再学Canal
Posted Shi Peng
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了再学Canal相关的知识,希望对你有一定的参考价值。
一、Canal简介
canal 是用于解析 mysql 增量日志,提供增量数据订阅。
日志增量订阅的业务包括:
1)数据库实时备份
2)索引构建和实时维护(拆分异构索引、倒排索引等)
3)数据库更新后, cache 实时刷新
4)带业务逻辑的增量数据处理
1.1、Canal官方架构图

1.3、Canal原理
Canal的原理基于MySQL主备复制原理:

1)MySQL master 将数据变更写入二进制日志( binary log, 其中记录叫做二进制日志事件binary log events,可以通过 show binlog events 进行查看)
2)MySQL slave 将 master 的 binary log events 拷贝到它的中继日志(relay log)
3)MySQL slave 重放 relay log 中事件,将数据变更反映它自己的数据
canal 工作原理:
1)canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议
2)MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal Server)
3)canal 解析 binary log 对象(原始为 byte 流)
1.3、Canal的客户端多语言支持方式
方式1:多语言客户端
Canal支持 Server-Client 模式
Canal提供了多语言的客户端,用于读取Canal解析后的增量日志。
方式2:借助于MQ的多语言客户端
Canal也支持把增量日志的变更投递到MQ,借助于MQ的多语言客户端来实现多语言消费Canal。
二、Canal Server架构设计详解
2.1、MySQL的binlog简介
1)mysql的binlog是多文件存储
2)通过 binlog filename + binlog position 定位一个LogEvent
mysql的binlog数据格式,按照生成的方式,主要分为:statement-based、row-based、mixed。
mysql> show variables like 'binlog_format';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| binlog_format | ROW |
+---------------+-------+
1 row in set (0.00 sec)
目前canal支持所有模式的增量订阅(但配合同步时,因为statement只有sql,没有数据,无法获取原始的变更日志,所以一般建议为ROW模式)
