oracle中group by按月分组统计
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了oracle中group by按月分组统计相关的知识,希望对你有一定的参考价值。
姓名 访问时间 进入时间 离开时间 张三 2013-02-03 15:23:22 2013-02-03 15:23:22 2013-02-03 15:33:22 李四 2013-02-04 15:23:22 2013-02-04 18:23:22 2013-02-04 18:53:22 王武 2013-02-04 15:23:22 2013-02-05 17:23:22 2013-02-05 18:23:22 张三 2013-02-04 15:23:22 2013-02-06 11:23:22 2013-02-06 14:23:22按月汇总每个人总的访问总次数和总时间(离开时间-进入时间 例如 进入时间为 2013-02-03 15:23:22 离开时间为 2013-02-03 15:33:22 则时间是33分钟 进入时间为 2013-02-06 11:23:22 离开时间为 2013-02-03 2013-02-06 14:23:22 则时间是1小时 )
姓名 访问时间 进入时间 离开时间
张三 2013-02-03 15:23:22 2013-02-03 15:23:22 2013-02-03 15:33:22
李四 2013-02-04 15:23:22 2013-02-04 18:23:22 2013-02-04 18:53:22
王武 2013-02-04 15:23:22 2013-02-05 17:23:22 2013-02-05 18:23:22
张三 2013-02-04 15:23:22 2013-02-06 11:23:22 2013-02-06 14:23:22
按月汇总每个人总的访问总次数和总时间
创建测试表
create table test(姓名 varchar2(10),
访问时间 date,
进入时间 date,
离开时间 date);
insert into test values (\'张三\',to_date(\'2013-02-03 15:23:22\',\'yyyy-mm-dd hh24:mi:ss\'),to_date(\'2013-02-03 15:23:22\',\'yyyy-mm-dd hh24:mi:ss\'),to_date(\'2013-02-03 15:33:22\',\'yyyy-mm-dd hh24:mi:ss\'));
insert into test values (\'李四\',to_date(\'2013-02-04 15:23:22\',\'yyyy-mm-dd hh24:mi:ss\'),to_date(\'2013-02-04 18:23:22\',\'yyyy-mm-dd hh24:mi:ss\'),to_date(\'2013-02-04 18:53:22\',\'yyyy-mm-dd hh24:mi:ss\'));
insert into test values (\'王武\',to_date(\'2013-02-04 15:23:22\',\'yyyy-mm-dd hh24:mi:ss\'),to_date(\'2013-02-05 17:23:22\',\'yyyy-mm-dd hh24:mi:ss\'),to_date(\'2013-02-05 18:23:22\',\'yyyy-mm-dd hh24:mi:ss\'));
insert into test values (\'张三\',to_date(\'2013-02-04 15:23:22\',\'yyyy-mm-dd hh24:mi:ss\'),to_date(\'2013-02-06 11:23:22\',\'yyyy-mm-dd hh24:mi:ss\'),to_date(\'2013-02-06 14:23:22\',\'yyyy-mm-dd hh24:mi:ss\'));
运行
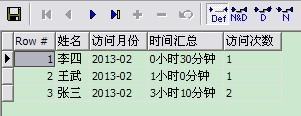
select 姓名,to_char(访问时间,\'yyyy-mm\') 访问月份,
to_char(trunc(round(sum(离开时间-进入时间)*1440)/60))||\'小时\'||to_char(round(sum((离开时间-进入时间)*1440))-trunc(round(sum(离开时间-进入时间)*1440)/60)*60)||\'分钟\' 时间汇总,
count(*) 访问次数 from test
group by 姓名,to_char(访问时间,\'yyyy-mm\');
结果
to_char(a.access_time, 'YYYY-MM') "月份",
COUNT(a.name) "访问次数",
sum((a.out_time - a.in_time) * 60 * 24) "总时间(分钟)"
from test a
GROUP BY A.NAME, to_char(a.access_time, 'YYYY-MM')
oracle中group by用法
参考技术A 1,在select 语句中可以使用group by 子句将行划分成较小的组,一旦使用分组后select操作的对象变为各个分组后的数据,使用聚组函数返回的是每一个组的汇总信息。使用having子句限制返回的结果集。group by 子句可以将查询结果分组,并返回行的汇总信息Oracle 按照group by 子句中指定的表达式的值分组查询结果。
2,在带有group by 子句的查询语句中,在select 列表中指定的列要么是group by 子句中指定的列,要么包含聚组函数 select max(sal),job emp group by job; (注意max(sal),job的job并非一定要出现,但有意义) 查询语句的select 和group by ,having 子句是聚组函数唯一出现的地方,在where 子句中不能使用聚组函数。 select deptno,sum(sal) from emp where sal>1200 group by deptno having sum(sal)>8500 order by deptno;
3,当在gropu by 子句中使用having 子句时,查询结果中只返回满足having条件的组。在一个sql语句中可以有where子句和having子句。having 与where 子句类似,均用于设置限定条件 where 子句的作用是在对查询结果进行分组前,将不符合where条件的行去掉,即在分组之前过滤数据,条件中不能包含聚合函数,使用where条件显示特定的行。
having 子句的作用是筛选满足条件的组,即在分组之后过滤数据,条件中经常包含聚合函数,使用having 条件显示特定的组,也可以使用多个分组标准进行分组。
4,使用order by排序时order by子句置于group by 之后 并且 order by 子句的排序标准不能出现在select查询之外的列。
查询每个部门的每种职位的雇员数
select deptno,job,count(*) from emp group by deptno,job
5,记住这就行了:
在使用group by 时,有一个规则需要遵守,即出现在select列表中的字段,如果没有在组函数中,那么必须出现在group by 子句中。(select中的字段不可以单独出现,必须出现在group语句中或者在组函数中。)
以上是关于oracle中group by按月分组统计的主要内容,如果未能解决你的问题,请参考以下文章