线性卷积在DSP芯片上的实现
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了线性卷积在DSP芯片上的实现相关的知识,希望对你有一定的参考价值。
《数字信号处理》要做课程设计,题目是:线性卷积在DSP芯片上的实现。
要求:给出算法原理,写出主程序。
在这两天给答案。
如果回答满意,追加100分~。
对于没有使用过DSP的初学者来说,第一个困惑就是DSP其他的嵌入式处理器究竟有什么不同,它和单片机,ARM有什么区别。事实上,DSP也是一种嵌入式处理器,它完全可以完成单片机的功能。
唯一的重要的区别在于DSP支持单时钟周期的"乘-加"运算。这几乎是所有厂家的DSP芯片的一个共有特征。几乎所有的DSP处理器的指令集中都会有一条MAC指令,这条指令可以把两个操作数从RAM中取出相乘,然后加到一个累加器中,所有这些操作都在一个时钟周期内完成。拥有这样一条指令的处理器就具备了DSP功能。
具有这条指令就称之为数字信号处理器的原因在于,所有的数字信号处理算法中最为常见的算术操作就是"乘-加"。这是因为数字信号处理中大量使用了内积,或称"点积"的运算。无论是FIR滤波,FFT,信号相关,数字混频,下变频。所有这些数字信号处理的运算经常是将输入信号与一个系数表或者与一个本地参考信号相乘然后积分(累加),这就表现为将两个向量(或称序列)进行点积,在编程上就变成将输入的采样放在一个循环buffer里,本地的系数表或参考信号也放在一个buffer里,然后使用两个指针指向这两个buffer。这样就可以在一个loop里面使用一个MAC指令将二者进行点积运算。这样的点积运算对与处理器来说是最快的,因为仅需一个始终周期就可以完成一次乘加。
了解DSP的这一特点后,当我们设计一个嵌入式系统时,首先要考虑处理器所实现的算法中是否有点积运算,即是否要经常进行两个数组的乘加,(记住数字滤波,相关等都表现为两个数组的点积)如果有的话,每秒要做多少次,这样就能够决定是否采用DSP,采用多高性能的DSP了。
浮点与定点
浮点与定点也是经常是初学者困惑的问题,在选择DSP器件的时候,是采用浮点还是采用定点,如果用定点是16位还是32位?其实这个问题和你的算法所要求的信号的动态范围有关。
定点的计算不过是把一个数据当作整数来处理,通常AD采样来的都是整数,这个数相对于真实的模拟信号有一个刻度因子,大家都知道用一个16位的AD去采样一个0到5V的信号,那么AD输出的整数除以2^16再乘以5V就是对应的电压。在定点DSP中是直接对这个16位的采样进行处理,并不将它转换成以小数表示的电压,因为定点DSP无法以足够的精度表示一个小数,它只能对整数进行计算。
而浮点DSP的优势在于它可以把这个采样得到的整数转换成小数表示的电压,并不损失精度(这个小数用科学记数法来表示),原因在于科学记数法可以表示很大的动态范围的一个信号,以IEEE754浮点数为例,
单精度浮点格式: [31] 1位符号 [30-23]8位指数 [22-00]23位小数
这样的能表示的最小的数是+-2^-149,最大的数是+-(2-2^23)*2^127.动态范围为20*log(最大的数/最小的数)=1667.6dB 这样大的动态范围使得我们在编程的时候几乎不必考虑乘法和累加的溢出,而如果使用定点处理器编程,对计算结果进行舍入和移位则是家常便饭,这在一定程度上会损失是精度。原因在于定点处理处理的信号的动态范围有限,比如16位定点DSP,可以表示整数范围为1-65536,其动态范围为20*log(65536/1)=96dB.对于32定点DSP,动态范围为20*log(2^32/1)=192dB,远小于32位ieee浮点数的1667.6dB,但是,实际上192dB对绝大多数应用所处理的信号已经足够了。
由于AD转换器的位数限制,一般输入信号的动态范围都比较小,但在DSP的信号处理中,由于点积运算会使中间节点信号的动态范围增加,所以主要考虑信号处理流程中中间结果的动态范围,以及算法对中间结果的精度要求,来选择相应的DSP。另外就是浮点的DSP更易于编程,定点DSP编程中程序员要不断调整中间结果的P,Q值,实际就是不断对中间结果进行移位调整和舍入。
DSP与RTOS
TI的CCS提供Bios,ADI的VDSP提供VDK,都是基于各自DSP的嵌入式多任务内核。DSP编程可以用单用C,也可以用汇编,或者二者结合,一般软件编译工具都提供了很好的支持。我不想在这里多说BIOS,VDK怎么用这在相应的文档里说的很详细。我想给初学者说说DSP的RTOS原理。用短短几段话说这个复杂的东西也是挑战!
