爬取大众点评评论犯法吗
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬取大众点评评论犯法吗相关的知识,希望对你有一定的参考价值。
参考技术A 爬取大众点评评论犯法。“大众点评”等标识属于知名服务特有名称,爬取大众点评评论属于擅自使用知名服务特有名称的不正当竞争行为。爬取作为一种计算机技术就决定了它的中立性,因此爬取本身在法律上并不被禁止,但是利用爬取技术获取数据这一行为是具有违法甚至是犯罪的风险的。所以爬取大众点评评论犯法。大众点评封ip,还字体加密?我直呼,就这啊!
像旧巷子里的猫,我很自由,但没有归宿

假如csdn有创作激励该多好,那样就可以天天"水"博客了!
哈喽,大家好,上期给大家伙分享了一期微博数据的爬取
Python爬取微博评论数据,竟被反爬封号了!
小夜斗花了将近5天滴时间肝出了一期与大众点评斗智斗勇的一期,其实也没那么久,思路其实挺清晰滴,就其中一些小的细节处理挺费劲的!详细源码大家可以看文末自行获取!
“Python破解大众点评字体加密”
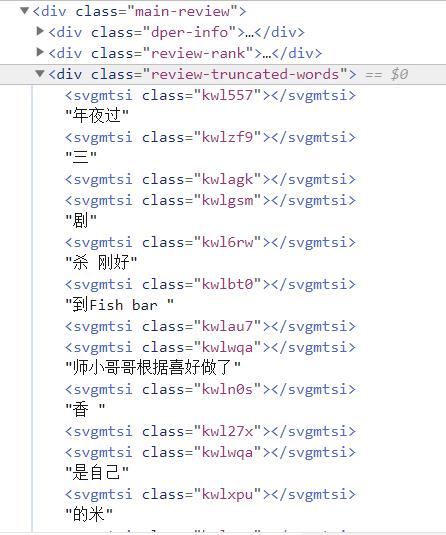
这期核心反爬措施是: 大众点评这个网址的字体信息专门保存在了一个文字字典当中,需要你根据字体的位置从这个文字字典中获取!
一:获取网页html文本信息与映射列表

上图为小夜斗将要抓取滴一个评论信息,它在网页源码中显示如下:有些文字信息并没有直接加载出来,需要我们将其破解出来!
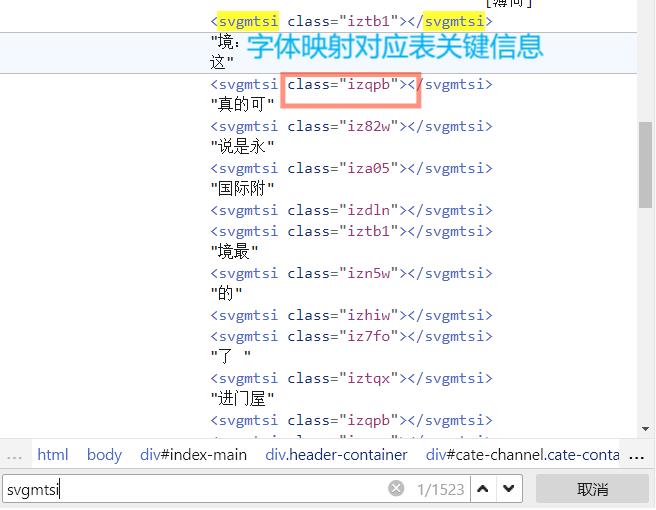
让我们写一段爬取网页html源码滴代码, url为评论区点击更多后显示的网页地址!(请注意大众点评对请求头的反爬机制非常严重,如果没有评论信息可能就是请求头的问题!)

