Nacos、Eureka与Zookeeper区别
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Nacos、Eureka与Zookeeper区别相关的知识,希望对你有一定的参考价值。
参考技术A 上一篇 <<< Naocs集群注意事项下一篇 >>> Nacos中AP和CP模式如何切换
注册中心 - Nacos,Eureka,Zookeeper区别
一、CAP
CAP理论,指的是在一个分布式系统中,Consistency(一致性)、Availability(可用性)、Partition Tolerance(分区容错性),不能同时成立

CAP是分布式架构中重要理论,维基百科CAP理论一文中关于C、A、P三者的定义
Consistency : Every read receives the most recent write or an error
Availability : Every request receives a (non-error) response – without the guarantee that it contains the most recent write
Partition tolerance : The system continues to operate despite an arbitrary number of messages being dropped (or delayed) by the network between nodes
- 一致性(Consistency) :所有节点在同一时间具有相同的数据
- 可用性(Availability) :保证每个请求不管成功或者失败都有响应
- 分隔容忍(Partition tolerance):系统中任意信息的丢失或失败不会影响系统的继续运作
1、一致性(Consistency):对于客户端的每次读操作,要么读到的是最新的数据,要么读取失败
换句话说,一致性是站在分布式系统的角度,对访问本系统的客户端,要么返回一个错误,要么返回绝对一致的最新数据,不难看出,强调的是数据正确
2、可用性(Availability) :任何客户端的请求都能得到响应数据,不会出现响应错误
换句话说,可用性是站在分布式系统的角度,对访问本系统的客户一定会返回数据,不会返回错误,但不保证数据最新,强调的是不出错
3、分区容忍性(Partition tolerance):由于分布式系统通过网络进行通信,网络是不可靠的。当任意数量的消息丢失或延迟到达时,系统仍会继续提供服务,不会挂掉
换句话说,分区容忍性是站在分布式系统的角度,对访问本系统的客户端的再一种承诺:我会一直运行,不管我的内部出现何种数据同步问题,强调的是不挂掉
CAP理论说一个分布式系统不可能同时满足C、A、P这三个特性
但是不要以为在所有时候都只能选择两个特性。在不存在网络失败的情况下(分布式系统正常运行时),C和A能够同时保证。只有当网络发生分区或失败时,才会在C和A之间做出选择
对于一个分布式系统而言,P是前提,必须保证,因为只要有网络交互就一定会有延迟和数据丢失,这种状况我们必须接受,必须保证系统不能挂掉。所以只剩下C、A可以选择。要么保证数据一致性(保证数据绝对正确),要么保证可用性(保证系统不出错)。
当选择了C(一致性)时,如果由于网络分区而无法保证特定信息是最新的,则系统将返回错误或超时。
当选择了A(可用性)时,系统将始终处理客户端的查询并尝试返回最新的可用的信息版本,即使由于网络分区而无法保证其是最新的
二、注册中心对比
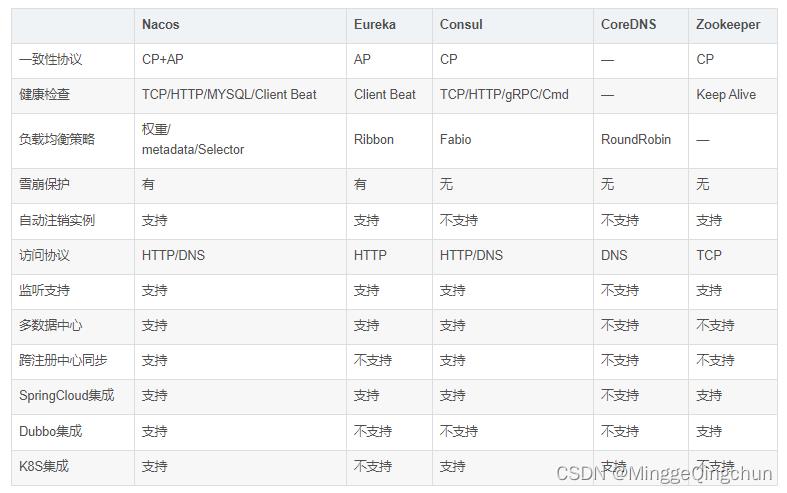
三、Nacos
Nacos从1.0版本选择Ap和CP混合形式实现注册中心,默认情况下采用AP保证服务可用性,CP形式底层采用Raft协议保证数据的一致性问题。
如果选择为Ap模式,注册服务的实例仅支持临时模式,在网络分区的的情况允许注册服务实例。
选择CP模式可以支持注册服务的实例为持久模式,在网络分区的产生了抖动情况下不允许注册服务实例
Nacos是阿里开源的,Nacos 支持基于 DNS 和基于 RPC 的服务发现。在Spring Cloud中使用Nacos,只需要先下载 Nacos 并启动 Nacos server,Nacos只需要简单的配置就可以完成服务的注册发现
Nacos除了服务的注册发现之外,还支持动态配置服务。动态配置服务可以让您以中心化、外部化和动态化的方式管理所有环境的应用配置和服务配置。动态配置消除了配置变更时重新部署应用和服务的需要,让配置管理变得更加高效和敏捷。配置中心化管理让实现无状态服务变得更简单,让服务按需弹性扩展变得更容易。
