什么是粘包和拆包,Netty如何解决粘包拆包?
Posted 黄小斜
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了什么是粘包和拆包,Netty如何解决粘包拆包?相关的知识,希望对你有一定的参考价值。
Netty粘包拆包
TCP 粘包拆包是指发送方发送的若干包数据到接收方接收时粘成一包或某个数据包被拆开接收。
如下图所示,client 发送了两个数据包 D1 和 D2,但是 server 端可能会收到如下几种情况的数据。
上图中演示了粘包和拆包的三种情况:
- D1和D2两个包都刚好满足TCP缓冲区的大小,或者说其等待时间已经达到TCP等待时长,从而还是使用两个独立的包进行发送;
- D1和D2两次请求间隔时间内较短,并且数据包较小,因而合并为同一个包发送给服务端;
- D2包比较大,因而将其拆分为两个包D2_1和D2_2进行发送,而这里由于拆分后的D2_1比较小,其又与D1包合并在一起发送;
- D1包比较大,因而将其拆分为两个包D1_1和D1_2进行发送,而这里由于拆分后的D1_2比较小,其又与D2包合并在一起发送;
程序演示
首先准备客户端负责发送消息,连续发送5次消息,代码如下:
public void channelActive(ChannelHandlerContext ctx) throws Exception
for (int i = 1; i <= 5; i++)
ByteBuf byteBuf = Unpooled.copiedBuffer("msg No" + i + " ", Charset.forName("utf-8"));
ctx.writeAndFlush(byteBuf);

然后服务端作为接收方,接收并且打印结果:

// count 变量,用于计数
private int count;
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception
System.out.println("服务器读取线程 " + Thread.currentThread().getName());
ByteBuf buf = (ByteBuf) msg;
byte[] bytes = new byte[buf.readableBytes()];
// 把ByteBuf的数据读到bytes数组中
buf.readBytes(bytes);
String message = new String(bytes, Charset.forName("utf-8"));
System.out.println("服务器接收到数据:" + message);
// 打印接收的次数
System.out.println("接收到的数据量是:" + (++this.count));
启动服务端,再启动两个客户端发送消息,服务端的控制台可以看到这样:
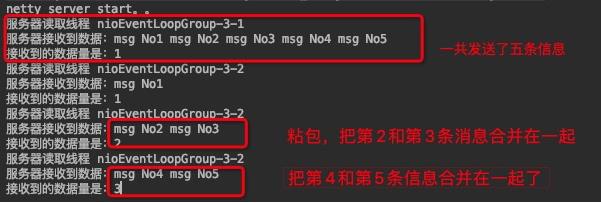
粘包的问题其实是随机的,所以每次结果都不太一样。
为什么出现粘包现象?
TCP是一个“流”协议,所谓流,就是没有界限的一长串二进制数据。TCP作为传输层协议并不了解上层业务数据的具体含义,它会根据TCP缓冲区的实际情况进行数据包的划分,
所以在业务上认为是一个完整的包,可能会被TCP拆分成多个包进行发送,也有可能把多个小的包封装成一个大的数据包发送,这就是所谓的TCP粘包和拆包问题。
例如,TCP缓冲区是1024个字节大小,如果应用一次请求发送的数据量比较小,没达到缓冲区大小,TCP则会将多个请求合并为同一个请求进行发送,这就形成了粘包问题;
如果应用一次请求发送的数据量比较大,超过了缓冲区大小,TCP就会将其拆分为多次发送,这就是拆包,也就是将一个大的包拆分为多个小包进行发送。
TCP 中可能出现粘包/拆包的原因
数据流在TCP协议下传播,因为协议本身对于流有一些规则的限制,这些规则会导致当前对端接收到的数据包不完整,归结原因有下面三种情况:
- Socket 缓冲区与滑动窗口
- MSS/MTU限制
- Nagle算法
1. Socket缓冲区与滑动窗口
对于 TCP 协议而言,它传输数据是基于字节流传输的。应用层在传输数据时,实际上会先将数据写入到 TCP 套接字的缓冲区,当缓冲区被写满后,数据才会被写出去。
每个TCP Socket 在内核中都有一个发送缓冲区(SO_SNDBUF )和一个接收缓冲区(SO_RCVBUF),TCP 的全双工的工作模式以及 TCP 的滑动窗口便是依赖于这两个独立的 buffer 以及此 buffer 的填充状态。
SO_SNDBUF:
进程发送数据的时候假设调用了一个 send 方法,将数据拷贝进入 Socket 的内核发送缓冲区之中,然后 send 便会在上层返回。
换句话说,send 返回之时,数据不一定会发送到对端去(和write写文件有点类似),send 仅仅是把应用层 buffer 的数据拷贝进 Socket 的内核发送 buffer 中。
SO_RCVBUF:
把接收到的数据缓存入内核,应用进程一直没有调用 read 进行读取的话,此数据会一直缓存在相应 Socket 的接收缓冲区内。
不管进程是否读取 Socket,对端发来的数据都会经由内核接收并且缓存到 Socket 的内核接收缓冲区之中。read 所做的工作,就是把内核缓冲区中的数据拷贝到应用层用户的 buffer 里面,仅此而已。
接收缓冲区保存收到的数据一直到应用进程读走为止。对于 TCP,如果应用进程一直没有读取,buffer 满了之后发生的动作是:通知对端 TCP 协议中的窗口关闭。
这个便是滑动窗口的实现。保证 TCP 套接口接收缓冲区不会溢出,从而保证了 TCP 是可靠传输。因为对方不允许发出超过所通告窗口大小的数据。
这就是 TCP 的流量控制,如果对方无视窗口大小而发出了超过窗口大小的数据,则接收方 TCP 将丢弃它。
滑动窗口:
1、TCP连接在三次握手的时候,会将自己的窗口大小(window size)发送给对方,其实就是 SO_RCVBUF 指定的值。之后在发送数据的时,发送方必须要先确认接收方的窗口没有被填充满,如果没有填满,则可以发送。
2、每次发送数据后,发送方将自己维护的对方的 window size 减小,表示对方的 SO_RCVBUF 可用空间变小。
3、当接收方处理开始处理 SO_RCVBUF 中的数据时,会将数据从 Socket 在内核中的接受缓冲区读出,此时接收方的 SO_RCVBUF 可用空间变大,即 window size 变大,
接受方会以 ack 消息的方式将自己最新的 window size 返回给发送方,此时发送方将自己的维护的接受的方的 window size 设置为ack消息返回的 window size。
此外,发送方可以连续的给接受方发送消息,只要保证对方的 SO_RCVBUF 空间可以缓存数据即可,即 window size>0。当接收方的 SO_RCVBUF 被填充满时,
此时 window size=0,发送方不能再继续发送数据,要等待接收方 ack 消息,以获得最新可用的 window size。
2. MSS/MTU分片
MTU (Maxitum Transmission Unit,最大传输单元):是链路层对一次可以发送的最大数据的限制。
MSS(Maxitum Segment Size,最大分段大小):是 TCP 报文中 data 部分的最大长度,是传输层对一次可以发送的最大数据的限制。
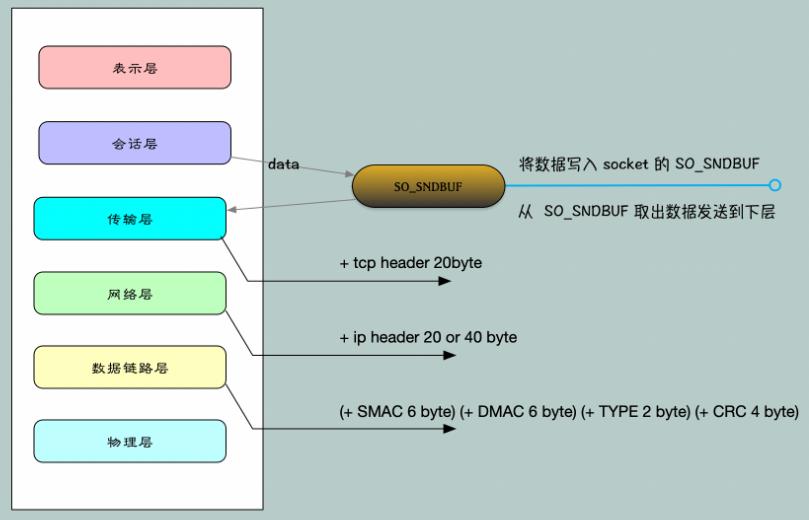
数据在传输过程中,每经过一层,都会加上一些额外的信息:
- 应用层:只关心发送的数据 data,将数据写入 Socket 在内核中的缓冲区 SO_SNDBUF 即返回,操作系统会将 SO_SNDBUF 中的数据取出来进行发送;
