区间估计 Interval Estimation
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了区间估计 Interval Estimation相关的知识,希望对你有一定的参考价值。
参考技术A 前面已经讲到点估计值是一个样本统计值,我们用这个值来近似的估计总体的某个参数。由于样本统计值本身是一个随机变量,不同的样本集中的统计值会有差别,因此在使用点估计进行总体参数估计的时候,不可能完全的准确。我们可以在点估计值的基础上附加一个误差限 Margin of error 构造一个总体均值的区间估计,使得我们可以了解点估计值与总体参数的近似程度。区间估计 = 点估计值 ± 误差限
通常情况下总体的方差同均值一样都是未知的,但在有些总体中由于具备长期的观察,可以认为总体的方差是已知的。
在 抽样及其分布 中我们讲到当抽样样本集包含的元素的数量 n 足够大的时候,无论总体是否服从正态分布,不同抽样样本集中得到的样本集的均值 x̄ 都服从均值为总体均值 μ,方差为 σ x̄ = σ / n 1/2 的正态分布,其中 σ 为总体的均方差。在 描述统计 中根据切比雪夫定理和经验法则,对于对称分布的总体来说 95% 的样本点会落在总体均值 μ ± 1.96σ 的范围内。相应的对于 x̄ 这个随机变量来说,95% 的抽样的均值都会落在 μ ± 1.96σ x̄ 这个范围内。
在此基础上,如果我们将误差限设置为 ± 1.96σ x̄ 来构造区间估计 x̄ ± 1.96σ x̄ ,由于 μ ± 1.96σ x̄ 这个区间内可以容纳 95% 的 x̄ 的取值,在此基础上可以知道以这个区间内的任意 x̄ 为中心的 ± 1.96σ x̄ 的区间会都包含总体的均值 μ,或者说我们 95% 的确信总体的均值落在这个区间内。更为通俗的解释是,如果被抽样的总体服从正态分布,我们通过抽样得到了 100 个 x̄,在它们的基础上构造了 100 个 x̄ ± 1.96σ x̄ 的区间,那么我们可以完全相信,其中有 95 个区间包含总体的均值 μ。当总体不服从正态分布时,如果抽样中包含的样本数量足够大,依然可以很精确的满足这个条件。
在此称我们以 95% 的置信水平 confidence level 构造了这个 95% 的置信区间,这里 95%为置信系数,常用 1 - α 表示。之所以这样定义可以参见 假设检验 ,并且在下文中可以看到为了便于定义和查表使用,我们会基于 z α/2 给出区间估计的定义,这个数值为对应右尾面积 upper tail area 为 α/2 的点的位置,也即随机变量的取值落在这个点之外的概率为 α/2。置信水平越高,置信系数越大,区间估计的区间跨度也越大,也即误差限越大。并且,从上述计算公式可知,当为了满足一定的置信水平而得到的误差限过大时,可以通过增加抽样元素的数量 n 来缩小这个误差限。
更一般地,我们将总体的 σ 已知的样本均值的置信区间的构造形式定义如下:
前面已经提到,在绝大多数情况下,我们想要研究的总体的方差都是未知的,在这个情况下,我们就需要采用抽样得到的样本集来同时估计 μ 和 σ,在这里我们采用样本标准误差 s 来估计总体的标准差 σ,在此基础上由于误差限和区间估计都将基于 s 得到,我们称 σ 未知情况下的样本均值的分布形态称为 t 分布,或者根据其早期研究者 William Sealy Gosset 的笔名 Student 命名为 Student 分布。对于 t 分布来说,如果被抽样的总体服从正态分布,则其数学表达最为严谨,但当总体不服从正态分布时其在很多情况下也适用。