这段代码我们需要做的是获取每一个字体对应的隐射类属性以及整个html网页源代码,具体代码如下所示:
#coding:utf8
import requests
import re
from lxml import etree
# TODO: 评论区的信息并没有加载到网页当中(请求头问题)
# 请求头
headers =
'Connection': 'keep-alive',
'Host': 'www.dianping.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36',
'Cookie': '_lxsdk_cuid=173ec1d725e80-001e5367555543-7e647c65-1fa400-173ec1d725fc8; _lxsdk=173ec1d725e80-001e5367555543-7e647c65-1fa400-173ec1d725fc8; _hc.v=9a0b663c-e5a8-7e01-077a-b8d4d7220afa.1597394220; s_ViewType=10; fspop=test; dper=7c9cd1b645ff07fe1fd65310a52d0eca184842b7256f2ef6b5bcb5de6f1d50d57f591dac67305a8997d64b4f32f280b3bb2f74d58210d10a0fcc57a335a1c1618e36e6a24b0e7784c40ef3a2583a5b8c7a65df07c94c25578fa6e7223abeec06; ua=dpuser_5191363077; ctu=d2a46ed772193566de2cd33b3ff8ea407fbae2e64a575314195403e2ec7f168a; cy=2; cye=beijing; ll=7fd06e815b796be3df069dec7836c3df; _lx_utm=utm_source%3Dwww.sogou%26utm_medium%3Dorganic; Hm_lvt_602b80cf8079ae6591966cc70a3940e7=1612071553,1612071565,1612071610,1612092249; dplet=e77caddcb23d0ee50d83ede34e65a5da; Hm_lpvt_602b80cf8079ae6591966cc70a3940e7=1612102455; _lxsdk_s=17758c69b55-16e-a09-efe%7C%7C173'
# 网址
url = 'http://www.dianping.com/shop/H9FNPpCqj1Tu98oD/review_all'
# 发起请求
r = requests.get(url=url, headers=headers)
# 如果状态码为200显示正常
if r.status_code == 200:
print("访问成功")
text = r.text.encode("gbk", "ignore").decode("gbk", "ignore") # 解决报错双重严格限制
print(text)
# 转换为xpath对象
tree = etree.HTML(text)
# 保存所有字体类隐射属性
class_list = []
# 字体映射列表列表属性
svgmtsi_list = tree.xpath(r'//div[@class="main-review"]/div[@class="review-truncated-words"]/svgmtsi/@class')
print(len(svgmtsi_list))
for svgmtsi in svgmtsi_list:
class_list.append(svgmtsi)
print(class_list)
# 保存网页源码
# with open('网页源代码.html', 'w', encoding='utf8') as f:
# f.write(text)
else:
print("被反爬了!小夜斗赶紧跑路!")
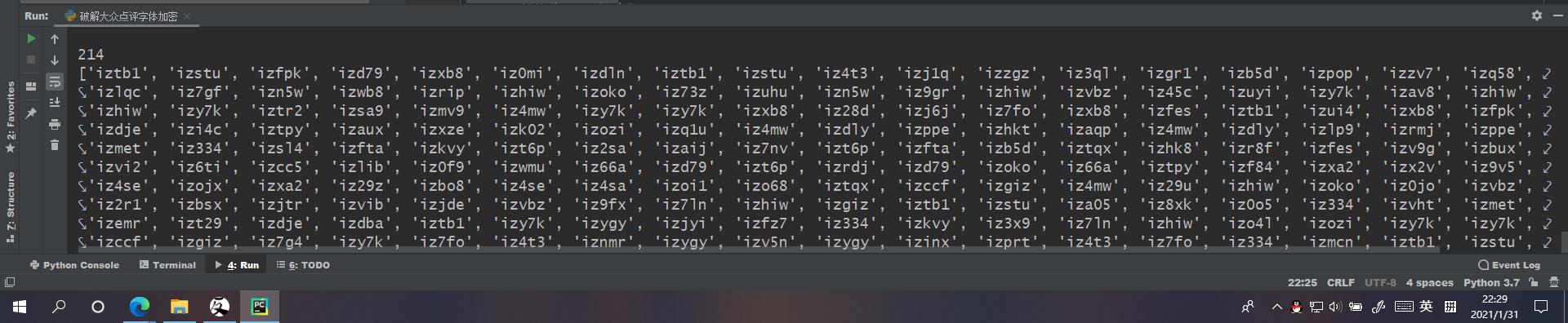
成功获取到评论区的html源码以及字体映射的类属性,看了一下(源码内部是有文本信息的)
二:找到存放字体信息滴css文件
要找到隐射关系,首先咋们得获取到css文件,获取其字体信息
代码如下:
#coding:utf8
import requests
import re
from lxml import etree
# TODO: 评论区的信息并没有加载到网页当中(请求头问题)
# 请求头
headers =
'Connection': 'keep-alive',
'Host': 'www.dianping.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36',
'Cookie': '_lxsdk_cuid=173ec1d725e80-001e5367555543-7e647c65-1fa400-173ec1d725fc8; _lxsdk=173ec1d725e80-001e5367555543-7e647c65-1fa400-173ec1d725fc8; _hc.v=9a0b663c-e5a8-7e01-077a-b8d4d7220afa.1597394220; s_ViewType=10; fspop=test; dper=7c9cd1b645ff07fe1fd65310a52d0eca184842b7256f2ef6b5bcb5de6f1d50d57f591dac67305a8997d64b4f32f280b3bb2f74d58210d10a0fcc57a335a1c1618e36e6a24b0e7784c40ef3a2583a5b8c7a65df07c94c25578fa6e7223abeec06; ua=dpuser_5191363077; ctu=d2a46ed772193566de2cd33b3ff8ea407fbae2e64a575314195403e2ec7f168a; cy=2; cye=beijing; ll=7fd06e815b796be3df069dec7836c3df; _lx_utm=utm_source%3Dwww.sogou%26utm_medium%3Dorganic; Hm_lvt_602b80cf8079ae6591966cc70a3940e7=1612071553,1612071565,1612071610,1612092249; dplet=e77caddcb23d0ee50d83ede34e65a5da; Hm_lpvt_602b80cf8079ae6591966cc70a3940e7=1612102455; _lxsdk_s=17758c69b55-16e-a09-efe%7C%7C173'
headers2 =
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36',
# 网址
url = 'http://www.dianping.com/shop/H9FNPpCqj1Tu98oD/review_all'
# 发起请求
r = requests.get(url=url, headers=headers)
# 如果状态码为200显示正常
if r.status_code == 200:
print("访问成功")
text = r.text.encode("gbk", "ignore").decode("gbk", "ignore")
css_url = re.search('<link rel="stylesheet" type="text/css" href="(//s3plus.meituan.*?)"', text)[1]
# 拼接css_rul
total_css_url = 'http:' + css_url
print(total_css_url)
# TODO: 404 r1,换个请求头
r1 = requests.get(url=total_css_url, headers=headers2)
print(r1.status_code)
text1 = r1.text.encode("gbk", "ignore").decode("gbk", "ignore") # 解决报错双重严格限制
# 保存css文件
print("我进来了保存了!")
with open('css字体映射.css', 'w', encoding='utf8') as f:
f.write(text1)
# 保存css文件
else:
print("被反爬了!小夜斗赶紧跑路!")
pycharm中css文件弄了很久格式化不了,就转到java滴ideal中显示,结果如下图所示,每个字体的信息都保存在这个css文件中!