- 传输层:会在 data 前面加上 TCP Header(20字节);
- 网络层:会在 TCP 报文的基础上再添加一个 IP Header,也就是将自己的网络地址加入到报文中。IPv4 中 IP Header 长度是 20 字节,IPV6 中 IP Header 长度是 40 字节;
- 链路层:加上 Datalink Header 和 CRC。会将 SMAC(Source Machine,数据发送方的MAC地址),DMAC(Destination Machine,数据接受方的MAC地址 )和 Type 域加入。SMAC+DMAC+Type+CRC 总长度为 18 字节;
- 物理层:进行传输。
在回顾这个基本内容之后,再来看 MTU 和 MSS。MTU 是以太网传输数据方面的限制,每个以太网帧最大不能超过 1518bytes。刨去以太网帧的帧头(DMAC+SMAC+Type域) 14Bytes 和帧尾 (CRC校验 ) 4 Bytes,
那么剩下承载上层协议的地方也就是 data 域最大就只能有 1500 Bytes 这个值 我们就把它称之为 MTU。
MSS 是在 MTU 的基础上减去网络层的 IP Header 和传输层的 TCP Header 的部分,这就是 TCP 协议一次可以发送的实际应用数据的最大大小。
MSS = MTU(1500) -IP Header(20 or 40)-TCP Header(20)
由于 IPV4 和 IPV6 的长度不同,在 IPV4 中,以太网 MSS 可以达到 1460byte。在 IPV6 中,以太网 MSS 可以达到 1440byte。
发送方发送数据时,当 SO_SNDBUF 中的数据量大于 MSS 时,操作系统会将数据进行拆分,使得每一部分都小于 MSS,也形成了拆包。
然后每一部分都加上 TCP Header,构成多个完整的 TCP 报文进行发送,当然经过网络层和数据链路层的时候,还会分别加上相应的内容。
另外需要注意的是:对于本地回环地址(lookback)不需要走以太网,所以不受到以太网 MTU=1500 的限制。linux 服务器上输入 ifconfig 命令,可以查看不同网卡的 MTU 大小,如下:
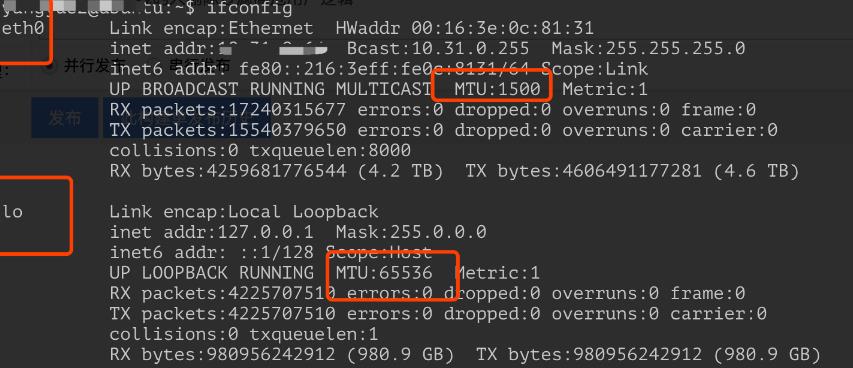
上图显示了 2 个网卡信息:
- eth0 需要走以太网,所以 MTU 是 1500;
- lo 是本地回环,不需要走以太网,所以不受 1500 的限制。
3. Nagle 算法
TCP/IP 协议中,无论发送多少数据,总是要在数据(data)前面加上协议头(TCP Header+IP Header),同时,对方接收到数据,也需要发送 ACK 表示确认。
即使从键盘输入的一个字符,占用一个字节,可能在传输上造成 41 字节的包,其中包括 1 字节的有用信息和 40 字节的首部数据。这种情况转变成了 4000% 的消耗,这样的情况对于重负载的网络来是无法接受的。称之为"糊涂窗口综合征"。
为了尽可能的利用网络带宽,TCP 总是希望尽可能的发送足够大的数据。(一个连接会设置 MSS 参数,因此,TCP/IP 希望每次都能够以 MSS 尺寸的数据块来发送数据)。Nagle 算法就是为了尽可能发送大块数据,避免网络中充斥着许多小数据块。
Nagle 算法的基本定义是任意时刻,最多只能有一个未被确认的小段。 所谓 “小段”,指的是小于 MSS 尺寸的数据块;所谓“未被确认”,是指一个数据块发送出去后,没有收到对方发送的 ACK 确认该数据已收到。
Nagle 算法的规则:
- 如果 SO_SNDBUF 中的数据长度达到 MSS,则允许发送;
- 如果该 SO_SNDBUF 中含有 FIN,表示请求关闭连接,则先将 SO_SNDBUF 中的剩余数据发送,再关闭;
- 设置了
TCP_NODELAY=true选项,则允许发送。TCP_NODELAY 是取消 TCP 的确认延迟机制,相当于禁用了 Negale 算法。正常情况下,当 Server 端收到数据之后,它并不会马上向 client 端发送 ACK,而是会将 ACK 的发送延迟一段时间(一般是 40ms),它希望在 t 时间内 server 端会向 client 端发送应答数据,这样 ACK 就能够和应答数据一起发送,就像是应答数据捎带着 ACK 过去。当然,TCP 确认延迟 40ms 并不是一直不变的, TCP 连接的延迟确认时间一般初始化为最小值 40ms,随后根据连接的重传超时时间(RTO)、上次收到数据包与本次接收数据包的时间间隔等参数进行不断调整。另外可以通过设置 TCP_QUICKACK 选项来取消确认延迟; - 未设置 TCP_CORK 选项时,若所有发出去的小数据包(包长度小于MSS)均被确认,则允许发送;
- 上述条件都未满足,但发生了超时(一般为200ms),则立即发送。
原因总结
基于以上问题,TCP层肯定是会出现当次接收到的数据是不完整数据的情况。
出现粘包可能的原因有:
- 发送方每次写入数据 < 套接字缓冲区大小;
- 接收方读取套接字缓冲区数据不够及时。
出现半包的可能原因有:
- 发送方每次写入数据 > 套接字缓冲区大小;
- 发送的数据大于协议 MTU,所以必须要拆包。
解决方案
解决问题肯定不是在4层来做而是在应用层,通过定义通信协议来解决粘包和拆包的问题。发送方 和 接收方约定某个规则:
- 当发生粘包的时候通过某种约定来拆包;
- 如果在拆包,通过某种约定来将数据组成一个完整的包处理。
一般解决粘包拆包问题有 4 种办法:
- 在数据的末尾添加特殊的符号标识数据包的边界。通常会加\\n、\\r、\\t或者其他的符号;
- 规定报文的长度,不足则补空位。读取时按规定好的长度来读取。比如 100 字节,如果不够就补空格;
- 将消息分为消息头和消息体,消息头中包含表示信息的总长度(或者消息体长度)的字段,按长度获取数据;
- 通过自定义协议进行粘包和拆包。
Netty粘包和拆包解决方案