t 分布的一个重要特征是它需要定义一个自然数表示的自由度 degrees of freedom,并且随着自由度的增加,t 分布与正态分布的区别越来越小,注意从下图中可以看出 t 分布的均值为 0。对应同样的 α 值,自由度越大,最终构造的误差限越小。
为了区分 t 分布,我们用 t α/2 来代替 z α/2 来表示概率密度函数图像中右尾面积为 α/2 的点的位置。
在构造区间估计时,我们用抽样得到的标准误差 s 来估计总体的标准差,至此总体方差未知的区间估计的一般定义为:
由于对于任意样本集都有 Σ(x i - x̄) = 0,因此在计算标准误差 s 时,分子中 Σ(x i - x̄) 2 这一项中有 n - 1 个独立的参数,所以对应这个 t 分布的自由度为 n - 1。
从上面的计算可以看出,之所以要区分 σ 已知和未知两种情形,是在于当 σ 已知时,对于指定的置信系数 1- α,其误差限 z α/2 σ / n 1/2 对于不同的样本集是固定的。而当 σ 未知时,由于涉及到不同样本集的 s 的计算,因此误差限对于不同的样本集是不同的,此时就需要充分考虑到自由度的影响。
这一部分有很多相关讨论和均值类似,当 np ≥ 5 且 n(1 - p) ≥ 5 时这个二项分布可以近似用正态分布做计算。且由于 p 是未知的,所以需要标准误差来近似总体的误差,即采用 p̄ 来计算 σ p̄ 。
我写这个笔记是为了系统的复习概率论中的一些概念,阅读的是 Statistics for Business and Economics, 12th Edition 英文原版,这是一本非常经典的参考书,毫无保留的满分推荐。尽管书名暗示了是在商业和经济学中的统计学,但根本的统计学知识是不变量,并且和很多优秀的原版书一样,作者时刻注意用实例来讲解统计学概念,基本上每一个新的概念的定义都建立在日常生活的实例的基础上,在此基础上还保留了精美的排版和精心设计的插图,十分便于理解。
HeadPose Estimation头部姿态估计头部朝向(Android)
HeadPose Estimation头部姿态估计头部朝向(Android)
目录
HeadPose Estimation头部姿态估计头部朝向(Android)
0.前言
本篇,将介绍一种基于深度学习的头部姿态估计模型FSA-Net。鄙人已经复现论文的结果,并对FSA-Net进行了轻量化,以便在移动端可以跑起来;目前Android Demo已经集成人脸检测和头部朝向模型,在普通手机可实时检测(30ms左右),CPU支持多线程处理,GPU支持OpenCL加速处理,先看一下效果哈:
- Android Demo APP体检: https://download.csdn.net/download/guyuealian/85452952
- Android Demo源码:HeadPose Estimation头部姿态估计头部朝向
【尊重原创,转载请注明出处】:HeadPose Estimation头部姿态估计头部朝向(Android)_pan_jinquan的博客-CSDN博客
| CPU-4线程 | GPU |
 |  |
Android Demo支持的特性主要如下:
- 支持人脸检测:已经集成了轻量化的人脸检测,在普通手机只需要15ms左右,持CPU多线程处理,GPU支持OpenCL加速处理
- 支持头部姿态估计:已经集成了轻量化的头部姿态估计,在普通手机只需要7ms左右,持CPU多线程处理,GPU支持OpenCL加速处理
- 支持多人头部姿态估计
- Demo支持图片,视频,摄像头等多种方式输入数据
- 整个过程在普通手机可实时检测,30ms左右
1.HeadPose
头部姿态估计(Head Pose Estimation ),也称头部朝向估计,主要是获得脸部朝向的角度信息,即欧拉角(pitch,yaw,roll)表示。