其实DSP的RTOS和基于其他处理器的通用RTOS没什么大的区别,现在几乎人人皆知的uCOSii也很容易移植到DSP上来,只要把寄存器保存与恢复部分和堆栈部分改改就可以。一般在用BIOS和VDK之前,先看看操作系统原理的书比较好。uCOS那本书也不错。
BIOS和VDK其实是一个RTOS内核函数集,DSP的应用程序会和这些函数连接成一个可执行文件。其实实现一个简单的多任务内核并不复杂,首先定义好内核的各种数据结构,然后写一个scheduler函数,功能是从所有就绪任务中(通过查找就绪任务队列或就绪任务表)找出优先级最高的任务,并恢复其执行。然后在此基础上写几个用于任务间通信的函数就可以了,比如event,message box,等等。
RTOS一般采用抢先式的任务调度方式,举例说当任务A等待的资源available的时候,DSP会执行一个任务调度函数scheduler,这个函数会检查当前任务是否比任务A优先级低,如果是的话,就会把它当前挂起,然后把任务A保存在堆栈里寄存器值全部pop到DSP处理器中(这就是所谓的任务现场恢复)。接着scheduler还会把从堆栈中取出任务A挂起时的程序执行的地址,pop到PC,使任务A继续执行。这样当前任务就被任务A抢先了。
使用RTOS之后,每个任务都会有一个主函数,这个函数的起始地址就是该任务的入口。一般每个任务的主函数里有一个死循环,这个循环使该任务周期地执行,完成一部分算法模块的功能,其实这个函数跟普通函数没任何区别,类似于C语言中的main函数。一个任务创建的时候,RTOS会把这个函数入口地址压入任务的堆栈中,好象这个函数(任务)刚发生过一次中断一样。一旦这个新创建任务的优先级在就绪队列中是最高的,RTOS就会从其堆栈中弹出其入口地址开始执行。
有一个疑问是,不使用RTOS,而是简单使用一个主循环在程序中调用各个函数模块,一样可以实现软件的调度执行。那么,这种常用的方法与使用RTOS相比有什么区别呢?其实,使用主循环的方法不过是一种没有优先级的顺序执行的调度策略而已。这种方法的缺点在于,主循环中调用的各个函数是顺序执行的,那么,即使是一个无关紧要的函数(比如闪烁一个LED),只要他不主动返回,也会一直执行直到结束,这时,如果发生一个重要的事件(比如DMA buffer full 中断),就会得不到及时的响应和处理,只能等到那个闪烁LED的函数执行完毕。这样就使整个DSP处理的优先次序十分不合理。而在使用了RTOS之后,当一个重要的事件发生时,中断处理会进入RTOS,并调用scheduler,这时scheduler 会让处理这一事件的任务抢占DSP处理器(因为它的优先级高)。而哪个闪烁LED任务即使晚执行几毫秒都没任何影响。这样整个DSP的调度策略就十分合理。
RTOS要说的内容太多,我只能讲一下自己的一点体会吧
DSP与正(余)弦波
在DSP的应用中,我们经常要用到三角函数,或者合成一个正(余)弦波。这是因为我们喜欢把信号通过傅立叶变换映射到三角函数空间来理解信号的频率特性。信号处理的一些计算技巧都需要在DSP软件中进行三角函数计算。然而三角函数计算是非线性的计算,DSP并没有专门的指令来求一个数的正弦或余弦。于是我们需要用线性方法来近似求解。
一个直接的想法是用多项式拟合,这也正是大多数DSP C编译器提供正余弦库函数所采用的方法。其原理是把三角函数向函数空间1,x,x^2,x^3....上投影,从而获得一系列的系数,用这些系数就可以拟合出三角函数。比如,我们在[0,pi/2]区间上拟合sin,只需在matlab中输入以下命令:
x=0:0.05:pi/2;
p=polyfit(x,sin(x),5)
就得到5阶的多项式系数:
p =
0.00581052047605 0.00580963216172 -0.17193865685360
0.00209002716293 0.99969270087312 0.00000809543448
于是在[0,pi/2]区间上:
sin(x)= 0.00000809543448+0.99969270087312*x+ 0.00209002716293*x^2-0.17193865685360*x^3+
0.00580963216172*x^4+0.00581052047605*x^5
于是在DSP程序中,我们可以通过用乘加(MAC)指令计算这个多项式来近似求得sin(x)
当然如果用定点DSP还要把P这个多项式系数表用一定的Q值来改写成定点数。
这样的三角函数计算一般都需要几十个cycle 的开销。这对于某些场合是不能容忍的。
另一种更快的方法是借助于查表,比如,我们将[0,pi/2]分成32个区间,每个区间长度就为pi/64,在每个区间上我们使用直线段拟合sin曲线,每个区间线段起点的正弦值和线段斜率事先算好,存在RAM里,这样就需要在在RAM里存储64个
常数:
32个起点的精确的正弦值(事先算好): s[32]=0,sin(pi/64),sin(pi/32),sin(pi/16)....
32个线段的斜率: f[32]=0.049,.....
对于输入的每一个x,先根据其大小找到所在区间i,通常x用定点表示,一般取其高几位就是系数i了,然 后通过下式即可求出sin(x):
sin(x)= s[i]*f[i]
这样一般只需几个CYCLE就可以算出正弦值,如果需要更高的精度,可以将区间分得更细,当然,也就需 要更多的RAM去存储常数表。
事实上,不仅三角函数,其他的各种非线性函数都是这样近似计算的。 参考技术A DSP芯片,也称数字信号处理器, 是一种具有特殊结构的微处理器。DSP芯片的内部采用程序和数据分开的哈佛结构,具有专门的硬件乘法器,广泛采用流水线操作,提供特殊的DSP指令,可以用来快速的实现各种数字信号处理算法。
根据数字信号处理的要求,DSP芯片一般具有如下的一些主要特点:
(1) 在一个指令周期内可完成一次乘法和一次加法。
(2) 程序和数据空间分开,可以同时访问指令和数据。
(3) 片内具有快速RAM,通常可通过独立的数据总线在两块中同时访问。
(4) 具有低开销或无开销循环及跳转的硬件支持。
(5) 快速的中断处理和硬件I/O支持。
(6) 具有在单周期内操作的多个硬件地址产生器。
(7) 可以并行执行多个操作。
(8) 支持流水线操作,使取指、译码和执行等操作可以重叠执行。
与通用微处理器相比,DSP芯片的其他通用功能相对较弱些。
事实上,DSP也是一种嵌入式处理器,它完全可以完成单片机的功能。
唯一的重要的区别在于DSP支持单时钟周期的"乘-加"运算。这几乎是所有厂家的DSP芯片的一个共有特征。几乎所有的DSP处理器的指令集中都会有一条MAC指令,这条指令可以把两个操作数从RAM中取出相乘,然后加到一个累加器中,所有这些操作都在一个时钟周期内完成。拥有这样一条指令的处理器就具备了DSP功能。