为了解决网络数据流的拆包粘包问题,Netty 为我们内置了如下的解码器:
- FixedLengthFrameDecoder(使用定长的报文来分包)
- DelimiterBasedFrameDecoder(添加特殊分隔符报文来分包)
- LineBasedFrameDecoder(数据未尾添加回车换行符来分包)
- LengthFieldBasedFrameDecoder(使用消息头和消息体来分包)
- ByteToMessageDecoder(如果想实现自己的半包解码器,实现该类)
- MessageToMessageDecoder(一般作为二次解码器,当我们在 ByteToMessageDecoder 将一个 bytes 数组转换成一个 java 对象的时候,我们可能还需要将这个对象进行二次解码成其他对象,我们就可以继承这个类)
- StringDecoder(字符串解码器)
- ProtoBufVarint32FrameDecoder(通过 Protobuf 解码器来区分整包消息)
- ProtobufDecoder(Protobuf 解码器)
Netty 还内置了如下的编码器:
- MessageToByteEncoder(将 Java 对象编码成 ByteBuf)
- MessageToMessageEncoder(如果不想将 Java 对象编码成 ByteBuf,而是自定义类就继承这个)
- LengthFieldPrepender(如果我们在发送消息的时候采用:消息长度字段+原始消息的形式,我们就可以使用 LengthFieldPrepender。因为 LengthFieldPrepender 可以将待发送消息的长度(二进制字节长度)写到 ByteBuf 的前两个字节)
- ProtobufVarint32LengthFieldPrepender(Protobuf 编码器,在原来的数据前面,追加一个长度)
- ProtobufEncoder(Protobuf 编码器)
FixedLengthFrameDecoder解码器
对于使用固定长度的粘包和拆包场景,可以使用FixedLengthFrameDecoder,该解码器会每次读取固定长度的消息,如果当前读取到的消息不足指定长度,那么就会等待下一个消息到达后进行补足。
其使用也比较简单,只需要在构造函数中指定每个消息的长度即可。这里需要注意的是,FixedLengthFrameDecoder只是一个解码器,Netty也只提供了一个解码器,
这是因为对于解码是需要等待下一个包的进行补全的,代码相对复杂,而对于编码器,用户可以自行编写,因为编码时只需要将不足指定长度的部分进行补全即可。
下面的示例中展示了如何使用FixedLengthFrameDecoder来进行粘包和拆包处理:
public class EchoServer
public void bind(int port) throws InterruptedException
EventLoopGroup bossGroup = new NioEventLoopGroup();
EventLoopGroup workerGroup = new NioEventLoopGroup();
try
ServerBootstrap bootstrap = new ServerBootstrap();
bootstrap.group(bossGroup, workerGroup)
.channel(NioserverSocketChannel.class)
.option(ChannelOption.SO_BACKLOG, 1024)
.handler(new LoggingHandler(LogLevel.INFO))
.childHandler(new ChannelInitializer<SocketChannel>()
@Override
protected void initChannel(SocketChannel ch) throws Exception
// 这里将FixedLengthFrameDecoder添加到pipeline中,指定长度为20
ch.pipeline().addLast(new FixedLengthFrameDecoder(20));
// 将前一步解码得到的数据转码为字符串
ch.pipeline().addLast(new StringDecoder());
// 这里FixedLengthFrameEncoder是我们自定义的,用于将长度不足20的消息进行补全空格
ch.pipeline().addLast(new FixedLengthFrameEncoder(20));
// 最终的数据处理
ch.pipeline().addLast(new EchoServerHandler());
);
ChannelFuture future = bootstrap.bind(port).sync();
future.channel().closeFuture().sync();
finally
bossGroup.shutdownGracefully();
workerGroup.shutdownGracefully();
public static void main(String[] args) throws InterruptedException
new EchoServer().bind(8080);
上面的pipeline中,对于入栈数据,这里主要添加了FixedLengthFrameDecoder和StringDecoder,前面一个用于处理固定长度的消息的粘包和拆包问题,第二个则是将处理之后的消息转换为字符串。
最后由EchoServerHandler处理最终得到的数据,处理完成后,将处理得到的数据交由FixedLengthFrameEncoder处理,该编码器是我们自定义的实现,主要作用是将长度不足20的消息进行空格补全。
下面是FixedLengthFrameEncoder的实现代码:

public class FixedLengthFrameEncoder extends MessageToByteEncoder<String>
private int length;
public FixedLengthFrameEncoder(int length)
this.length = length;
@Override
protected void encode(ChannelHandlerContext ctx, String msg, ByteBuf out)
throws Exception
// 对于超过指定长度的消息,这里直接抛出异常
if (msg.length() > length)
throw new UnsupportedOperationException(
"message length is too large, it's limited " + length);
// 如果长度不足,则进行补全
if (msg.length() < length)
msg = addSpace(msg);
ctx.writeAndFlush(Unpooled.wrappedBuffer(msg.getBytes()));
// 进行空格补全
private String addSpace(String msg)
StringBuilder builder = new StringBuilder(msg);
for (int i = 0; i < length - msg.length(); i++)
builder.append(" ");
return builder.toString();

这里FixedLengthFrameEncoder实现了encode()方法,在该方法中,主要是将消息长度不足20的消息进行空格补全。
EchoServerHandler的作用主要是打印接收到的消息,然后发送响应给客户端:

public class EchoServerHandler extends SimpleChannelInboundHandler<String>
@Override
protected void channelRead0(ChannelHandlerContext ctx, String msg) throws Exception
System.out.println("server receives message: " + msg.trim());
ctx.writeAndFlush("hello client!");
对于客户端,其实现方式基本与服务端的使用方式类似,只是在最后进行消息发送的时候与服务端的处理方式不同。
如下是客户端EchoClient的代码:

public class EchoClient
public void connect(String host, int port) throws InterruptedException
EventLoopGroup group = new NioEventLoopGroup();
try
Bootstrap bootstrap = new Bootstrap();
bootstrap.group(group)
.channel(NioSocketChannel.class)
.option(ChannelOption.TCP_NODELAY, true)
.handler(new ChannelInitializer<SocketChannel>()
@Override
protected void initChannel(SocketChannel ch) throws Exception
// 对服务端发送的消息进行粘包和拆包处理,由于服务端发送的消息已经进行了空格补全,
// 并且长度为20,因而这里指定的长度也为20
ch.pipeline().addLast(new FixedLengthFrameDecoder(20));
// 将粘包和拆包处理得到的消息转换为字符串
ch.pipeline().addLast(new StringDecoder());
// 对客户端发送的消息进行空格补全,保证其长度为20
ch.pipeline().addLast(new FixedLengthFrameEncoder(20));
// 客户端发送消息给服务端,并且处理服务端响应的消息
ch.pipeline().addLast(new EchoClientHandler());
);
ChannelFuture future = bootstrap.connect(host, port).sync();
future.channel().closeFuture().sync();
finally
group.shutdownGracefully();
public static void main(String[] args) throws InterruptedException
new EchoClient().connect("127.0.0.1", 8080);

对于客户端而言,其消息的处理流程其实与服务端是相似的,对于入站消息,需要对其进行粘包和拆包处理,然后将其转码为字符串,对于出站消息,则需要将长度不足20的消息进行空格补全。
客户端与服务端处理的主要区别在于最后的消息处理handler不一样,也即这里的EchoClientHandler,如下是该handler的源码:

public class EchoClientHandler extends SimpleChannelInboundHandler<String>
@Override
protected void channelRead0(ChannelHandlerContext ctx, String msg) throws Exception
System.out.println("client receives message: " + msg.trim());
@Override
public void channelActive(ChannelHandlerContext ctx) throws Exception
ctx.writeAndFlush("hello server!");