头部姿态估计方法很多,主要可以分为两大类
(1)基于PNP的头部姿态估计方法
使用透视变换可以完成2D到3D的转换,可以简单的想象为将照片上的人脸图像按照一定的角度进行多点拉扯形成3D图像,然后根据角度来判断姿态。使用的方法原理为使用2D平面上人脸的特征点和3D空间内对应的坐标点,按照求解pnp问题的思路。找到一个映射关系,从而估计头部的姿态。
经典的 Head Pose Estimation 算法的步骤一般为:
- 2D人脸关键点检测;
- 3D人脸模型匹配;
- 求解3D点和对应2D点的转换关系;
- 根据旋转矩阵求解欧拉角。
基于PNP的头部姿态估计是比较传统的算法,其效果比较依赖人脸关键点检测,实际测试误差还是比较大。
可参考资料:基于3D通用模型的头部姿态估计_一半糊涂、的博客-CSDN博客_头部姿态估计
(2)基于深度学习的方法
基于深度学习的方法,把脸部朝向的角度信息,即欧拉角(pitch,yaw,roll)当作一个多任务的回归模型(也可以转为分类)。其模型输入一张RGB人脸图像,输出三个值,代表头部朝向的欧拉角,(pitch,yaw,roll)。相比传统的头部姿态估计算法,该方法不依赖于人脸关键点,精度更高效果更好。
比如论文《Fine-Grained Head Pose Estimation Without Keypoints》就是这么简单粗暴:
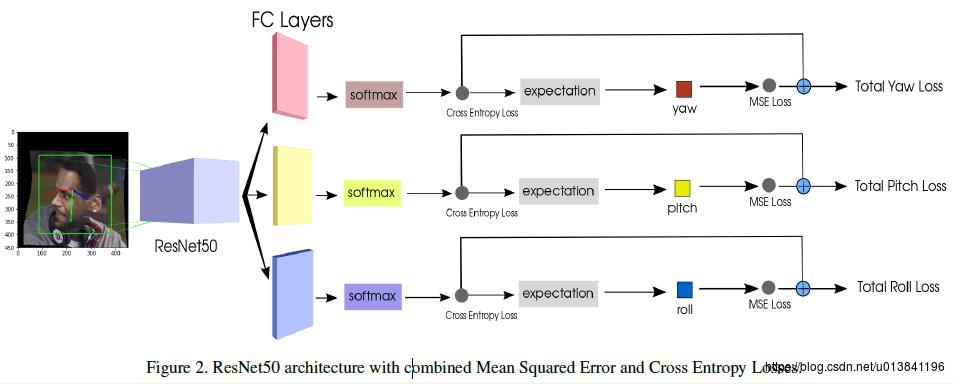
论文地址:https://arxiv.org/abs/1710.00925v2
代码链接:https://github.com/natanielruiz/deep-head-pose
当然,还有FSA-Net,本博客就是在FSA-Net的基础上进行优化
参考资料:FSA-Net学习笔记_南风不竞:的博客-CSDN博客
2.pitch、yaw、roll三个角的区别
欧拉角(pitch,yaw,roll)遵循三维空间右手笛卡尔坐标原则:
蓝色的代表偏航角,绿色的代表俯仰角,红色的代表滚转角

| 欧拉角 | 说明 | 图示 |
| pitch | 俯仰,将物体绕X轴旋转(localRotationX),即点头 上负下正 |  |
| yaw | 航向,将物体绕Y轴旋转(localRotationY),即摇头 左正右负 |  |
| roll | 横滚,将物体绕Z轴旋转(localRotationZ), 即转头(歪头)左负右正 |  |
3.头部姿态估计评价指标
头部姿态估计主要有两种评价准则
(1)平均绝对误差(MAE)
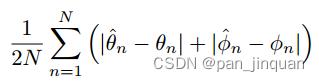
(2)平均精度
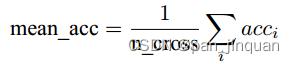
4.头部姿态估计数据
| 数据集 | 说明 |
| AFLW2000 | |
| BIWI |
|
5.FSA-Net介绍
FSA-Net 是2019年CVPR中的一篇文章,下面是FSA-NET模型架构图:
首先,输入的图片经过两条流(two Stream)。两条流在3个stage各自提取一个特征图。相同stage提取出的特征图经过fusion module(图中的绿色框)。
原文:fusion module 首先将每个stage的两个feature map,通过element-wise multiplication得到combined feature map。然后通过c 1x1 的卷积将特征图变成c个channel。最后,用平均池化将特征图变成 w*h,最终,我们得到k个stage的特征图Uk .如上图的 U1-Uk.
