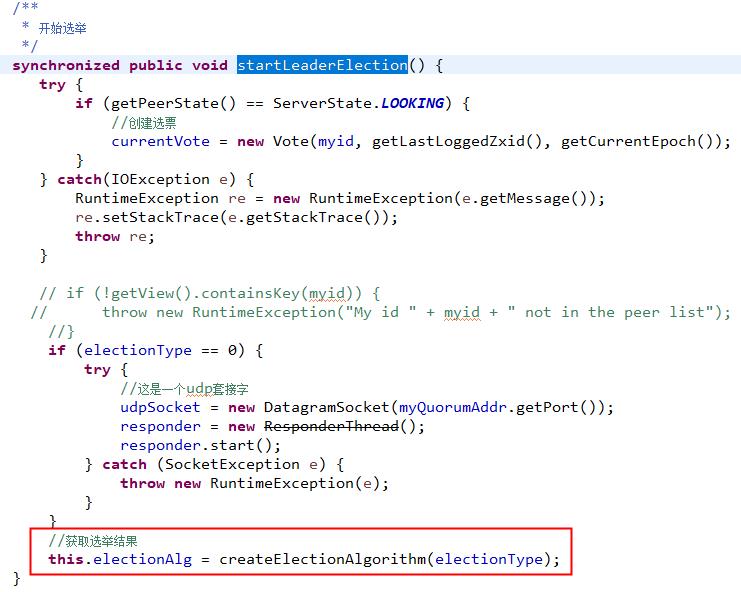
先创建一张默认选票,很明显,这张选票是投给自己的。然后,根据选举类型,来获取选举具体的实现。

这里的代码说明了,ZooKeeper废弃了之前的算法。createCnxnManager()方法创建了QuorumCnxManager对象,负责和其他服务器的底层交互。
进入listener.start()方法中。
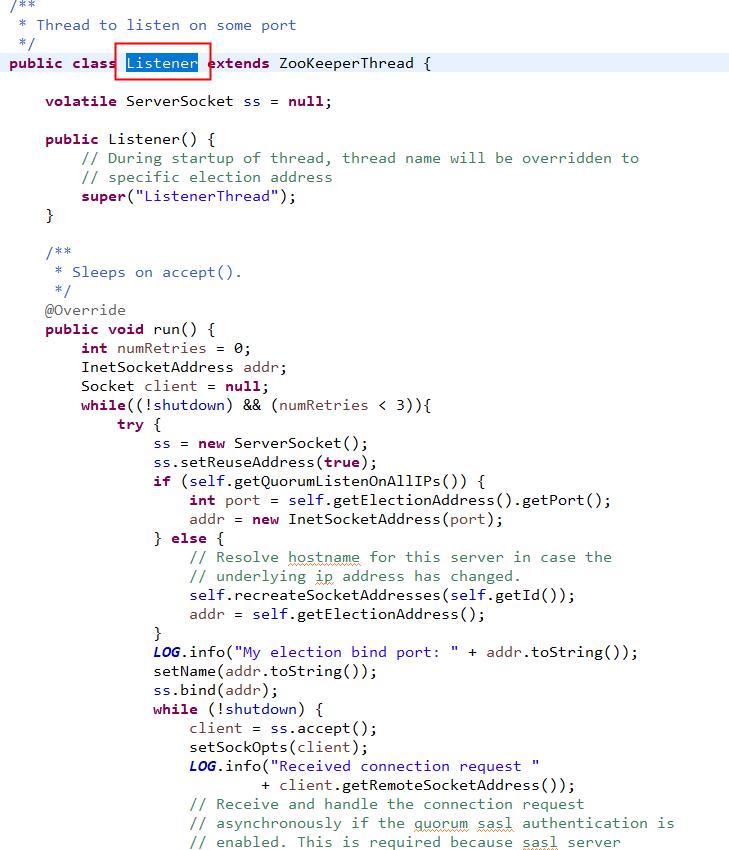
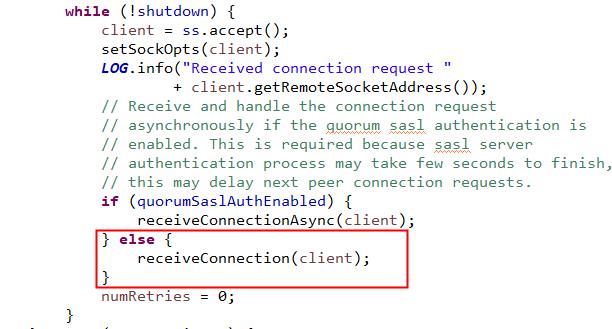