具有这条指令就称之为数字信号处理器的原因在于,所有的数字信号处理算法中最为常见的算术操作就是"乘-加"。这是因为数字信号处理中大量使用了内积,或称"点积"的运算。无论是FIR滤波,FFT,信号相关,数字混频,下变频。所有这些数字信号处理的运算经常是将输入信号与一个系数表或者与一个本地参考信号相乘然后积分(累加),这就表现为将两个向量(或称序列)进行点积,在编程上就变成将输入的采样放在一个循环buffer里,本地的系数表或参考信号也放在一个buffer里,然后使用两个指针指向这两个buffer。这样就可以在一个loop里面使用一个MAC指令将二者进行点积运算。这样的点积运算对与处理器来说是最快的,因为仅需一个始终周期就可以完成一次乘加。
了解DSP的这一特点后,当我们设计一个嵌入式系统时,首先要考虑处理器所实现的算法中是否有点积运算,即是否要经常进行两个数组的乘加,(记住数字滤波,相关等都表现为两个数组的点积)如果有的话,每秒要做多少次,这样就能够决定是否采用DSP,采用多高性能的DSP了。
浮点与定点
浮点与定点也是经常是初学者困惑的问题,在选择DSP器件的时候,是采用浮点还是采用定点,如果用定点是16位还是32位?其实这个问题和你的算法所要求的信号的动态范围有关。
定点的计算不过是把一个数据当作整数来处理,通常AD采样来的都是整数,这个数相对于真实的模拟信号有一个刻度因子,大家都知道用一个16位的AD去采样一个0到5V的信号,那么AD输出的整数除以2^16再乘以5V就是对应的电压。在定点DSP中是直接对这个16位的采样进行处理,并不将它转换成以小数表示的电压,因为定点DSP无法以足够的精度表示一个小数,它只能对整数进行计算。
而浮点DSP的优势在于它可以把这个采样得到的整数转换成小数表示的电压,并不损失精度(这个小数用科学记数法来表示),原因在于科学记数法可以表示很大的动态范围的一个信号,以IEEE754浮点数为例,
单精度浮点格式: [31] 1位符号 [30-23]8位指数 [22-00]23位小数
这样的能表示的最小的数是+-2^-149,最大的数是+-(2-2^23)*2^127.动态范围为20*log(最大的数/最小的数)=1667.6dB 这样大的动态范围使得我们在编程的时候几乎不必考虑乘法和累加的溢出,而如果使用定点处理器编程,对计算结果进行舍入和移位则是家常便饭,这在一定程度上会损失是精度。原因在于定点处理处理的信号的动态范围有限,比如16位定点DSP,可以表示整数范围为1-65536,其动态范围为20*log(65536/1)=96dB.对于32定点DSP,动态范围为20*log(2^32/1)=192dB,远小于32位ieee浮点数的1667.6dB,但是,实际上192dB对绝大多数应用所处理的信号已经足够了。
由于AD转换器的位数限制,一般输入信号的动态范围都比较小,但在DSP的信号处理中,由于点积运算会使中间节点信号的动态范围增加,所以主要考虑信号处理流程中中间结果的动态范围,以及算法对中间结果的精度要求,来选择相应的DSP。另外就是浮点的DSP更易于编程,定点DSP编程中程序员要不断调整中间结果的P,Q值,实际就是不断对中间结果进行移位调整和舍入。
DSP与RTOS
TI的CCS提供BIOS,ADI的VDSP提供VDK,都是基于各自DSP的嵌入式多任务内核。DSP编程可以用单用C,也可以用汇编,或者二者结合,一般软件编译工具都提供了很好的支持。我不想在这里多说BIOS,VDK怎么用这在相应的文档里说的很详细。我想给初学者说说DSP的RTOS原理。用短短几段话说这个复杂的东西也是挑战!