得到了K个大小为  特征图后,聚合模块的任务就是将其聚合为一个更小的更representative的特征图,具体来说就是将特征图精简为
特征图后,聚合模块的任务就是将其聚合为一个更小的更representative的特征图,具体来说就是将特征图精简为 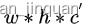 。已有的一些方法如capsule 和NetVLAD没有关注空间之间的相对信息。所以在进入特征聚合模块前,先进行空间聚合(spatial grouping)。
。已有的一些方法如capsule 和NetVLAD没有关注空间之间的相对信息。所以在进入特征聚合模块前,先进行空间聚合(spatial grouping)。
6. 头部姿态估计
目前Android Demo已经集成人脸检测和头部朝向模型,支持以下功能:
- 支持人脸检测:已经集成了轻量化的人脸检测,在普通手机只需要15ms左右,持CPU多线程处理,GPU支持OpenCL加速处理
- 支持头部姿态估计:已经集成了轻量化的头部姿态估计,在普通手机只需要7ms左右,持CPU多线程处理,GPU支持OpenCL加速处理
- 支持多人头部姿态估计
- Demo支持图片,视频,摄像头等多种方式输入数据
- 整个过程在普通手机可实时检测,30ms左右

算法核心代码,都采用C++实现,这是JNI部分,也是接口的核心代码:
package com.cv.tnn.model;
import android.graphics.Bitmap;
public class Detector
static
System.loadLibrary("tnn_wrapper");
/***
* 初始化关键点检测模型
* @param face_model: 人脸检测模型(不含后缀名)
* @param head_model: 头部朝向模型(不含后缀名)
* @param root:模型文件的根目录,放在assets文件夹下
* @param model_type:模型类型
* @param num_thread:开启线程数
* @param useGPU:关键点的置信度,小于值的坐标会置-1
*/
public static native void init(String face_model,String head_model, String root, int model_type, int num_thread, boolean useGPU);
/***
* 检测关键点
* @param bitmap 图像(bitmap),ARGB_8888格式
* @param score_thresh:置信度阈值