2.2、Canal Server的架构图
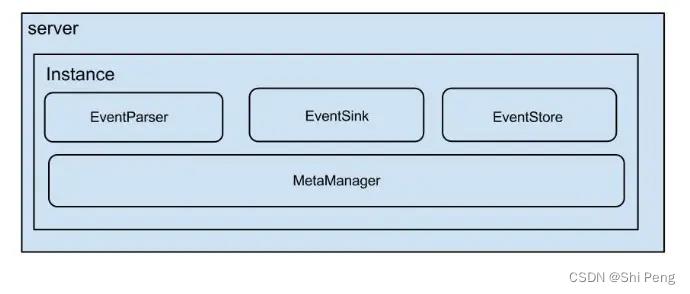
1、server代表一个canal运行实例,对应于一个JVM
2、instance对应于一个数据队列 (1个server对应n个instance)
对于每个instance,包含的模块:
1)eventParser :数据源接入,模拟slave协议和master进行交互,协议解析
2)eventSink :Parser和Store链接器,进行数据过滤,加工,分发的工作
3)eventStore :数据存储,供client消费
4)metaManager :增量订阅&消费信息管理器
2.2.1、EventParser设计
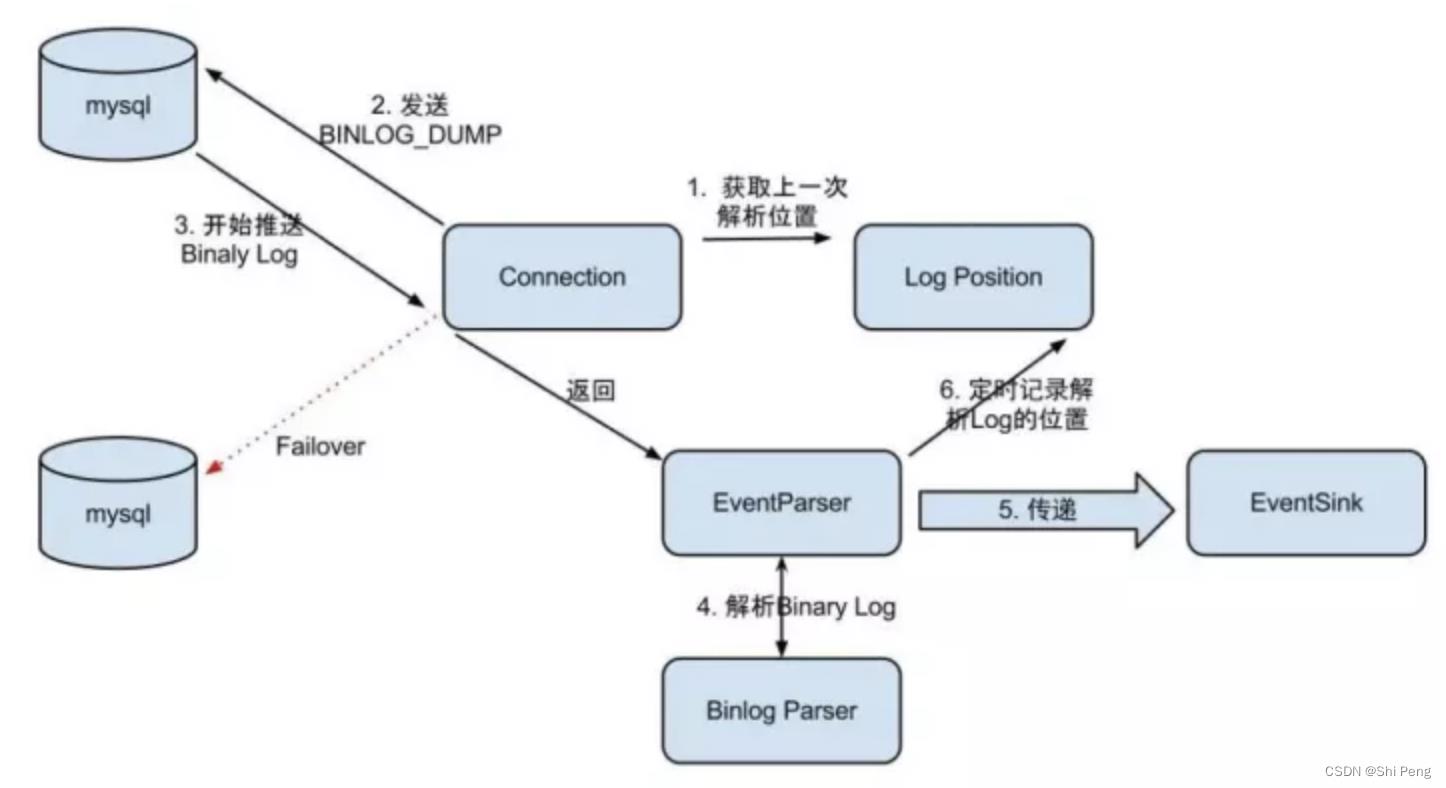
Parser执行步骤如下:
1)Connection前先获取上一次解析成功的位置 (如果第一次启动,则获取初始指定的位置或者是当前数据库的binlog位点)
2)Connection建立链接,发送BINLOG_DUMP指令
3)MySQL开始推送Binaly Log给Canal
4)Canal接收到binlog后,通过parser进行协议解析:补充一些特定信息,如补充字段名字,字段类型,主键信息,unsigned类型处理
5)传递给EventSink模块进行数据存储,是一个串行阻塞操作,直到存储成功,再处理下一条
6)存储成功后,定时记录Binaly Log位置
总结:Parser模块从MySQL拉取增量日志时,也是要传递上一次拉取成功的offset作为参数的。
MySQL binlog的发送接收流程:
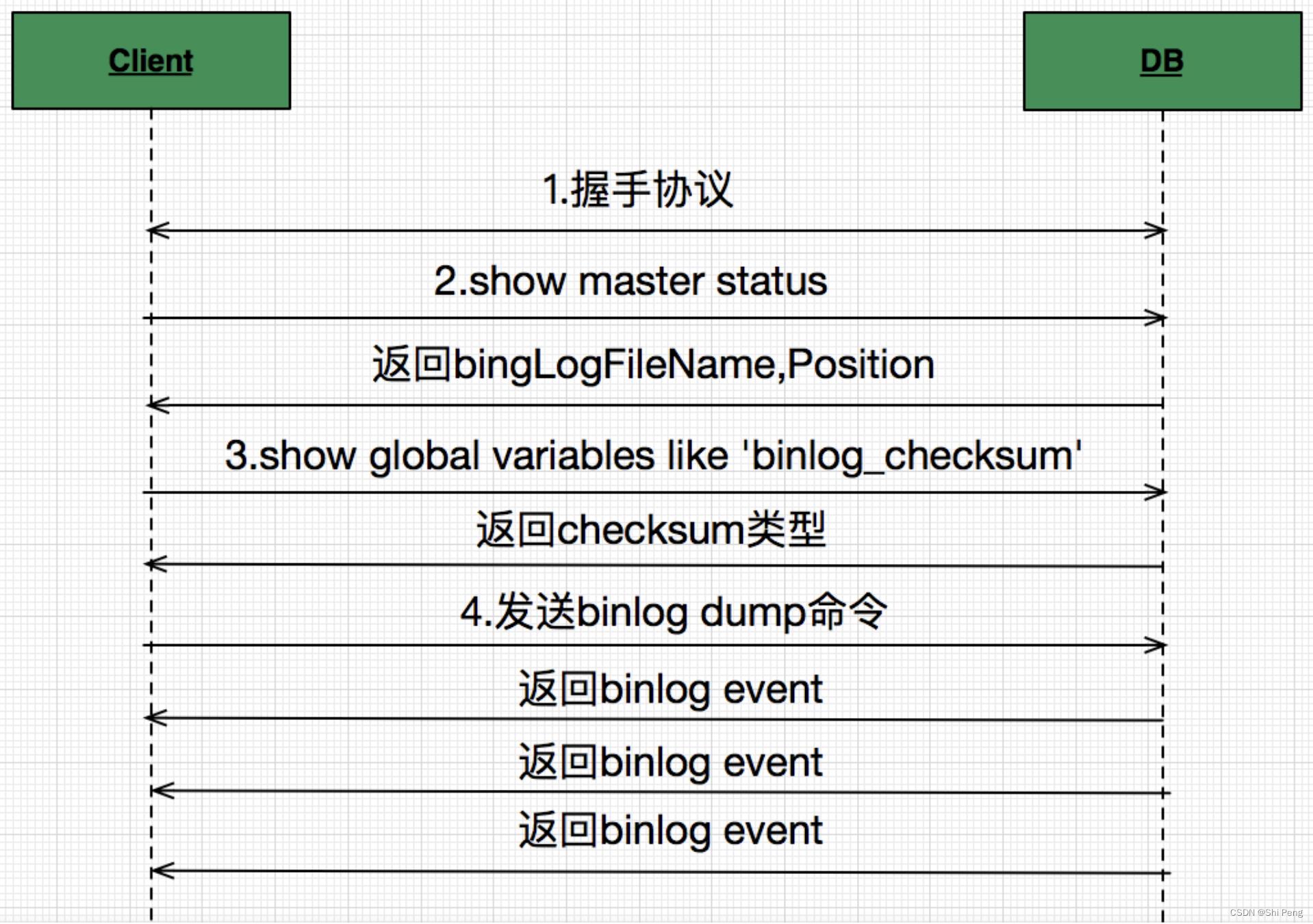
Step1:通过HandShake协议进行Client和DB的握手认证
Step2:握手成功以后,Client对DB发送show master status命令,此命令中回带回当前最新binlog存储在哪个文件,以及对应哪个偏移量。如果想从当前开始接收binglog,则在后面发送binlog dump命令的时候用这两个值就好。
Step3:发送show global variables like 'binlog_checksum’命令,这是由于binlog event发送回来的时候需要,在最后获取event内容的时候,会增加4个额外字节做校验用。mysql5.6.5以后的版本中binlog_checksum=crc32,而低版本都是binlog_checksum=none。如果不想校验,可以使用set命令设置set binlog_checksum=none
Step4:向MySQL发送Dump命令
Dump命令包图:

如上图所示,在报文中塞入binlogPosition和binlogFileName即可让master从相应的位置发送binlog event。
