WPS excel可以只保留数字,把文字都删了么
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了WPS excel可以只保留数字,把文字都删了么相关的知识,希望对你有一定的参考价值。
只想在表格里保留数字,把文字都要删除。坐等答案,

可以的。先排序,非数字的和数字的就分离开来了,然后直接选中非文字的后删除就可以了。如果要保留原数字的排列顺序,可以在排序前增加一个辅助列,保存原排列的序号。
第一步:增加一个辅助列,写入序号。如图:

第二步:选中数据项(以数据项为关键字进行排序),点击排序。如图:
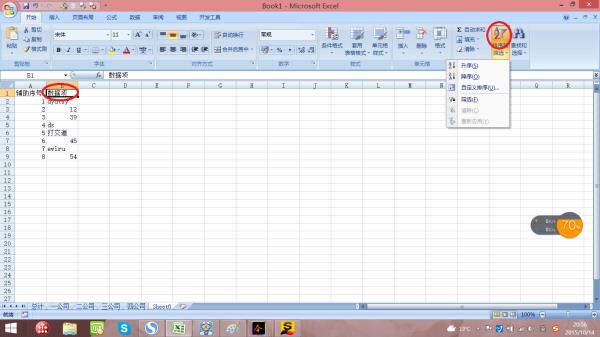
第三步:选中非数字的记录,删除。如图:
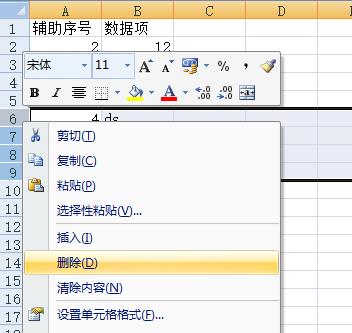
第四步:选中辅助序号,再排序。恢复数据项原来的排列顺序。结果如图:
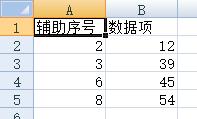
以WPS2019为例,
WPS excel可以只保留数字,把文字都删了么
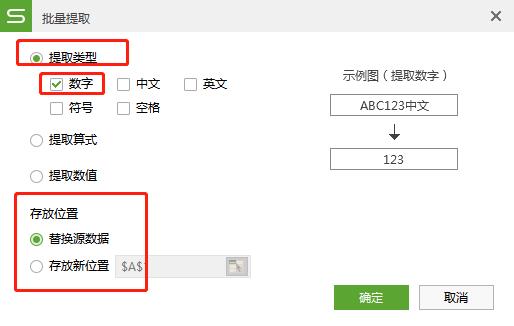
可直接在文档助手选项卡下,单元格处理,选择保留内容
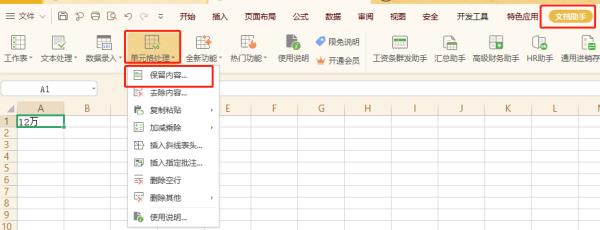
选择需要保留的内容类型,选择是替换原始数据还是存放在新位置
- 官方电话官方服务
- 官方网站
1、通常情况下,可使用正则表达式方式,在相应的软件中完成删除功能;
2、基于你的数据呈高度的相似性,且文字排列方式有规律(如:均以“<”“>”引用文字)、有限度的可枚举性,建议直接使用wps表格中自带的“替换”功能,可快速完成:
a、选中此列,用"Ctrl"+"H"键,调出“替换”对话框;
b、在“查找内容”中输入:<长度>
在“替换为”中保持空白(不输入任何字符,包括不输入空格)
点击“全部替换”钮;
c、参考b步骤,逐个枚举查找内容,并执行“全部替换”动作即可
注:在b步骤中,输入的字符内容包含“<”、“>”符号
WPS会员睿享办公,一对一VIP专业服务,详情:http://vip.wps.cn/?from=qy 参考技术C Ctrl+H
查找
<*>
替换为中不填
全部替换即可。本回答被提问者采纳 参考技术D 按CTRL+H,
查找框中输入<*>
然后点全部替换
Python基础之字符编码
引子
通过上一节讲的二进制的知识,大家已经知道计算机只认识二进制,生活中的数字要想让计算机理解就必须转换成二进制。十进制到二进制的转换只能解决计算机理解数字的问题,那么文字要怎么让计算机理解呢?
于是我们就选择了一种曲线救国的方式,既然数字可以转换成十进制,我们只要想办法把文字转换成数字,这样文字不就可以表示成二进制了么?