其实DSP的RTOS和基于其他处理器的通用RTOS没什么大的区别,现在几乎人人皆知的uCOSii也很容易移植到DSP上来,只要把寄存器保存与恢复部分和堆栈部分改改就可以。一般在用BIOS和VDK之前,先看看操作系统原理的书比较好。uCOS那本书也不错。
BIOS和VDK其实是一个RTOS内核函数集,DSP的应用程序会和这些函数连接成一个可执行文件。其实实现一个简单的多任务内核并不复杂,首先定义好内核的各种数据结构,然后写一个scheduler函数,功能是从所有就绪任务中(通过查找就绪任务队列或就绪任务表)找出优先级最高的任务,并恢复其执行。然后在此基础上写几个用于任务间通信的函数就可以了,比如event,message box,等等。
RTOS一般采用抢先式的任务调度方式,举例说当任务A等待的资源available的时候,DSP会执行一个任务调度函数scheduler,这个函数会检查当前任务是否比任务A优先级低,如果是的话,就会把它当前挂起,然后把任务A保存在堆栈里寄存器值全部pop到DSP处理器中(这就是所谓的任务现场恢复)。接着scheduler还会把从堆栈中取出任务A挂起时的程序执行的地址,pop到PC,使任务A继续执行。这样当前任务就被任务A抢先了。
使用RTOS之后,每个任务都会有一个主函数,这个函数的起始地址就是该任务的入口。一般每个任务的主函数里有一个死循环,这个循环使该任务周期地执行,完成一部分算法模块的功能,其实这个函数跟普通函数没任何区别,类似于C语言中的main函数。一个任务创建的时候,RTOS会把这个函数入口地址压入任务的堆栈中,好象这个函数(任务)刚发生过一次中断一样。一旦这个新创建任务的优先级在就绪队列中是最高的,RTOS就会从其堆栈中弹出其入口地址开始执行。
有一个疑问是,不使用RTOS,而是简单使用一个主循环在程序中调用各个函数模块,一样可以实现软件的调度执行。那么,这种常用的方法与使用RTOS相比有什么区别呢?其实,使用主循环的方法不过是一种没有优先级的顺序执行的调度策略而已。这种方法的缺点在于,主循环中调用的各个函数是顺序执行的,那么,即使是一个无关紧要的函数(比如闪烁一个LED),只要他不主动返回,也会一直执行直到结束,这时,如果发生一个重要的事件(比如DMA buffer full 中断),就会得不到及时的响应和处理,只能等到那个闪烁LED的函数执行完毕。这样就使整个DSP处理的优先次序十分不合理。而在使用了RTOS之后,当一个重要的事件发生时,中断处理会进入RTOS,并调用scheduler,这时scheduler 会让处理这一事件的任务抢占DSP处理器(因为它的优先级高)。而哪个闪烁LED任务即使晚执行几毫秒都没任何影响。这样整个DSP的调度策略就十分合理。
RTOS要说的内容太多,我只能讲一下自己的一点体会吧
DSP与正(余)弦波
在DSP的应用中,我们经常要用到三角函数,或者合成一个正(余)弦波。这是因为我们喜欢把信号通过傅立叶变换映射到三角函数空间来理解信号的频率特性。信号处理的一些计算技巧都需要在DSP软件中进行三角函数计算。然而三角函数计算是非线性的计算,DSP并没有专门的指令来求一个数的正弦或余弦。于是我们需要用线性方法来近似求解。
一个直接的想法是用多项式拟合,这也正是大多数DSP C编译器提供正余弦库函数所采用的方法。其原理是把三角函数向函数空间1,x,x^2,x^3....上投影,从而获得一系列的系数,用这些系数就可以拟合出三角函数。比如,我们在[0,pi/2]区间上拟合sin,只需在matlab中输入以下命令:
x=0:0.05:pi/2;
p=polyfit(x,sin(x),5)
就得到5阶的多项式系数:
p =
0.00581052047605 0.00580963216172 -0.17193865685360
0.00209002716293 0.99969270087312 0.00000809543448
于是在[0,pi/2]区间上:
sin(x)= 0.00000809543448+0.99969270087312*x+ 0.00209002716293*x^2-0.17193865685360*x^3+
0.00580963216172*x^4+0.00581052047605*x^5
于是在DSP程序中,我们可以通过用乘加(MAC)指令计算这个多项式来近似求得sin(x)
当然如果用定点DSP还要把P这个多项式系数表用一定的Q值来改写成定点数。
这样的三角函数计算一般都需要几十个cycle 的开销。这对于某些场合是不能容忍的。
另一种更快的方法是借助于查表,比如,我们将[0,pi/2]分成32个区间,每个区间长度就为pi/64,在每个区间上我们使用直线段拟合sin曲线,每个区间线段起点的正弦值和线段斜率事先算好,存在RAM里,这样就需要在在RAM里存储64个
常数:
32个起点的精确的正弦值(事先算好): s[32]=0,sin(pi/64),sin(pi/32),sin(pi/16)....