一旦发送了BinlogDump命令,master就会在数据库有变化的源源不断的推送binlog event到client。
binlog的类型有三种:
1)Statement:每一条会修改数据的sql都会记录在binlog中。
2)Row:不记录sql语句上下文相关信息,仅保存哪条记录被修改。
3)Mixedlevel:以上两种Level的混合。
2.2.2、EventSink设计
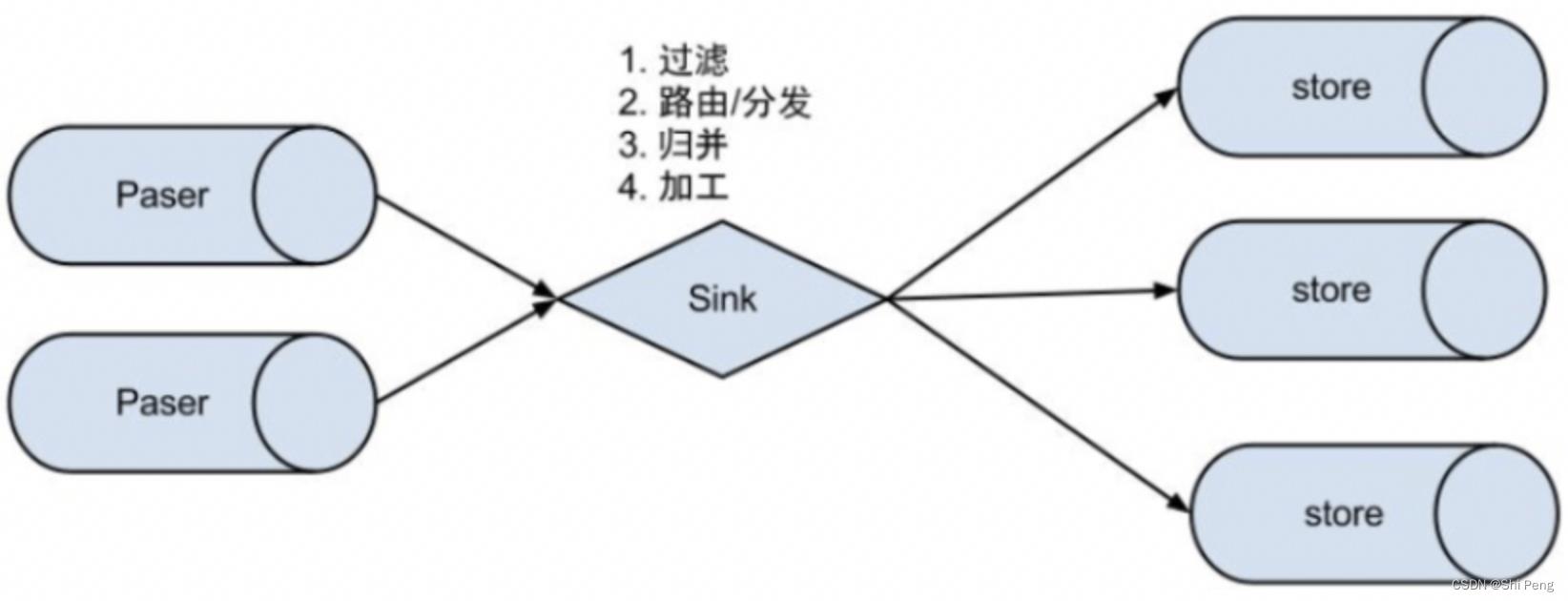
1、数据过滤:支持通配符的过滤模式,表名,字段内容等
2、数据路由/分发:解决1:n (1个parser对应多个store的模式)
3、数据归并:解决n:1 (多个parser对应1个store)
4、数据加工:在进入store之前进行额外的处理,比如join
2.2.2.1、数据1:n业务
为了合理的利用数据库资源, 一般常见的业务都是按照schema进行隔离,然后在mysql上层或者dao这一层面上,进行一个数据源路由,屏蔽数据库物理位置对开发的影响,阿里系主要是通过cobar/tddl来解决数据源路由问题。
所以,一般一个数据库实例上,会部署多个schema,每个schema会有由1个或者多个业务方关注
总结:parser和store为1:n,对于nebula而言,可以是一个storage的wal对应多个业务消费,即多套store,每个业务的过滤规则都不同。
2.2.2.2、数据n:1业务
同样,当一个业务的数据规模达到一定的量级后,必然会涉及到水平拆分和垂直拆分的问题,针对这些拆分的数据需要处理时,就需要链接多个store进行处理,消费的位点就会变成多份,而且数据消费的进度无法得到尽可能有序的保证。
所以,在一定业务场景下,需要将拆分后的增量数据进行归并处理,比如按照时间戳/全局id进行排序归并.
总结:如果数据库数据量非常大,经历了拆库拆表后,那么为了提高消费速度,可以由多个parser并行处理,但这样会导致数据乱序,所以后续再重新做归并排序。
2.2.3、EventStore设计
1、目前仅实现了Memory内存模式,后续计划增加本地file存储,mixed混合模式
2、借鉴了Disruptor的RingBuffer的实现思路
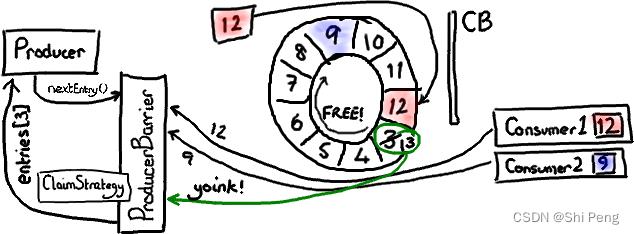
要注意的是,如果生成速度大于消费速度时,以上图为例,如果生产者想要写入 Ring Buffer 中序号 3 占据的节点,因为它是 Ring Buffer 当前游标的下一个节点。但是 ProducerBarrier 明白现在不能写入,因为有一个消费者正在占用它。所以,ProducerBarrier 停下来自旋 (spins),等待,直到那个消费者离开。
定义了3个cursor:
1)Put : Sink模块进行数据存储的最后一次写入位置
2)Get : 数据订阅获取的最后一次提取位置
3)Ack : 数据消费成功的最后一次消费位置