这里客户端的处理主要是重写了channelActive()和channelRead0()两个方法,这两个方法的主要作用在于,channelActive()会在客户端连接上服务器时执行,
也就是说,其连上服务器之后就会往服务器发送消息。而channelRead0()主要是在服务器发送响应给客户端时执行,这里主要是打印服务器的响应消息。
对于服务端而言,前面我们我们可以看到,EchoServerHandler只重写了channelRead0()方法,这是因为服务器只需要等待客户端发送消息过来,然后在该方法中进行处理,处理完成后直接将响应发送给客户端。
DelimiterBasedFrameDecoder解码器
DelimiterBasedFrameDecoder是分隔符解码器,用户可以指定消息结束的分隔符,它可以自动完成以分隔符作为码流结束标识的消息的解码。
而对于数据的编码,也即在每个数据包添加指定分割符的部分需要用户自行进行处理,回车换行解码器实际上是一种特殊的DelimiterBasedFrameDecoder解码器。
如下是EchoServer中使用该类的代码片段,其余部分与前面的例子中的完全一致:
@Override
protected void initChannel(SocketChannel ch) throws Exception
String delimiter = "_$";
// 将delimiter设置到DelimiterBasedFrameDecoder中,经过该解码一器进行处理之后,源数据将会
// 被按照_$进行分隔,这里1024指的是分隔的最大长度,即当读取到1024个字节的数据之后,若还是未
// 读取到分隔符,则舍弃当前数据段,因为其很有可能是由于码流紊乱造成的
ch.pipeline().addLast(new DelimiterBasedFrameDecoder(1024, Unpooled.wrappedBuffer(delimiter.getBytes())));
// 将分隔之后的字节数据转换为字符串数据
ch.pipeline().addLast(new StringDecoder());
// 这是我们自定义的一个编码器,主要作用是在返回的响应数据最后添加分隔符
ch.pipeline().addLast(new DelimiterBasedFrameEncoder(delimiter));
// 最终处理数据并且返回响应的handler
ch.pipeline().addLast(new EchoServerHandler());

上面pipeline的设置中,添加的解码器主要有DelimiterBasedFrameDecoder和StringDecoder,经过这两个处理器处理之后,接收到的字节流就会被分隔,并且转换为字符串数据,最终交由EchoServerHandler处理。
这里DelimiterBasedFrameEncoder是我们自定义的编码器,其主要作用是在返回的响应数据之后添加分隔符。如下是该编码器的源码:
public class DelimiterBasedFrameEncoder extends MessageToByteEncoder<String>
private String delimiter;
public DelimiterBasedFrameEncoder(String delimiter)
this.delimiter = delimiter;
@Override
protected void encode(ChannelHandlerContext ctx, String msg, ByteBuf out)
throws Exception
// 在响应的数据后面添加分隔符
ctx.writeAndFlush(Unpooled.wrappedBuffer((msg + delimiter).getBytes()));
对于客户端而言,这里的处理方式与服务端类似,其pipeline的添加方式如下:
@Override
protected void initChannel(SocketChannel ch) throws Exception
String delimiter = "_$";
// 对服务端返回的消息通过_$进行分隔,并且每次查找的最大大小为1024字节
ch.pipeline().addLast(new DelimiterBasedFrameDecoder(1024, Unpooled.wrappedBuffer(delimiter.getBytes())));
// 将分隔之后的字节数据转换为字符串
ch.pipeline().addLast(new StringDecoder());
// 对客户端发送的数据进行编码,这里主要是在客户端发送的数据最后添加分隔符
ch.pipeline().addLast(new DelimiterBasedFrameEncoder(delimiter));
// 客户端发送数据给服务端,并且处理从服务端响应的数据
ch.pipeline().addLast(new EchoClientHandler());
这里客户端的处理方式与服务端基本一致,关于这里没展示的代码,其与示例一中的代码完全一致,这里则不予展示。
LineBasedFrameDecoder解码器
LineBasedFrameDecoder是回车换行解码器。它实际上是一种特殊的DelimiterBasedFrameDecoder解码器,在数据末尾加上特殊符号以标识边界。默认是使用换行符\\n。
而对于数据的编码,也即在每个数据包最后添加换行符的部分需要用户自行进行处理。
如下是EchoServer中使用该类的代码片段,其余部分与前面的例子中的完全一致:
@Override
protected void initChannel(SocketChannel ch) throws Exception
ch.pipeline().addLast(new LineBasedFrameDecoder(1024));
// 将分隔之后的字节数据转换为字符串数据
ch.pipeline().addLast(new StringDecoder());
// 这是我们自定义的一个编码器,主要作用是在返回的响应数据最后添加分隔符
ch.pipeline().addLast(new LineBasedFrameEncoder());
// 最终处理数据并且返回响应的handler
ch.pipeline().addLast(new EchoServerHandler());