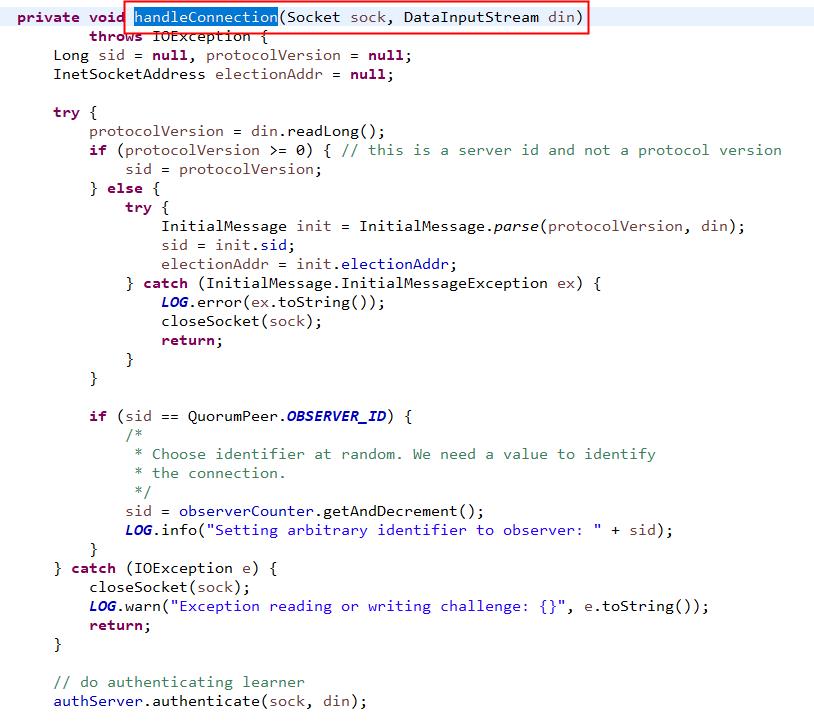
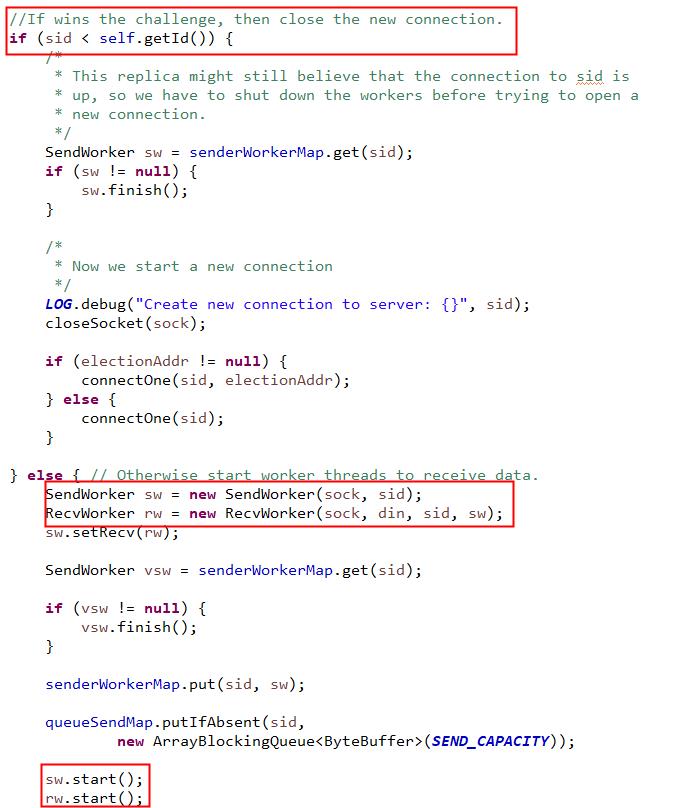
listener.start()方法,在方法中调用关系比较多,但是最终还是来到上图的逻辑中。在角色定位上,Listener是负责监听端口,创建连接的监听器。为了避免两台机器之间重复创建TCP连接,ZooKeeper设计了一种建立TCP连接的规则:只允许SID大的服务器主动和其他服务器建立连接,否则断开连接。
一旦建立了连接,就会根据远程服务器的SID来创建相应的消息发送器SendWorker和消息接收器ReceWorker,并启动他们。
接着,查看QuorumPeer的run方法。