2.2.4、Instance设计

可以通过配置文件或者console这两种方式二选一在设置一个server启动几个instance。
instance代表了一个实际运行的数据队列,包括了EventPaser,EventSink,EventStore等组件。
2.2.5、Server设计

server代表了一个canal的运行实例,为了方便组件化使用,特意抽象了Embeded(嵌入式) / Netty(网络访问)的两种实现:
1)Embeded(嵌入式):对latency和可用性都有比较高的要求,自己又能hold住分布式的相关技术(比如failover)-- 例如,可以把Canal Server跟数据库部署在相同的服务器上,但当Canal Server的instance实例故障时,需要自己包装failover,如果可以一个instance对应一个套增量日志,那么当instance故障时,可以通过运维命令自动拉起。
2)Netty(RPC框架):基于netty封装了一层网络协议,由canal server保证其可用性,采用的pull模型,当然latency会稍微打点折扣,不过这个也视情况而定。(阿里系的notify和metaq,典型的push/pull模型,目前也逐步的在向pull模型靠拢,push在数据量大的时候会有一些问题)。
2.2.6、增量订阅设计

具体的协议格式,可参见:https://github.com/alibaba/canal/blob/master/protocol/src/main/java/com/alibaba/otter/canal/protocol/CanalProtocol.proto
get/ack/rollback协议介绍:
1)Message getWithoutAck(int batchSize),允许指定batchSize,一次可以获取多条,每次返回的对象为Message,包含的内容为:
a. batch id 唯一标识
b. entries 具体的数据对象,对应的数据对象格式:https://github.com/alibaba/canal/blob/master/protocol/src/main/java/com/alibaba/otter/canal/protocol/EntryProtocol.proto
2)void rollback(long batchId),顾命思议,回滚上次的get请求,重新获取数据。基于get获取的batchId进行提交,避免误操作
3)void ack(long batchId),顾命思议,确认已经消费成功,通知server删除数据。基于get获取的batchId进行提交,避免误操作
canal的get/ack/rollback协议和常规的jms协议有所不同,允许get/ack异步处理,比如可以连续调用get多次,后续异步按顺序提交ack/rollback,项目中称之为流式api.