上面pipeline的设置中,添加的解码器主要有LineBasedFrameDecoder和StringDecoder,经过这两个处理器处理之后,接收到的字节流就会被分隔,并且转换为字符串数据,最终交由EchoServerHandler处理。
这里LineBasedFrameEncoder是我们自定义的编码器,其主要作用是在返回的响应数据之后添加分隔符。如下是该编码器的源码:

public class DelimiterBasedFrameEncoder extends MessageToByteEncoder<String>
private String delimiter;
public DelimiterBasedFrameEncoder(String delimiter)
this.delimiter = delimiter;
@Override
protected void encode(ChannelHandlerContext ctx, String msg, ByteBuf out)
throws Exception
// 在响应的数据后面添加换行符\\n
ctx.writeAndFlush(Unpooled.wrappedBuffer((msg + StringUtil.LINE_FEED).getBytes()));
对于客户端而言,这里的处理方式与服务端类似,其pipeline的添加方式如下:

@Override
protected void initChannel(SocketChannel ch) throws Exception
// 对服务端返回的消息通过换行符进行分隔,并且每次查找的最大大小为1024字节
ch.pipeline().addLast(new LineBasedFrameDecoder(1024));
// 将分隔之后的字节数据转换为字符串
ch.pipeline().addLast(new StringDecoder());
// 对客户端发送的数据进行编码,这里主要是在客户端发送的数据最后添加换行符
ch.pipeline().addLast(new LineBasedFrameEncoder(delimiter));
// 客户端发送数据给服务端,并且处理从服务端响应的数据
ch.pipeline().addLast(new EchoClientHandler());
这里客户端的处理方式与服务端基本一致,关于这里没展示的代码,其与示例一中的代码完全一致,这里则不予展示。
LengthFieldBasedFrameDecoder解码器
LengthFieldBasedFrameDecoder与LengthFieldPrepender需要配合起来使用,其实本质上来讲,这两者一个是解码,一个是编码的关系。
它们处理粘拆包的主要思想是在生成的数据包中添加一个长度字段,用于记录当前数据包的长度。
LengthFieldBasedFrameDecoder会按照参数指定的包长度偏移量数据对接收到的数据进行解码,从而得到目标消息体数据;
LengthFieldPrepender则会在响应的数据前面添加指定的字节数据,这个字节数据中保存了当前消息体的整体字节数据长度。
LengthFieldBasedFrameDecoder的解码过程如下图所示:
LengthFieldPrepender的编码过程如下图所示:
这个解码器构造器需要定义5个参数:
maxFrameLength发送数据包的最大长度lengthFieldOffset长度域的偏移量。长度域位于整个数据包字节数组中的开始下标。lengthFieldLength长度域的字节数长度。lengthAdjustment长度域的偏移量矫正。如果长度域的值,除了包含有效数据域的长度外,还包含了其他域(如长度域自身)长度,那么,就需要进行矫正。矫正的值为:包长 - 长度域的值 – 长度域偏移 – 长度域长。initialBytesToStrip丢弃的起始字节数。丢弃处于此索引值前面的字节。
前面三个参数,可以用下面这张图进行说明:
矫正偏移量:假设你的长度域设置的值除了包括有效数据的长度还有其他域的长度包含在里面,那么就要设置这个值进行矫正,否则解码器拿不到有效数据。
丢弃的起始字节数:这个比较简单,就是在这个索引值前面的数据都丢弃,只要后面的数据。一般都是丢弃长度域的数据。当然如果你希望得到全部数据,那就设置为0。
这里我们以json序列化为例对LengthFieldBasedFrameDecoder和LengthFieldPrepender的使用方式进行讲解。
如下是EchoServer的源码:
public class EchoServer
public void bind(int port) throws InterruptedException
EventLoopGroup bossGroup = new NioEventLoopGroup();
EventLoopGroup workerGroup = new NioEventLoopGroup();
try
ServerBootstrap bootstrap = new ServerBootstrap();
bootstrap.group(bossGroup, workerGroup)
.channel(NioServerSocketChannel.class)
.option(ChannelOption.SO_BACKLOG, 1024)
.handler(new LoggingHandler(LogLevel.INFO))
.childHandler(new ChannelInitializer<SocketChannel>()
@Override
protected void initChannel(SocketChannel ch) throws Exception
// 这里将LengthFieldBasedFrameDecoder添加到pipeline的首位,因为其需要对接收到的数据
// 进行长度字段解码,这里也会对数据进行粘包和拆包处理
ch.pipeline().addLast(new LengthFieldBasedFrameDecoder(1024, 0, 2, 0, 2));
// LengthFieldPrepender是一个编码器,主要是在响应字节数据前面添加字节长度字段
ch.pipeline().addLast(new LengthFieldPrepender(2));
// 对经过粘包和拆包处理之后的数据进行json反序列化,从而得到User对象
ch.pipeline().addLast(new JsonDecoder());
// 对响应数据进行编码,主要是将User对象序列化为json
ch.pipeline().addLast(new JsonEncoder());
// 处理客户端的请求的数据,并且进行响应
ch.pipeline().addLast(new EchoServerHandler());
);
ChannelFuture future = bootstrap.bind(port).sync();
future.channel().closeFuture().sync();
finally
bossGroup.shutdownGracefully();
workerGroup.shutdownGracefully();
public static void main(String[] args) throws InterruptedException
new EchoServer().bind(8080);
这里EchoServer主要是在pipeline中添加了两个编码器和两个解码器,编码器主要是负责将响应的User对象序列化为json对象,然后在其字节数组前面添加一个长度字段的字节数组;
解码器主要是对接收到的数据进行长度字段的解码,然后将其反序列化为一个User对象。下面是JsonDecoder的源码:
public class JsonDecoder extends MessageToMessageDecoder<ByteBuf>
@Override
protected void decode(ChannelHandlerContext ctx, ByteBuf buf, List<Object> out)
throws Exception
byte[] bytes = new byte[buf.readableBytes()];
buf.readBytes(bytes);
User user = JSON.parseObject(new String(bytes, CharsetUtil.UTF_8), User.class);
out.add(user);
JsonDecoder首先从接收到的数据流中读取字节数组,然后将其反序列化为一个User对象。下面我们看看JsonEncoder的源码:

public class JsonEncoder extends MessageToByteEncoder<User>
@Override
protected void encode(ChannelHandlerContext ctx, User user, ByteBuf buf)
throws Exception
String json = JSON.toJSONString(user);
ctx.writeAndFlush(Unpooled.wrappedBuffer(json.getBytes()));
JsonEncoder将响应得到的User对象转换为一个json对象,然后写入响应中。对于EchoServerHandler,其主要作用就是接收客户端数据,并且进行响应,如下是其源码:
public class EchoServerHandler extends SimpleChannelInboundHandler<User>
@Override
protected void channelRead0(ChannelHandlerContext ctx, User user) throws Exception
System.out.println("receive from client: " + user);
ctx.write(user);

对于客户端,其主要逻辑与服务端的基本类似,这里主要展示其pipeline的添加方式,以及最后发送请求,并且对服务器响应进行处理的过程:
@Override
protected void initChannel(SocketChannel ch) throws Exception
ch.pipeline().addLast(new LengthFieldBasedFrameDecoder(1024, 0, 2, 0, 2));
ch.pipeline().addLast(new LengthFieldPrepender(2));
ch.pipeline().addLast(new JsonDecoder());
ch.pipeline().addLast(new JsonEncoder());
ch.pipeline().addLast(new EchoClientHandler());
public class EchoClientHandler extends SimpleChannelInboundHandler<User>
@Override
public void channelActive(ChannelHandlerContext ctx) throws Exception
ctx.write(getUser());
private User getUser()
User user = new User();
user.setAge(27);
user.setName("zhangxufeng");
return user;
@Override
protected void channelRead0(ChannelHandlerContext ctx, User user) throws Exception
System.out.println("receive message from server: " + user);
自定义粘包与拆包器
对于粘包与拆包问题,其实前面四种基本上已经能够满足大多数情形了,但是对于一些更加复杂的协议,可能有一些定制化的需求。对于这些场景,其实本质上,
我们也不需要手动从头开始写一份粘包与拆包处理器,而是通过继承LengthFieldBasedFrameDecoder和LengthFieldPrepender来实现粘包和拆包的处理。
如果用户确实需要不通过继承的方式实现自己的粘包和拆包处理器,这里可以通过实现MessageToByteEncoder和ByteToMessageDecoder来实现。
这里MessageToByteEncoder的作用是将响应数据编码为一个ByteBuf对象,而ByteToMessageDecoder则是将接收到的ByteBuf数据转换为某个对象数据。
通过实现这两个抽象类,用户就可以达到实现自定义粘包和拆包处理的目的。
如下是这两个类及其抽象方法的声明:
public abstract class ByteToMessageDecoder extends ChannelInboundHandlerAdapter
protected abstract void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out)
throws Exception;
public abstract class MessageToByteEncoder<I> extends ChannelOutboundHandlerAdapter
protected abstract void encode(ChannelHandlerContext ctx, I msg, ByteBuf out)
throws Exception;
完整实现请参考我的另外一篇文章:Netty——自定义协议通信 - 曹伟雄 - 博客园
引用:
- Netty解决粘包和拆包问题的四种方案 - charming丶的个人空间 - OSCHINA - 中文开源技术交流社区
- 深入理解Netty编解码、粘包拆包、心跳机制 - 掘金
- https://www.jianshu.com/p/d89002b57339
- Netty 中的粘包和拆包 - rickiyang - 博客园
以上是关于什么是粘包和拆包,Netty如何解决粘包拆包?的主要内容,如果未能解决你的问题,请参考以下文章