32个线段的斜率: f[32]=0.049,.....
对于输入的每一个x,先根据其大小找到所在区间i,通常x用定点表示,一般取其高几位就是系数i了,然 后通过下式即可求出sin(x):
sin(x)= s[i]*f[i]
这样一般只需几个CYCLE就可以算出正弦值,如果需要更高的精度,可以将区间分得更细,当然,也就需 要更多的RAM去存储常数表。
事实上,不仅三角函数,其他的各种非线性函数都是这样近似计算的。
基于INTEL FPGA硬浮点DSP实现卷积运算

概述
卷积是一种线性运算,其本质是滑动平均思想,广泛应用于图像滤波。而随着人工智能及深度学习的发展,卷积也在神经网络中发挥重要的作用,如卷积神经网络。本参考设计主要介绍如何基于INTEL 硬浮点的DSP Block实现32位单精度浮点的卷积运算,而针对定点及低精度的浮点运算,则需要对硬浮点DSP Block进行相应的替换即可。
原理分析
设:f(x), g(x)是两个可积函数,作积分:
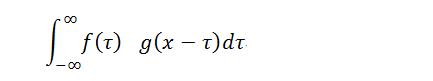
随着x的不同取值,该积分定义了一个新的函数h(x),称为函数f(x)与g(x)的卷积,记为h(x)=f(x)*g(x)。
如果卷积的变量是序列x(n)和h(n),则卷积的结果为
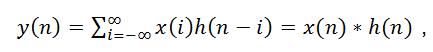
其中*表示卷积。因此两个序列的卷积,实际上就是多项式的乘法,用个例子说明其工作原理。a = [7,5,4]; b = [6,7,9];则实现a和b的卷积,就是把a和b作为一个多项式的系数,按多项式的升幂或降幂排列,即为:

因此得到a*b=[42,79,122,73,36];与Matlab运算结果一致。而二维卷积可以采用通用多项式乘积方法实现卷积运算。
基于INTEL FPGA的实现分析
如上我们确定了两个序列的卷积等同于两个多项式的乘法,因此当我们需要计算序列[a0,a1,a2, …,an-1]与[b0,b1,b2, …,bn-1]的卷积结果时,可以成立a,b两个n阶多项式,如下所示:

则[a0,a1,a2, …,an-1]与[b0,b1,b2, …,bn-1]的卷积结果即为由a*b得到的多项式的各项系数所组成的序列。令c=a*b,得到
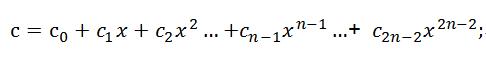