流式api设计的好处:
- get/ack异步化,减少因ack带来的网络延迟和操作成本 (99%的状态都是处于正常状态,异常的rollback属于个别情况,没必要为个别的case牺牲整个性能)
- get获取数据后,业务消费存在瓶颈或者需要多进程/多线程消费时,可以不停的轮询get数据,不停的往后发送任务,提高并行化. (作者在实际业务中的一个case:业务数据消费需要跨中美网络,所以一次操作基本在200ms以上,为了减少延迟,所以需要实施并行化)
流式API设计:

- 每次get操作都会在meta中产生一个mark,mark标记会递增,保证运行过程中mark的唯一性
- 每次的get操作,都会在上一次的mark操作记录的cursor继续往后取,如果mark不存在,则在last ack cursor继续往后取
- 进行ack时,需要按照mark的顺序进行数序ack,不能跳跃ack. ack会删除当前的mark标记,并将对应的mark位置更新为last ack cusor
- 一旦出现异常情况,客户端可发起rollback情况,重新置位:删除所有的mark, 清理get请求位置,下次请求会从last ack cursor继续往后取
2.2.7、数据对象格式
数据对象格式:https://github.com/alibaba/canal/blob/master/protocol/src/main/java/com/alibaba/otter/canal/protocol/EntryProtocol.proto
每次调用get, 访问master的增量日志,返回数据格式如下:
Entry
Header
logfileName [binlog文件名]
logfileOffset [binlog position]
executeTime [binlog里记录变更发生的时间戳]
schemaName [数据库实例]
tableName [表名]
eventType [insert/update/delete类型]
entryType [事务头BEGIN/事务尾END/数据ROWDATA]
storeValue [byte数据,可展开,对应的类型为RowChange]
RowChange
isDdl [是否是ddl变更操作,比如create table/drop table]
sql [具体的ddl sql]
rowDatas [具体insert/update/delete的变更数据,可为多条,1个binlog event事件可对应多条变更,比如批处理]
beforeColumns [Column类型的数组]
afterColumns [Column类型的数组]
Column
index [column序号]
sqlType [jdbc type]
name [column name]
isKey [是否为主键]
updated [是否发生过变更]
isNull [值是否为null]
value [具体的内容,注意为文本]
说明:
1)可以提供数据库变更前和变更后的字段内容,针对binlog中没有的name,isKey等信息进行补全
2)可以提供ddl的变更语句
2.2.8、HA机制设计
canal的ha分为两部分,canal server和canal client分别有对应的ha实现
1)canal server: 为了减少对mysql dump的请求,不同server上的instance要求同一时间只能有一个处于running,其他的处于standby状态.
2)canal client: 为了保证有序性,一份instance同一时间只能由一个canal client进行get/ack/rollback操作,否则客户端接收无法保证有序。

1、canal server要启动某个canal instance时都先向zookeeper进行一次尝试启动判断 (实现:创建EPHEMERAL节点,谁创建成功就允许谁启动)
2、创建zookeeper节点成功后,对应的canal server就启动对应的canal instance,没有创建成功的canal instance就会处于standby状态
3、一旦zookeeper发现canal server A创建的节点消失后,立即通知其他的canal server再次进行步骤1的操作,重新选出一个canal server启动instance.
4、canal client每次进行connect时,会首先向zookeeper询问当前是谁启动了canal instance,然后和其建立链接,一旦链接不可用,会重新尝试connect.