在listener.start()方法被调用时,连接其实还未创建,在run()方法里,调用了lookForLeader()方法,也就是图示中选举算法的实现的地方。
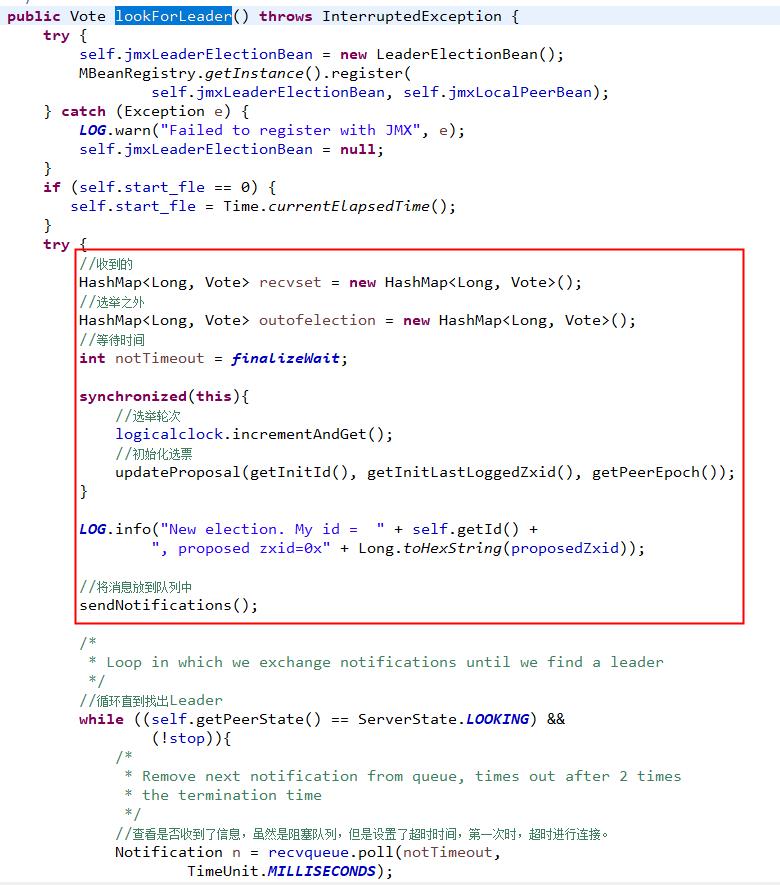
标识中的代码,初始化选票,并添加到指定队列中。
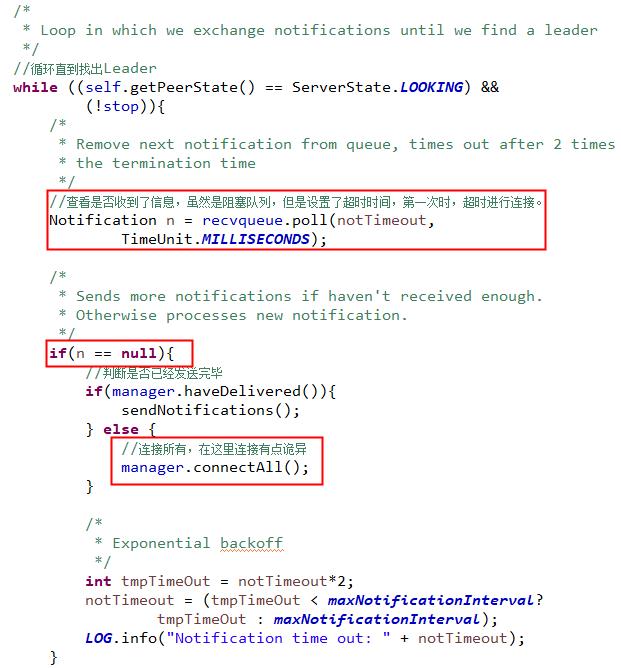
在第一次启动时,上面是变量n肯定为null,并且会走到connectAll()。真正进行连接的地方,也就是在这里。
接着看下面的代码。

在上面的逻辑中,判断收到的选票的信息,是否为LOOKING状态,接着判断选举轮次是否一致,一致则进行选票PK,如果变更了投票,则发送自己的投票。

不管是否变更了投票,都会统计投票,当某个ZooKeeper实例的选票达到半数以上,则确认该服务器为Leader
以上是关于ZooKeeper分析-Leader选举的主要内容,如果未能解决你的问题,请参考以下文章