* @param iou_thresh: IOU阈值
* @param dst_bitmap图像(bitmap),头部姿态估计可视化效果图
* @return
*/
public static native FrameInfo[] detect(Bitmap bitmap, float score_thresh, float iou_thresh,Bitmap dst_bitmap);
Android源码的头部朝向坐标绘制,我是使用的OpenCV绘制实现的,然后把绘制好Bitmap图像通过JNI映射到上层,并进行显示,核心显示代码如下:
/***
* 绘制yaw,pitch,roll坐标轴(左手坐标系)
* @param imgBRG 输入必须是BGR格式的图像
* @param pitch红色X
* @param yaw 绿色Y
* @param roll 蓝色Z
* @param center 坐标原始点
* @param vis
* @param size
*/
void draw_yaw_pitch_roll_in_left_axis(cv::Mat &imgBRG, float pitch, float yaw, float roll,
cv::Point center, int size, int thickness, bool vis)
float cx = center.x;
float cy = center.y;
char text[200];
sprintf(text, "(pitch,yaw,roll)=(%3.1f,%3.1f,%3.1f)", pitch, yaw, roll);
pitch = pitch * PI / 180;
yaw = -yaw * PI / 180;
roll = roll * PI / 180;
// X-Axis pointing to right. drawn in red
float x1 = size * (cos(yaw) * cos(roll)) + cx;
float y1 = size * (cos(pitch) * sin(roll) + cos(roll) * sin(pitch) * sin(yaw)) + cy;
cv::Scalar color_yaw_x(0, 0, 255); //BGR;
// Y-Axis | drawn in green
float x2 = size * (-cos(yaw) * sin(roll)) + cx;
float y2 = size * (cos(pitch) * cos(roll) - sin(pitch) * sin(yaw) * sin(roll)) + cy;