Canal Client的方式和canal server方式类似,也是利用zookeeper的抢占EPHEMERAL节点的方式进行控制。
三、Canal Server源码解析
3.1、EventParser
3.1.1、EventParser的架构设计图:

其关键步骤如下:
1、从 Log Position 管理器中获取上一次解析的日志位点。
2、向 Mysql Master 节点发送 BINLOG_DUMP 请求。
3、Mysql Master 节点从 Slave 端传入的日志位点开始向从节点推送 binlog 日志。
4、Slave 接收 binlog 日志,调用 BinlogParser 解析 binlog日志。
5、将解析后的结构化数据传入到 EventSink 组件。
6、定时记录解析 binlog 的日志,以便重启后继续进行增量订阅。
7、上图中还罗列一个HA 特性,即需要同步的 Master 如果宕机,可以从它的其他从节点继续同步 binlog 日志,避免单点故障。
EventParser关键类的关系:
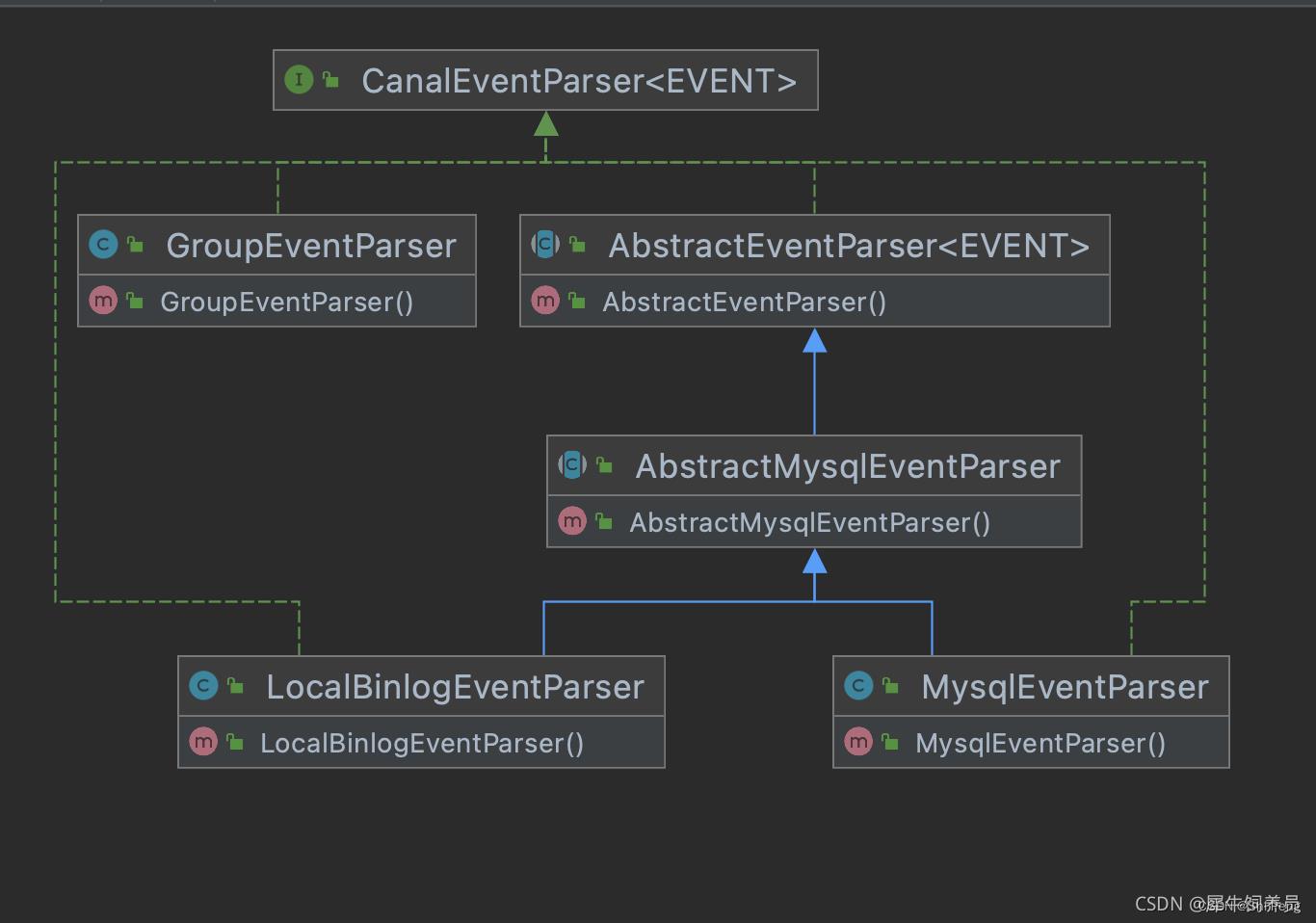
3.1.2、源码之EventParser初始化
CanalInstanceWithManager.java的CanalInstanceWithManager方法,是instance的启动入口。
public CanalInstanceWithManager(Canal canal, String filter)
this.parameters = canal.getCanalParameter();
this.canalId = canal.getId();
this.destination = canal.getName();
this.filter = filter;
logger.info("init CanalInstance for - with parameters:", canalId, destination, parameters);
// 初始化报警机制
initAlarmHandler();
// 初始化metaManager
initMetaManager();
// 初始化eventStore
initEventStore();
// 初始化eventSink
initEventSink();
// 初始化eventParser;
initEventParser();
...