可是文字应该怎么转换成数字呢?就是强制转换
我们自己强行约定了一个表,把文字和数字对应上,这张表就相当于翻译,我们可以拿着一个数字来对比对应表找到相应的文字,反之亦然。
ASCII码
可以先让学生看图片,然后再介绍ascii码
假如我们就已经有这么一张表了
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言。它是现今最通用的单字节编码系统,并等同于国际标准ISO/IEC 646。
由于计算机是美国人发明的,因此,最早只有127个字母被编码到计算机里,也就是大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码,比如大写字母 A的编码是65,小写字母 z的编码是122。后128个称为扩展ASCII码。
那现在我们就知道了上面的字母符号和数字对应的表是早就存在的。那么根据现在有的一些十进制,我们就可以转换成二进制的编码串。
比如
一个空格对应的数字是0 翻译成二进制就是0(注意字符‘0‘和整数0是不同的)
一个对勾√对应的数字是251 翻译成二进制就是11111011
提问:假如我们要打印两个空格一个对勾 写作二进制就应该是 0011111011, 但是问题来了,我们怎么知道从哪儿到哪儿是一个字符呢?
论断句的重要性与必要性:
上次在网上看到个新闻,讲是个小偷在上海被捕时高喊道:“我一定要当上海贼王!”
正是由于这些字符串长的长,短的短,写在一起让我们难以分清每一个字符的起止位置,所以聪明的人类就想出了一个解决办法,既然一共就这255个字符,那最长的也不过是11111111八位,不如我们就把所有的二进制都转换成8位的,不足的用0来替换。
这样一来,刚刚的两个空格一个对勾就写作000000000000000011111011,读取的时候只要每次读8个字符就能知道每个字符的二进制值啦。
在这里,每一位0或者1所占的空间单位为bit(比特),这是计算机中最小的表示单位
每8个bit组成一个字节,这是计算机中最小的存储单位(毕竟你是没有办法存储半个字符的)orz~
要不要举例子说单位?就像我们形容长度会有厘米、分米、米之分,在计算机里也有自己的计量数据大小的单位
人民币的例子:给了你好多钱,假如没有万-十万
bit 位,计算机中最小的表示单位
8bit = 1bytes 字节,最小的存储单位,1bytes缩写为1B
1KB=1024B
1MB=1024KB
1GB=1024MB
1TB=1024GB
1PB=1024TB
1EB=1024PB
1ZB=1024EB
1YB=1024ZB
1BB=1024YB
提问:学完ascii码,作为一个英文程序员来说,基本圆满了。但是作为一个中国程序员,你是不是觉得少了点儿什么?(再给学生看一下ascii码表)
GBK和GB2312
显然,对于我们来说能在计算机中显示中文字符是至关重要的,然而刚学习的ASCII表里连一个偏旁部首也没有。所以我们还需要一张关于中文和数字对应的关系表。之前我们已经看到了,一个字节只能最多表示256个字符,要处理中文显然一个字节是不够的,所以我们需要采用两个字节来表示,而且还不能和ASCII编码冲突,所以,中国制定了GB2312编码,用来把中文编进去。
你可以想得到的是,全世界有上百种语言,日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里,
各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。
Unicode
因此,Unicode应运而生。Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。
Unicode标准也在不断发展,但最常用的是用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要4个字节)。现代操作系统和大多数编程语言都直接支持Unicode。
现在,捋一捋ASCII编码和Unicode编码的区别:
ASCII编码是1个字节,而Unicode编码通常是2个字节。
字母A用ASCII编码是十进制的65,二进制的01000001;
字符0用ASCII编码是十进制的48,二进制的00110000;
汉字“中”已经超出了ASCII编码的范围,用Unicode编码是十进制的20013,二进制的01001110 00101101。
你可以猜测,如果把ASCII编码的A用Unicode编码,只需要在前面补0就可以,因此,A的Unicode编码是00000000 01000001。
新的问题又出现了:如果统一成Unicode编码,乱码问题从此消失了。但是,如果你写的文本基本上全部是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。
UTF-8
所以,本着节约的精神,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间:
| 字符 | ASCII | Unicode | UTF-8 |
|---|---|---|---|
| A | 01000001 | 00000000 01000001 | 01000001 |
| 中 | x | 01001110 00101101 | 11100100 10111000 10101101 |
从上面的表格还可以发现,UTF-8编码有一个额外的好处,就是ASCII编码实际上可以被看成是UTF-8编码的一部分,所以,大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作。
搞清楚了ASCII、Unicode和UTF-8的关系,我们就可以总结一下现在计算机系统通用的字符编码工作方式:
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件。
文件存取编码转换图

常用编码介绍一览表
| 编码 | 制定时间 | 作用 | 所占字节数 |
|---|---|---|---|
| ASCII | 1967年 | 表示英语及西欧语言 | 8bit/1bytes |
| GB2312 | 1980年 | 国家简体中文字符集,兼容ASCII | 2bytes |
| Unicode | 1991年 | 国际标准组织统一标准字符集 | 2bytes |
| GBK | 1995年 | GB2312的扩展字符集,支持繁体字,兼容GB2312 | 2bytes |
| UTF-8 | 1992年 | 不定长编码 | 1-3bytes |
以上是关于WPS excel可以只保留数字,把文字都删了么的主要内容,如果未能解决你的问题,请参考以下文章