二:找到字体css样式中滴url链接
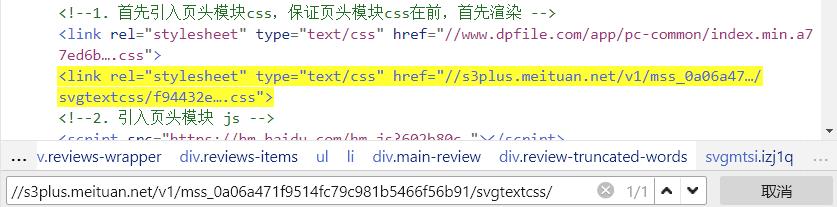
字体css中对应者下了图中url, 通过一种映射关系能够将其找到!
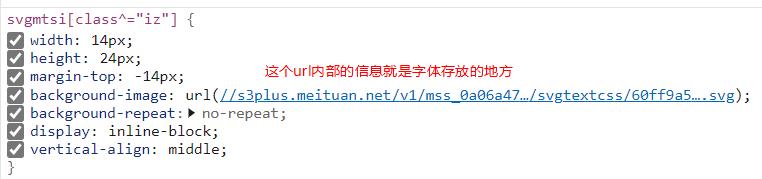
将url复制到网页中显示的内容如下所示:

写一个正则匹配出字体样式中的url链接,代码如下所示:

#coding:utf8
import requests
import re
from lxml import etree
# TODO: 评论区的信息并没有加载到网页当中(请求头问题)
# 请求头
headers =
'Connection': 'keep-alive',
'Host': 'www.dianping.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36',
'Cookie': '_lxsdk_cuid=173ec1d725e80-001e5367555543-7e647c65-1fa400-173ec1d725fc8; _lxsdk=173ec1d725e80-001e5367555543-7e647c65-1fa400-173ec1d725fc8; _hc.v=9a0b663c-e5a8-7e01-077a-b8d4d7220afa.1597394220; s_ViewType=10; fspop=test; dper=7c9cd1b645ff07fe1fd65310a52d0eca184842b7256f2ef6b5bcb5de6f1d50d57f591dac67305a8997d64b4f32f280b3bb2f74d58210d10a0fcc57a335a1c1618e36e6a24b0e7784c40ef3a2583a5b8c7a65df07c94c25578fa6e7223abeec06; ua=dpuser_5191363077; ctu=d2a46ed772193566de2cd33b3ff8ea407fbae2e64a575314195403e2ec7f168a; cy=2; cye=beijing; ll=7fd06e815b796be3df069dec7836c3df; _lx_utm=utm_source%3Dwww.sogou%26utm_medium%3Dorganic; Hm_lvt_602b80cf8079ae6591966cc70a3940e7=1612071553,1612071565,1612071610,1612092249; dplet=e77caddcb23d0ee50d83ede34e65a5da; Hm_lpvt_602b80cf8079ae6591966cc70a3940e7=1612102455; _lxsdk_s=17758c69b55-16e-a09-efe%7C%7C173'
headers2 =
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36',
# 网址
url = 'http://www.dianping.com/shop/H9FNPpCqj1Tu98oD/review_all'
# 发起请求
r = requests.get(url=url, headers=headers)
# 如果状态码为200显示正常
if r.status_code == 200:
print("访问成功")
text = r.text.encode("gbk", "ignore").decode("gbk", "ignore") # 解决报错双重严格限制
# 获取存放映射关系css链接
css_url = re.search('<link rel="stylesheet" type="text/css" href="(//s3plus.meituan.*?)"', text)[1]
# 拼接css_rul
total_css_url = 'http:' + css_url
print(total_css_url)
# TODO: 404 r1,换个请求头
r1 = requests.get(url=total_css_url, headers=headers2)
print(r1.status_code)
text1 = r1.text.encode("gbk", "ignore").decode("gbk", "ignore") # 解决报错双重严格限制
'''
svgmtsi[
class ^="iz"]
width: 14
px;
height: 24
px;
margin - top: -14
px;
background - image: url( // s3plus.meituan.net / v1 / mss_0a06a47… / svgtextcss / 60
ff9a5….svg);
background - repeat: no - repeat;
display: inline - block;
vertical - align: middle;
'''
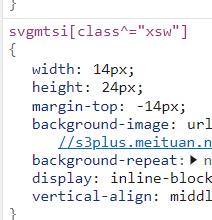
# svgmtsi[class^="iz"]width: 14px;height: 24px;margin-top: -14px;background-image: url(//s3plus.meituan.net/v1/mss_0a06a471f9514fc79c981b5466f56b91/svgtextcss/60ff9a50fd0d7753c8ebc0178004f283.svg)
# \\:转译符号
svg_url = re.findall(r'svgmtsi\\[class\\^="iz"\\].*?background-image: url\\((.*?)\\)', text1)
# print(svg_url)
# 加一个http
total_svg_url = 'http:' + svg_url[0]
print(total_svg_url)
else:
print("被反爬了!小夜斗赶紧跑路!")
获取到字体映射字典后我们可以查看其网页源代码,每一行文字都有其对应的属性y,这个属性是我们找字体位置所在行数的关键信息,我们可以看到每一行这个属性是升序的!
ps:
ps: 大众点评滴网址好像每天都在变,上面这个代码运行的话需要改一个参数,今天小夜斗在看这个网址的时候已经是svg_rul, 注意class里面的参数改变了,大家自己也可以查一下自己网址对应的class参数,大众点评还是挺狡猾滴,顺便提一下,cookie参数也要是全部评论网页滴那个cookie,大众点评每个网址cookie参数也不同····你得把最新的cookie给弄到自己的pycharm代码请求头上去!
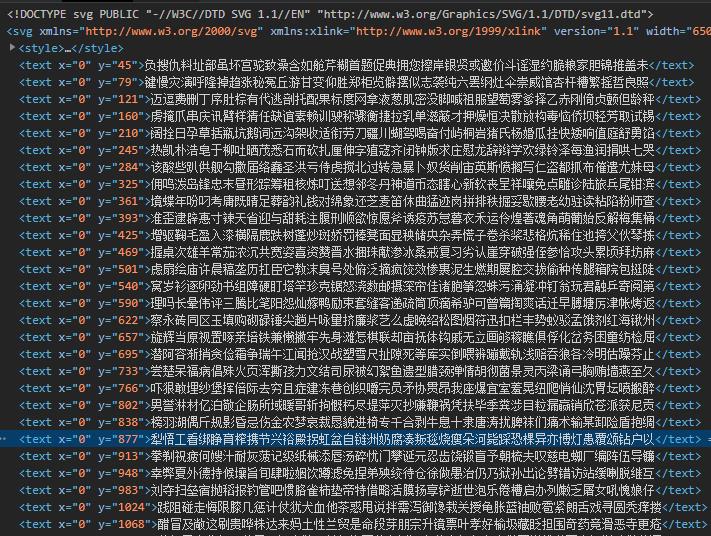
让我们先来找一个单个的子,如下图所示:“跨”
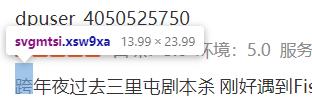
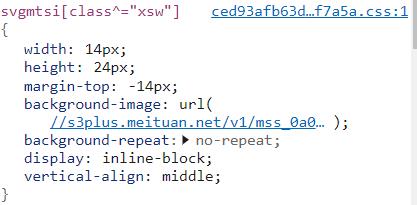

这个文字有效信息为(负号加绝对值后):宽14像素、所在行数高度最少为2332px(即要找到第一个比2332大的行高(y属性的值)即为该字体所在的行),252px代表这个的x值,x/宽可计算出字体的位置!
从零开始数,第18个位置(看y=2355这一行)就是“跨”这个字:

下面让小夜斗写个代码把这些文本数据爬取下来吧:
#coding:utf8
import requests
import re
from lxml import etree
import random
import parsel
ip_list = [
'http': 'http://8.135.103.42:80',
'http': 'http://112.80.248.75:80',
'http': 'http://117.185.17.145:80',
'http': 'http://140.207.229.170:80',
'http': 'http://113.214.13.1:1080'
]
# TODO: 评论区的信息并没有加载到网页当中(请求头问题)
# 每一个网页中的cookie都是不同滴
# 请求头
headers =
'Connection': 'keep-alive',
'Host': 'www.dianping.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36',
'Cookie': 'Cookie: _lxsdk_cuid=173ec1d725e80-001e5367555543-7e647c65-1fa400-173ec1d725fc8; _lxsdk=173ec1d725e80-001e5367555543-7e647c65-1fa400-173ec1d725fc8; _hc.v=9a0b663c-e5a8-7e01-077a-b8d4d7220afa.1597394220; s_ViewType=10; fspop=test; ua=dpuser_5191363077; ctu=d2a46ed772193566de2cd33b3ff8ea407fbae2e64a575314195403e2ec7f168a; cy=2; cye=beijing; cityid=1409; default_ab=shopreviewlist%3AA%3A1; _lx_utm=utm_source%3Dwww.sogou%26utm_medium%3Dorganic; Hm_lvt_602b80cf8079ae6591966cc70a3940e7=1612158059,1612158139,1612166936,1612327052; thirdtoken=db6b0a0e-c710-4b3f-a083-b9fed37ad4fd; dper=7c9cd1b645ff07fe1fd65310a52d0eca3f820f2c408bac5cbe1065d16321ba289d73446448580d71587a5ef790a7f2171b96ef8e556a5adbae82a31a5ce5d975815bfa8720f6cad4c9ebca38ab510dfc842471b9d4044afbb67beed0a2748fe3; ll=7fd06e815b796be3df069dec7836c3df; ctu=e8d18ba96a5973c4241e98ea92e6ef18f2b6806cefea83baee63e0dc52d6474b79afc8e7246462cc70d0c6c9c0b01d74; dplet=186d217716bb58d41809c4132e4b1188; Hm_lpvt_602b80cf8079ae6591966cc70a3940e7=1612327415; _lxsdk_s=177662e6072-ce-65b-a68%7C%7C212'
headers2 =
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36',
headers3 =
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
# 网址
url = 'http://www.dianping.com/shop/H9FNPpCqj1Tu98oD/review_all'
# 发起请求
r = requests.get(url=url, headers=headers, proxies=ip_list.pop(random.randint(0, len(ip_list)-1)))
# 如果状态码为200显示正常
if r.status_code == 200:
print("访问成功")
text = r.text.encode("gbk", "ignore").decode("gbk", "ignore") # 解决报错双重严格限制
print(text)
# 获取存放映射关系css链接
css_url = re.search('<link rel="stylesheet" type="text/css" href="(//s3plus.meituan.*?)"', text)[1]
# 拼接css_rul
total_css_url = 'http:' + css_url
print(total_css_url)
# TODO: 404 r1,换个请求头
r1 = requests.get(url=total_css_url, headers=headers2)
print(r1.status_code)
text1 = r1.text.encode("gbk", "ignore").decode("gbk", "ignore") # 解决报错双重严格限制
# 保存css文件
# \\:转译符号
svg_url = re.findall(r'svgmtsi\\[class\\^="xsw"\\].*?background-image: url\\((.*?)\\)', text1)
# print(svg_url)
# 加一个http
total_svg_url = 'http:' + svg_url[0]
print(total_svg_url)
# 获取所有的文本信息
r2 = requests.get(url=total_svg_url, headers=headers3)
text2 = r2.text.encode("gbk", "ignore").decode("gbk", "ignore")
select = parsel.Selector(text2)
# 找到所有的text标签
content_list = select.css('text')
# print(content_list)
# 新建一个空字典
y_text_dict =
for content in content_list:
# 获取文本
# print(content.css("text::text").get())
line_text = content.css("text::text").get()
# 获取y属性
# print(content.css("text::attr(y)").get())
line_y = content.css("text::attr(y)").get()
# 保存到字典当中(高度y当作建,内容文本当作值)
y_text_dict[line_y] = line_text
print(y_text_dict)
else:
print("被反爬了!小夜斗赶紧跑路!")
结果如下图所示:
这个代码小夜斗新添加了ip代理池(其实就是随便复制粘贴了几个能用的代理放到列表里面,然后随机取出其中一个,如果真滴访问量大的小伙伴不建议和小夜斗一样这么做哈!)然后在将其保存到字典中来!