下面看initEventParser方法:
protected void initEventParser()
logger.info("init eventParser begin...");
SourcingType type = parameters.getSourcingType();
/*
* Step1:获取数据库连接信息:
* 其中List<List<DataSourcing>>集合List<DataSourcing>中第一个元素是主库地址,第二个元素是从库地址
* 对于MySQL分库分表场景:加入192.168.1.166:3306为主,对应从为192.168.1.167:3306;
* 另一个主为192.168.1.168:3306,对应的从为192.168.1.169:3306,
* 那么,对应到List<List<DataSourcing>>为:
* List<List<DataSourcing>>的第一个元素List<DataSourcing>为192.168.1.166,和192.168.1.168组成的List
* 第二个元素List<DataSourcing>为192.168.1.167 和 192.168.1.169组成的List
*/
List<List<DataSourcing>> groupDbAddresses = parameters.getGroupDbAddresses();
if (!CollectionUtils.isEmpty(groupDbAddresses))
// 此size对应上面例子,即为所有主的数量
int size = groupDbAddresses.get(0).size();// 取第一个分组的数量,主备分组的数量必须一致
List<CanalEventParser> eventParsers = new ArrayList<>();
for (int i = 0; i < size; i++)
List<InetSocketAddress> dbAddress = new ArrayList<>();
SourcingType lastType = null;
for (List<DataSourcing> groupDbAddress : groupDbAddresses)
if (lastType != null && !lastType.equals(groupDbAddress.get(i).getType()))
throw new CanalException(String.format("master/slave Sourcing type is unmatch. %s vs %s",
lastType,
groupDbAddress.get(i).getType()));
lastType = groupDbAddress.get(i).getType();
dbAddress.add(groupDbAddress.get(i).getDbAddress());
// 对于每个主节点,初始化一个eventParser实例
eventParsers.add(doInitEventParser(lastType, dbAddress));
if (eventParsers.size() > 1) // 如果存在分组,构造分组的parser
GroupEventParser groupEventParser = new GroupEventParser();
groupEventParser.setEventParsers(eventParsers);
this.eventParser = groupEventParser;
else
this.eventParser = eventParsers.get(0);
else
// 创建一个空数据库地址的parser,可能使用了tddl指定地址,启动的时候才会从tddl获取地址
this.eventParser = doInitEventParser(type, new ArrayList<>());
logger.info("init eventParser end! \\n\\t load CanalEventParser:", eventParser.getClass().getName());
Step1:获取数据库连接信息:
其中List<List>集合List中第一个元素是主库地址,第二个元素是从库地址
对于MySQL分库分表场景:加入192.168.1.166:3306为主,对应从为192.168.1.167:3306;
另一个主为192.168.1.168:3306,对应的从为192.168.1.169:3306,
那么,对应到List<List>为:
List<List>的第一个元素List为192.168.1.166,和192.168.1.168组成的List
第二个元素List为192.168.1.167 和 192.168.1.169组成的List
Step2:根据配置的 MySQL ,为每个主节点,初始化一个EventParser的实例:
eventParsers.add(doInitEventParser(lastType, dbAddress));
下面看doInitEventParser方法的实现:
private CanalEventParser doInitEventParser(SourcingType type, List<InetSocketAddress> dbAddresses)
CanalEventParser eventParser;
if (type.isMysql())
MysqlEventParser mysqlEventParser = null;
...
else if (type.isLocalBinlog())
LocalBinlogEventParser localBinlogEventParser = new LocalBinlogEventParser();
...
else if (type.isOracle())
throw new CanalException("unsupport SourcingType for " + type);
else
throw new CanalException("unsupport SourcingType for " + type);
// add transaction support at 2012-12-06
if (eventParser instanceof AbstractEventParser)
AbstractEventParser abstractEventParser = (AbstractEventParser) eventParser;
...
if (eventParser instanceof MysqlEventParser)
MysqlEventParser mysqlEventParser = (MysqlEventParser) eventParser;
// 初始化haController,绑定与eventParser的关系,haController会控制eventParser
CanalHAController haController = initHaController();
mysqlEventParser.setHaController(haController);
return eventParser;
可以看出目前Canal不支持oracle,仅支持MySQL和本地binlog文件(直接从binlog日志文件解析)。
Step3:MySQL的binlog解析
这里忽略掉跟阿里云相关的RDS,TSDB的支持,仅重点关注开源MySQL相关的binlog解析逻辑:
if (type.isMysql())
MysqlEventParser mysqlEventParser = null;
if (StringUtils.isNotEmpty(parameters.getRdsAccesskey())
&& StringUtils.isNotEmpty(parameters.getRdsSecretkey())
&& StringUtils.isNotEmpty(parameters.getRdsInstanceId()))
mysqlEventParser = new RdsBinlogEventParserProxy();
((RdsBinlogEventParserProxy) mysqlEventParser).setAccesskey(parameters.getRdsAccesskey());
((RdsBinlogEventParserProxy) mysqlEventParser).setSecretkey(parameters.getRdsSecretkey());