cv::Scalar color_pitch_y(0, 255, 0);
// Z-Axis (out of the screen) drawn in blue
float x3 = size * (sin(yaw)) + cx;
float y3 = size * (-cos(yaw) * sin(pitch)) + cy;
cv::Scalar color_roll_z(255, 0, 0);
float tipLength = 0.2;
cv::arrowedLine(imgBRG, cv::Point(int(cx), int(cy)), cv::Point(int(x1), int(y1)), color_yaw_x,
thickness,
tipLength);
cv::arrowedLine(imgBRG, cv::Point(int(cx), int(cy)), cv::Point(int(x2), int(y2)), color_pitch_y,
thickness,
tipLength);
cv::arrowedLine(imgBRG, cv::Point(int(cx), int(cy)), cv::Point(int(x3), int(y3)), color_roll_z,
thickness,
tipLength);
if (vis)
cv::putText(imgBRG,
text,
cv::Point(cx, cy),
cv::FONT_HERSHEY_COMPLEX,
0.5,
(0, 0, 255));
一些Android测试测试效果:https://panjinquan.blog.csdn.net/article/details/124943419
| Android效果图 | CPU-4线程 | GPU |
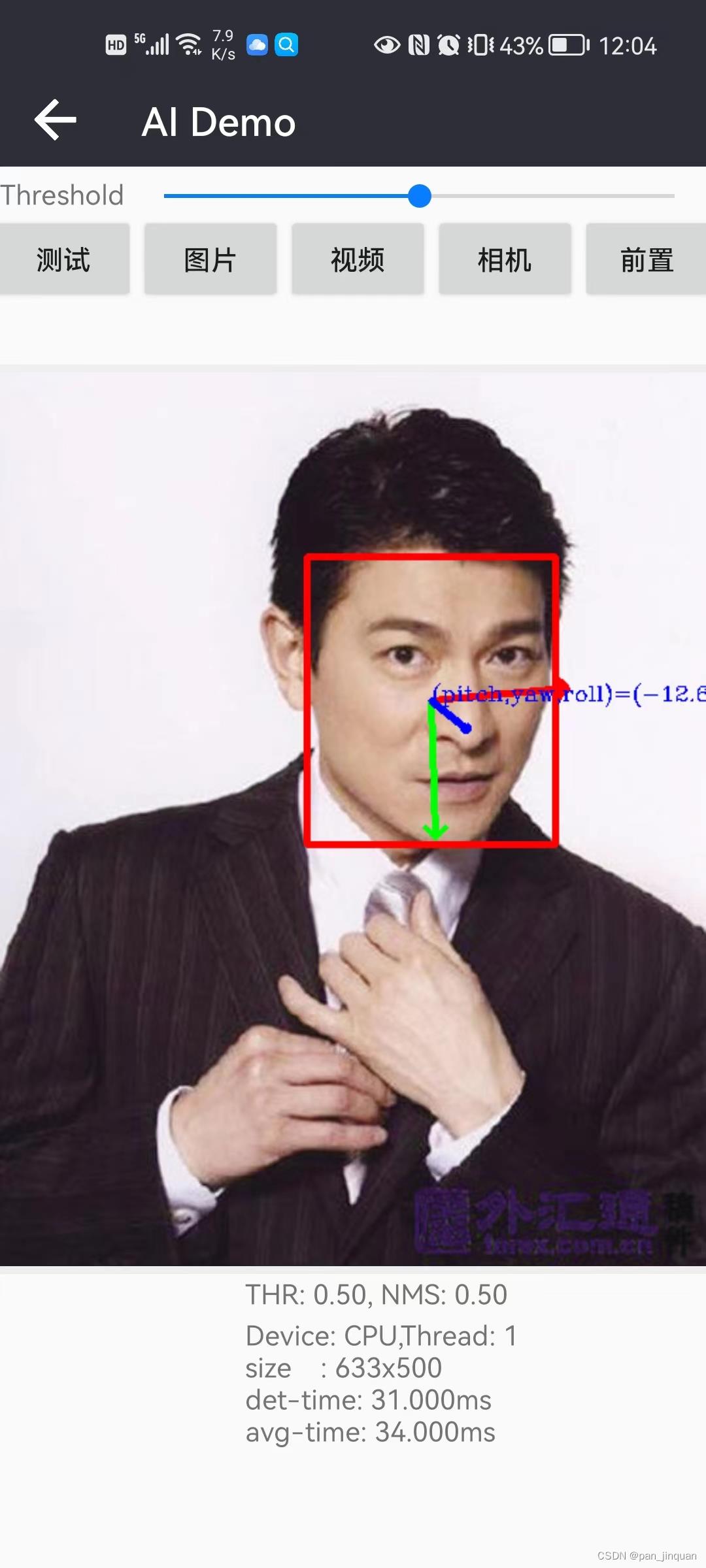 | | |
一些图片测试效果:
 | 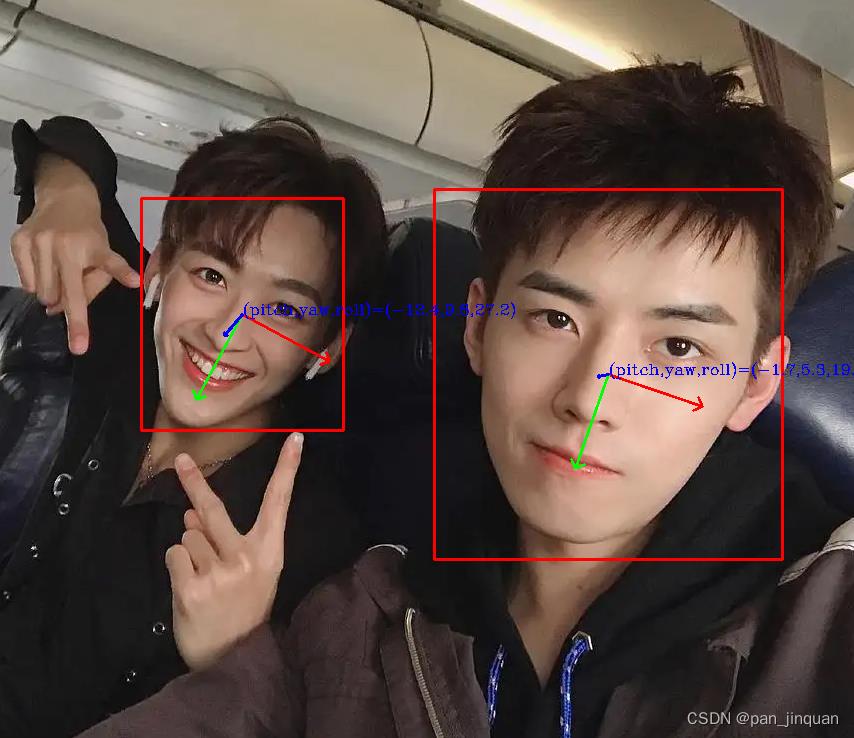 |
 | 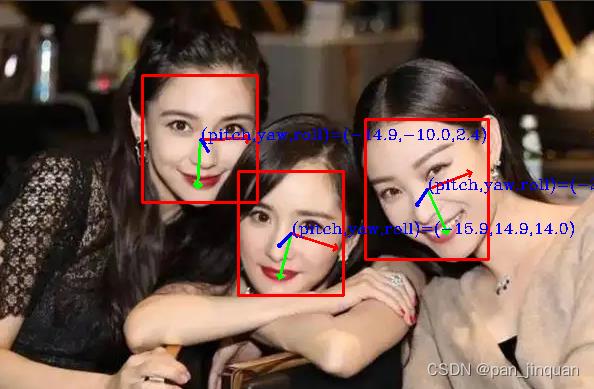 |
7. 头部姿态估计Android源码下载
- Android Demo APP体检: https://download.csdn.net/download/guyuealian/85452952
- Android Demo源码:HeadPose Estimation头部姿态估计头部朝向
以上是关于区间估计 Interval Estimation的主要内容,如果未能解决你的问题,请参考以下文章
Python 数值区间处理 - interval 库的快速入门