以上,我们就拿到了我们想要拿到滴css文件、映射文字的字典信息!
三:字体映射关系找到字体所在位置

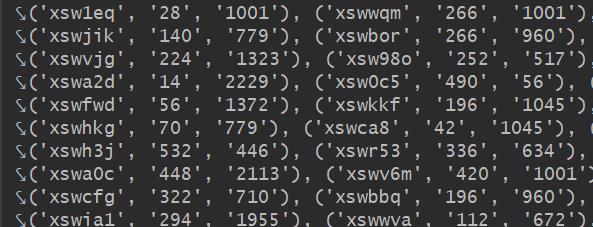
首先还得先拿到字体的信息(字体大小width但这个大多是个定值、背景高度y、背景横轴x),从上图中可以看出直接从css文件中拿就行,直接上代码!
# 获取svg字体信息
def svg_character(name_class_list, y_text_dict):
# 拿到这个类名对应的字体的高度
character_list = []
for name_class in name_class_list:
try:
y = back_dict[name_class][1]
# print(f'y:y')
# 拿到这个类名对应的字体的x轴
x = back_dict[name_class][0]
except:
print('error')
# print(f'x:x')
# 找对应的行数
# 找对应的行数
for index in y_text_dict.keys():
# 第一个比y大的行数
# print(index)
if int(index) > int(y):
# 计算x的位置, 14为字体的大小
position = int(int(x) / 14)
# print(position)
# 从index这一行获取这个字体信息
find_it = y_text_dict[index][position]
# print(y_text_dict[index])
# print(find_it, end="->")
character_list.append(find_it)
# 找到后跳出
break
# print(character_list)
return character_list
# 正则匹配类名、x坐标、y坐标
background_name_list = re.findall(r'\\.(.*?)background:-(.*?).0px -(.*?)\\.0px;', text1)
print(f'background_name_list: background_name_list')
大众点评可真行,网页上同一段评论加载下来滴页面竟然三个都不一样!牛的牛的!简直不要太混乱了吧!
页面一:

页面二:

页面三:

问题不大,经过小夜斗一番瞎操作最后哈哈成功了,来先上图!丝毫不变的给大众点评上了一课,就这就这?大快人心!
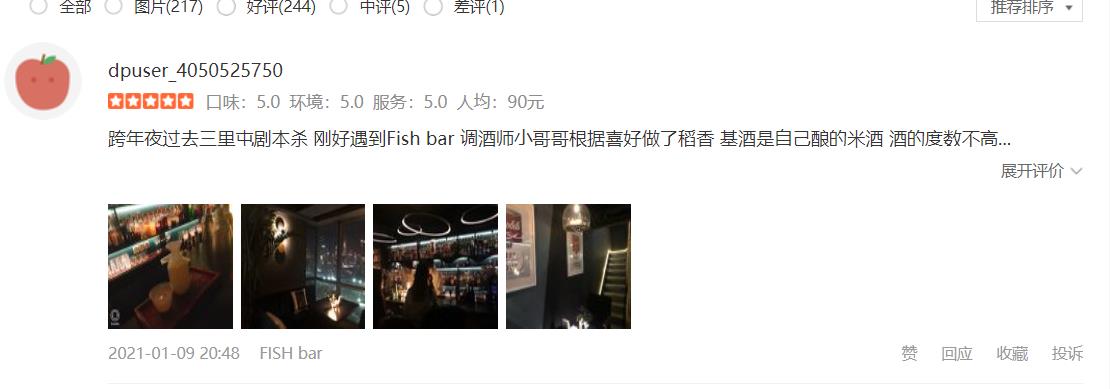
列表里面的内容就是小夜斗爬下来的内容!