则由多项式c的各阶系数所组成的新的序列[c0,c1,c2, …,c2n-1]即为[a0,a1,a2, …,an-1]与[b0,b1,b2, …,bn-1]的卷积结果。则按照高阶多项式计算展开可得到:
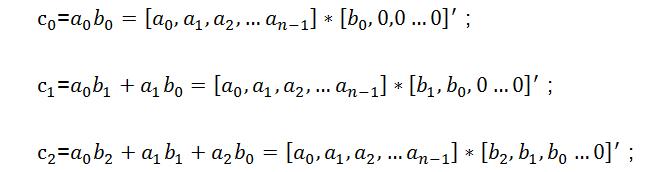
┆┆
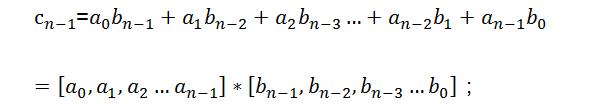
┆┆
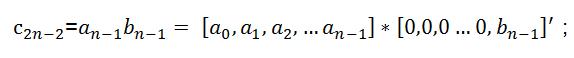
因此卷积的运算可以转化为行向量与列向量相乘的结果,即乘累加的运算结构。
Intel FPGA在Arria10DSP Block中首次支持了单精度硬浮点DSP block,是行业内第一个支持单精度DSP block,硬浮点DSP block架构如图1所示:
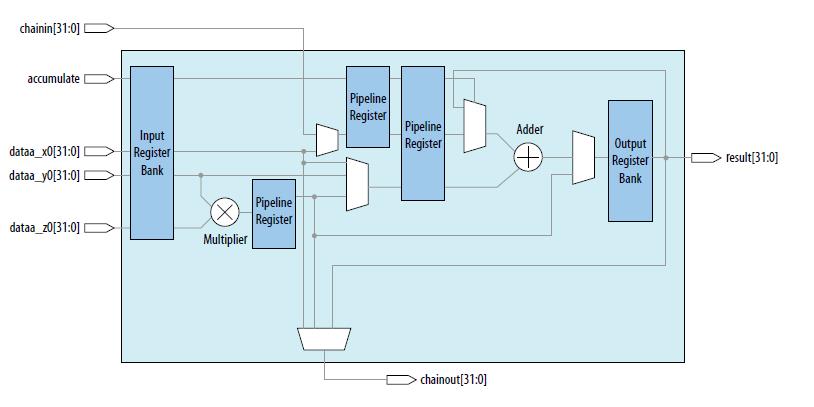 图1 硬浮点DSPblock架构
图1 硬浮点DSPblock架构
硬浮点DSP Block包含硬浮点乘法器,硬浮点加法器,支持乘累加运算,因此采用硬浮点DSPblock实现行列向量相乘是非常好的方式。下面我们针对一个实际的卷积运算,介绍如何基于INTEL硬浮点DSP block实现。假设我们需要求随机数组a=[4,8,9,11]与b=[10,5,7,13]的卷积运算结果,则根据上面的分析,保持数组a顺序不变,而数组b需根据上述分析结果,针对每一个卷积结果产生新的序列。所以整个实现包括数列重组模块和硬浮点乘法器模块及输出处理。下面是实现框图及仿真结果。
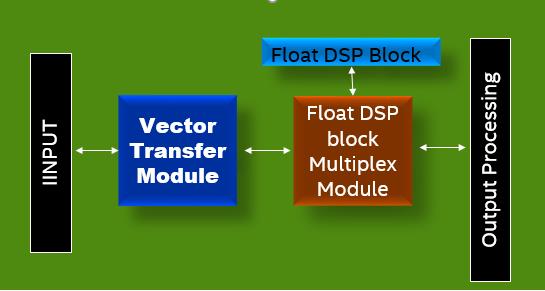
图2 实现框图
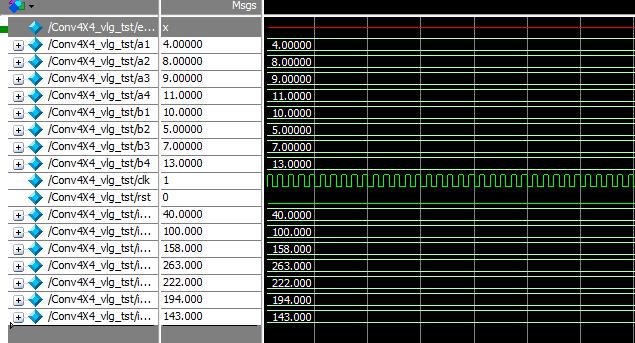
图3 Modelsim仿真结果
仿真结果与Matlab实现结果一致,并且该设计中充分考虑了FPGA并行扩展特性,对于低速率要求的设计可采用DSP Block复用的方式节约DSP block数量。
版权所有权归卿萃科技 杭州FPGA事业部,转载请注明出处
作者:杭州卿萃科技ALIFPGA
原文地址:杭州卿萃科技FPGA极客空间 微信公众号

扫描二维码关注杭州卿萃科技FPGA极客空间
以上是关于线性卷积在DSP芯片上的实现的主要内容,如果未能解决你的问题,请参考以下文章