((RdsBinlogEventParserProxy) mysqlEventParser).setInstanceId(parameters.getRdsInstanceId());
else
mysqlEventParser = new MysqlEventParser();
mysqlEventParser.setDestination(destination);
// 编码参数
mysqlEventParser.setConnectionCharset(parameters.getConnectionCharset());
mysqlEventParser.setConnectionCharsetNumber(parameters.getConnectionCharsetNumber());
// 网络相关参数
mysqlEventParser.setDefaultConnectionTimeoutInSeconds(parameters.getDefaultConnectionTimeoutInSeconds());
mysqlEventParser.setSendBufferSize(parameters.getSendBufferSize());
mysqlEventParser.setReceiveBufferSize(parameters.getReceiveBufferSize());
// 心跳检查参数
mysqlEventParser.setDetectingEnable(parameters.getDetectingEnable());
mysqlEventParser.setDetectingSQL(parameters.getDetectingSQL());
mysqlEventParser.setDetectingIntervalInSeconds(parameters.getDetectingIntervalInSeconds());
// 数据库信息参数
mysqlEventParser.setSlaveId(parameters.getSlaveId());
if (!CollectionUtils.isEmpty(dbAddresses))
mysqlEventParser.setMasterInfo(new AuthenticationInfo(dbAddresses.get(0),
parameters.getDbUsername(),
parameters.getDbPassword(),
parameters.getDefaultDatabaseName()));
if (dbAddresses.size() > 1)
mysqlEventParser.setStandbyInfo(new AuthenticationInfo(dbAddresses.get(1),
parameters.getDbUsername(),
parameters.getDbPassword(),
parameters.getDefaultDatabaseName()));
MySQL 的 binlog 事件解析器实现类为 MysqlEventParser,下面看各参数的含义:
1)destination
Canal Instance 实例的名称。
2)connectionCharset
字符集,解析 binlog 时会将指定的字节数据使用该编码级进行转换,默认为UTF-8。
3)connectionCharsetNumber
字符集的数字表现形式,UTF8对应的值为 33,该值在与 MySQL 的交互协议包中需要被用到,这里 Canal 处理的不是特别好,最好该属性设置为只读,由 connectionCharset 联动进行设置。
4)defaultConnectionTimeoutInSeconds
MySQL 默认连接超时时间,因为 Canal 会伪装为 MySQL 服务器的 Slave 节点,需要向 MySQL Master 发送请求,故需要先创建链接,这里就是创建连接的默认超时时间,默认为 30s。
5)sendBufferSize
用于网络通道发送端缓存区,目前在 Canal 中网络通道的实现类为 BiosocketChannelPool、NettySocketChannelPool,从代码的角度来看,目前这个参数并不会生效,即使用操作系统的默认值。
6)receiveBufferSize
用于网络通道接收缓存区大小,目前同 sendBufferSize 参数,并不会生效。
7)detectingEnable
是否开启心跳检测,默认为开启。
8)detectingSQL
心跳检测语句,例如 select 1,show master status 等。
9)detectingIntervalInSeconds
心跳间隔检测,默认为 3s。
10)slaveId
从服务器的 id,在同一个 MySQL 复制组内不能重复。
Step4:如果设置了 CanalPrameter 的 Listpositions 属性,则将其解析为 EntryPosition 实体

代码为:
EntryPosition masterPosition = JsonUtils.unmarshalFromString(parameters.getPositions().get(0),
EntryPosition.class);
// binlog位置参数
mysqlEventParser.setMasterPosition(masterPosition);
EntryPosition主要的核心参数如下:
1)long timestamp
时间戳,用时间戳来表示位置
2)String journalName
binlog 日志的文件名,例如 mysql-bin.000001。
3)Long position
使用偏移量来表示具体位点。
4)long serverId
设置 master 的 id。
5)String gtid
全局事务ID。
Step5:继续设置参数
1)fallbackIntervalInSeconds
如果 MySQL 主节点宕机,Canal 支持切换到其从节点继续同步 binlog 日志,但为了数据的完整性,可以设置一个回退时间,即会造成数据重复下发,但尽量不丢失,该值默认为 60s。
2)profilingEnabled
是否开启性能采集,主要采集的是一批日志经过 EventSink 组件处理到完成 存入EventStore 的时间消耗。
3)filterTableError
是否忽略表过滤异常,默认为 false,表过滤会在后续文章中详细介绍。
4)parallel
解析、canal 接入 prometheus 采集监控数据是否支持并发,默认为 false。
5)isGTIDMode
是否开启 gtid 模式。
Step6:继续填充解析器相关参数
1)transactionSize
Canal 提供了一种机制,尝试将一个数据库事务中所有的变更日志一起进行处理,这个为处理缓存事务日志的缓存区长度,默认为 1024。
2)logPositionManager
初始化日志位点管理器,Canal 提供了基于内存、zookeeper、内存与zookeepr混合管理器等日志位点管理器
3)AviaterRegexFilter
提供了基于 aviater 的正则表达式,对 table 名称进行过滤。
4)blackFilter
canal 提供了黑名单配置,提供黑名单正则表达式对 table 名称进行过滤。
Step7:如果解析器是 MySQL 解析器,提供了 HA 机制
即如果 MySQL Master 宕机,Canal 还能主动切换到 MYSQL Slave 节点,继续同步 binlog 日志。
相关代码为:
if (eventParser instanceof MysqlEventParser)
MysqlEventParser mysqlEventParser = (MysqlEventParser) eventParser;
// 初始化haController,绑定与eventParser的关系,haController会控制eventParser
CanalHAController haController = initHaController();
mysqlEventParser.setHaController(haController);
3.1.3、源码之EventParser 工作流程
入口:MysqlEventParser.java的start方法:
public void start() throws 以上是关于再学Canal的主要内容,如果未能解决你的问题,请参考以下文章