这是原评论,大家可以仔细对比一下哈!

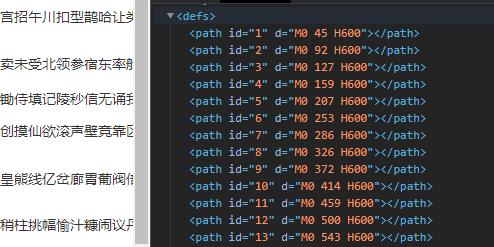
哦对了,小夜斗发现大众点评有两种svg格式的字体反爬,每天都是换着来的!遇到那种textlength属性的,那个y值就是<path标签里面那个d属性里面被包着的那个数值,就是那个45、92等等!问题不大!文本还是那个文本!
两种映射字体文本获取,代码如下:
# 映射文本获取
def mapping_text(flag):
# 请求链接
url = css_info()[0]
print(url)
# 返回文本
text2 = post_request(url)
# 第一种字体格式
if flag == '2':
select = parsel.Selector(text2)
# 找到所有的text标签
content_list = select.css('text')
# 存放信息滴字典
y_text_dict =
for content in content_list:
# 获取文本
# print(content.css("text::text").get())
line_text = content.css("text::text").get()
# 获取y属性
# print(content.css("text::attr(y)").get())
line_y = content.css("text::attr(y)").get()
# 保存到字典当中(高度y当作建,内容文本当作值)
y_text_dict[line_y] = line_text
return y_text_dict
# 第二种svg格式
if flag == '1':
select = parsel.Selector(text2)
# 找到所有的path标签
path_list = select.css('path')
print("第二种svg格式")
# print(path_list)
y_list = []
for path in path_list:
# 获取高度
y = path.css("path::attr(d)").get().split(' ')[1]
y_list.append(y)
line_text_list = []
content_list = select.css('textPath')
for content in content_list:
# 获取文本
line_text = content.css("textPath::text").get()
line_text_list.append(line_text)
# 存放信息滴字典
y_text_dict =
for k, v in zip(y_list, line_text_list):
y_text_dict[k] = v
return y_text_dict
最后最后,因为我只爬取了一页的评论就是14条,给大家伙看看成果!评论都保存在了txt文本当中了!
要实现多页爬取很简单,只要将url拼接一下即可
下面是第三页的url:形式例如p2、p3这样子滴,小夜斗出于好奇想攻克这个大众点评,完整评论信息就不爬取了!
http://www.dianping.com/shop/H9FNPpCqj1Tu98oD/review_all/p3
注意事项:大众点评对ip的访问很严格,小夜斗自己弄了3个ip,还有自己的请求头有两个,cookie信息一定要是当天登录进去滴,而且必须保证是你要抓取评论的那一页;然后那个css文件background的class类属性每天都会改变,经过小夜斗这几天的观察,字典映射文件就两种方式,大致方法都一样破解,只不过两种svg文件的y值放置的位置不一样罢了!
哦对了,如果用小夜斗源码的同学记得自己更新一下ip,三个ip不一定都能用,其中好像就下面这个能用!大家可以自己建立一个ip代理
‘http’: ‘http://113.214.13.1:1080’
然后精简版小夜斗待会儿会分享到自己的公众号,还没关注滴小伙伴快来滴滴呀,源码后台回复“006大众点评”即可获得!

请持续关注夜斗小神社,爬虫路上不迷路!
python逆向爬取网易云评论进行情感分析
- 在这个星球上,你很重要,请珍惜你的珍贵! ~~~夜斗小神社

以上是关于爬取大众点评评论犯法吗的主要内容,如果未能解决你的问题,请参考以下文章