一句话概括就是Nacos = Spring Cloud注册中心 + Spring Cloud配置中心
四、Eureka
Spring Cloud Netflix 在设计 Eureka 时就紧遵AP原则(尽管现在2.0发布了,但是由于其闭源的原因 ,但是目前 Ereka 1.x 任然是比较活跃的)
Eureka Server 也可以运行多个实例来构建集群,解决单点问题,但不同于 ZooKeeper 的选举 leader 的过程,Eureka Server 采用的是Peer to Peer 对等通信。这是一种去中心化的架构,无 master/slave 之分,每一个 Peer 都是对等的。在这种架构风格中,节点通过彼此互相注册来提高可用性,每个节点需要添加一个或多个有效的 serviceUrl 指向其他节点。每个节点都可被视为其他节点的副本。
在集群环境中如果某台 Eureka Server 宕机,Eureka Client 的请求会自动切换到新的 Eureka Server 节点上,当宕机的服务器重新恢复后,Eureka 会再次将其纳入到服务器集群管理之中。当节点开始接受客户端请求时,所有的操作都会在节点间进行复制(replicate To Peer)操作,将请求复制到该 Eureka Server 当前所知的其它所有节点中。
当一个新的 Eureka Server 节点启动后,会首先尝试从邻近节点获取所有注册列表信息,并完成初始化。Eureka Server 通过 getEurekaServiceUrls() 方法获取所有的节点,并且会通过心跳契约的方式定期更新。
默认情况下,如果 Eureka Server 在一定时间内没有接收到某个服务实例的心跳(默认周期为30秒),Eureka Server 将会注销该实例(默认为90秒, eureka.instance.lease-expiration-duration-in-seconds 进行自定义配置)。
当 Eureka Server 节点在短时间内丢失过多的心跳时,那么这个节点就会进入自我保护模式。
Eureka的集群中,只要有一台Eureka还在,就能保证注册服务可用(保证可用性),只不过查到的信息可能不是最新的(不保证强一致性)。除此之外,Eureka还有一种自我保护机制,如果在15分钟内超过85%的节点都没有正常的心跳,那么Eureka就认为客户端与注册中心出现了网络故障,此时会出现以下几种情况:
1、Eureka不再从注册表中移除因为长时间没有收到心跳而过期的服务
2、Eureka仍然能够接受新服务注册和查询请求,但是不会被同步到其它节点上(即保证当前节点依然可用)
3、当网络稳定时,当前实例新注册的信息会被同步到其它节点中
五、Zookeeper
Apache Zookeeper 在设计时就紧遵CP原则,即任何时候对 Zookeeper 的访问请求能得到一致的数据结果,同时系统对网络分割具备容错性,但是 Zookeeper 不能保证每次服务请求都是可达的
从 Zookeeper 的实际应用情况来看,在使用 Zookeeper 获取服务列表时,如果此时的 Zookeeper 集群中的 Leader 宕机了,该集群就要进行 Leader 的选举,又或者 Zookeeper 集群中半数以上服务器节点不可用(例如有三个节点,如果节点一检测到节点三挂了 ,节点二也检测到节点三挂了,那这个节点才算是真的挂了),那么将无法处理该请求。所以说,Zookeeper 不能保证服务可用性。
当然,在大多数分布式环境中,尤其是涉及到数据存储的场景,数据一致性应该是首先被保证的,这也是 Zookeeper 设计紧遵CP原则的另一个原因。
但是对于服务发现来说,情况就不太一样了,针对同一个服务,即使注册中心的不同节点保存的服务提供者信息不尽相同,也并不会造成灾难性的后果。
因为对于服务消费者来说,能消费才是最重要的,消费者虽然拿到可能不正确的服务实例信息后尝试消费一下,也要胜过因为无法获取实例信息而不去消费,导致系统异常要好(淘宝的双十一,京东的618就是紧遵AP的最好参照)。
当master节点因为网络故障与其他节点失去联系时,剩余节点会重新进行leader选举。问题在于,选举leader的时间太长,30~120s,而且选举期间整个zk集群都是不可用的,这就导致在选举期间注册服务瘫痪。
在云部署环境下, 因为网络问题使得zk集群失去master节点是大概率事件,虽然服务能最终恢复,但是漫长的选举事件导致注册长期不可用是不能容忍的
以上是关于Nacos、Eureka与Zookeeper区别的主要内容,如果未能解决你的问题,请参考以下文章