怎样删除EXCEL表重复数据,保留最新的一个
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了怎样删除EXCEL表重复数据,保留最新的一个相关的知识,希望对你有一定的参考价值。
我的EXCEL表中有两千多个数据,一家公司的信息如公司名、联系方式等,有2011年录入的还有2012年录入的,我如何已公司名称为筛选条件,删除2011年录入的信息,保留2012的。
第一,这里是测试,所以只是随便输入了一些简单的数据。用鼠标选中要去掉重复数据的范围。如下图所示。

第二,这里用的是excel自带的比较好用的方法。直接用鼠标点击数据,弹出窗口后,然后选择筛选选项。具体操作可以参考下图。

第三,把鼠标放在筛选选项,会自动弹出一个窗口,其中有自动筛选,全部显示,高级筛选。这里直接点击高级筛选。如下图。

第四,在高级筛选窗口中,选择在原有区域显示筛选结果,并且在选择不重复的记录中打钩,最后点击确定选项。如下图所示。

第五,按之前的步骤操作后,就会出现下图这样的结果。直接覆盖原来的数据。

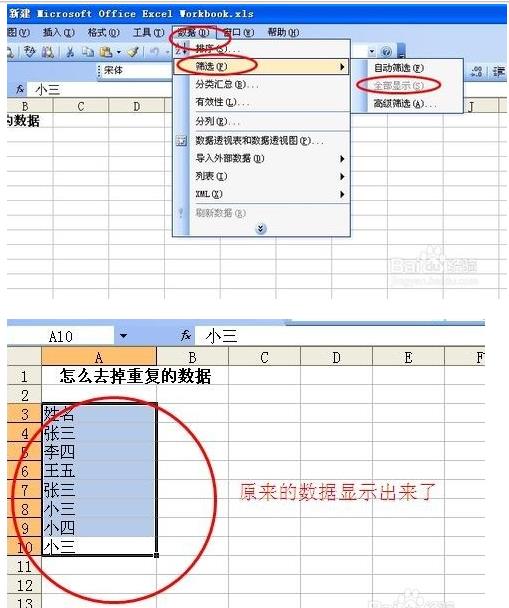
第六,假如想看之前的数据,那么可以直接点击数据按钮,然后筛选按钮,最后可以点击全部显示。
第七,假如想把更新后的数据在另外一个地方显示,可以选择将筛选结果复制到其它位置。具体如下图所示。

例如以下数据:
公司名称 录入时间 地址
A公司 2012 新甲地址
A公司 2011 甲地址
B公司 2011 乙地址
C公司 2011 丙地址
最后需要整理成这样的结果:
公司名称 录入时间 地址
A公司 2012 新甲地址
B公司 2011 乙地址
C公司 2011 丙地址
我的方法比较笨,姑且看看,呵呵。需要以下几个步骤:
1、首先是用分类汇总功能,找出所有行数据大于1的,也就是有两行记录的公司(每行都增加一行“1”的记录)分类后结果如下:
A公司 2
B公司 1
C公司 1
2、记录为1的不用考虑,直接剔除掉,然后将所有“录入时间”为“2012”的vlookup出来,或者直接排序,将录入时间为2011的删除。再加上前面步骤中找出来的总行数为1的即可。 参考技术C 假设A列为2011年的数据,C列为2012年的数据,在B2输入公式=COUNTIF(C:C,A2),下拉,选择A、B列,按B列排序,把B列大于0的对应A列的单元格数据删除本回答被提问者和网友采纳 参考技术D 用VBA代码吧,花两三分钟就弄好了
mysql删除重复数据,保留最新的那一条
因为数据库没键外键,在关联查询的时候,会碰到查询条数多余数据库实际条数,这因为关联字段在表中有重复值而导致的。
解决方案:
1、数据库脚本删除重复数据,保留最新的一条
2、对关联字段增加唯一约束
例如:
以下表,部门表的部门编号出现了重复。
首先判断是不是重复
1 select count(*) from department d 2 3 select count(*) from ( select distinct dept_code from department )
看以上查出来的数量是不是相同的,不同则就是dept_code有出现重复的
接下来删除重复值,并保留最新的记录
1 delete from department where id in ( 2 select * from ( 3 select d.id 4 from department d 5 inner join ( 6 select m.dept_code,max(m.sys_tm) max_tm FROM department m group by m.dept_code having count(1) > 1 7 ) a on a.dept_code = d.dept_code 8 where d.sys_tm <> a.max_tm 9 ) tmp 10 );
给该字段增加唯一索引
1 ALTER TABLE `department` 2 ADD UNIQUE INDEX `idex_dept_code` (`dept_code`);
以上是关于怎样删除EXCEL表重复数据,保留最新的一个的主要内容,如果未能解决你的问题,请参考以下文章