python中删除列表中的重复内容
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python中删除列表中的重复内容相关的知识,希望对你有一定的参考价值。
题主你好,
可以通过"集合"过渡一下, 来实现列表的去重, 即整个过程是:
原始列表-->集合-->再转回列表
分解来看:
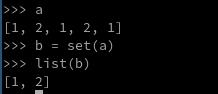
写到一起的形式:
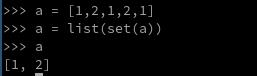
=====
希望可以帮到题主, 欢迎追问.
l=[1,3,4,3,7,0,9,0]
l=list(set(l))
#这里l中没有重复元素了
使用 Python 删除对象列表中的重复项
【中文标题】使用 Python 删除对象列表中的重复项【英文标题】:Remove duplicates in list of object with Python 【发布时间】:2011-05-09 07:53:13 【问题描述】:我有一个对象列表,我有一个充满记录的数据库表。我的对象列表具有标题属性,我想从列表中删除任何具有重复标题的对象(保留原始对象)。
然后我想检查我的对象列表是否与数据库中的任何记录有任何重复,如果有,请在将它们添加到数据库之前从列表中删除这些项目。
我已经看到了从这样的列表中删除重复项的解决方案:myList = list(set(myList)),但我不确定如何处理对象列表?
我也需要维护我的对象列表的顺序。我也在想也许我可以使用difflib 来检查标题的差异。
【问题讨论】:
离开原版,这是什么意思?因为如果像您说的那样,您想保持列表的顺序,那么列表中第一次出现的重复对象将是原始对象? 是的,我的意思是我想删除除原件之外的所有重复项。 @S.Lott,我确实搜索了很多,但没有找到任何东西,这就是我来这里的原因。你能举一个例子来解决这个确切的问题吗?我很高兴看到它。 ***.com/…. 【参考方案1】:由于它们不可散列,因此您不能直接使用集合。标题应该是。
这是第一部分。
seen_titles = set()
new_list = []
for obj in myList:
if obj.title not in seen_titles:
new_list.append(obj)
seen_titles.add(obj.title)
您将需要描述您在第二部分中使用的数据库/ORM 等。
【讨论】:
我正在使用 mysql 和 sqlobject。 @bababa 请更新问题,以便其他人也能看到。 @bababa,我没有看到使用 sqlobject 执行此操作的好方法(即,不在一个查询中从数据库中提取每个对象或对每个对象进行一个查询),所以我会等一会儿然后发布,如果没有比我更了解 sqlobject 的人没有出现。 只是出于好奇,您为什么使用集合而不是字典? dict 键不是也检查 O(1) 吗?【参考方案2】:这似乎很小:
new_dict = dict()
for obj in myList:
if obj.title not in new_dict:
new_dict[obj.title] = obj
【讨论】:
【参考方案3】:set(list_of_objects) 只会在您知道什么是重复项时删除重复项,也就是说,您需要定义对象的唯一性。
为此,您需要使对象可散列。您需要同时定义 __hash__ 和 __eq__ 方法,方法如下:
http://docs.python.org/glossary.html#term-hashable
不过,您可能只需要定义__eq__ 方法。
编辑:如何实现__eq__ 方法:
正如我所提到的,您需要知道对象的唯一性定义。假设我们有一本书,其属性为 author_name 和 title,它们的组合是唯一的,(因此,我们可以有许多 Stephen King 创作的书,以及许多名为 The Shining 的书,但只有一本书名为 The Shining by Stephen King),然后实现如下:
def __eq__(self, other):
return self.author_name==other.author_name\
and self.title==other.title
同样,这就是我有时实现__hash__ 方法的方式:
def __hash__(self):
return hash(('title', self.title,
'author_name', self.author_name))
您可以检查,如果您创建一个包含 2 本书且作者和标题相同的列表,则书籍对象将相同(使用 相等(使用 is 运算符)和== 运算符)。此外,当使用set() 时,它会删除一本书。
编辑:这是我的一个旧答案,但我现在才注意到它有错误,在最后一段中用删除线更正:具有相同 hash() 的对象不会与is 相比,给出True。但是,如果您打算将它们用作集合的元素或字典中的键,则使用对象的哈希性。
【讨论】:
很好,我不知道__hash__ 和__eq__。有关如何实现__eq__ 的任何示例?
你需要确保类是相同的,否则字段将不可用,所以 eq 也需要做self.__class__ == other.__class__ and self.author_name==other.author_name\ and self.title==other.title
我们是否知道哪些“重复”被保留,哪些被丢弃?按照书的例子,假设他们有一个字段 publication_date (同一本书可以有多个版本,因此有多个出版日期)。如果列表最初是按从最近到最旧的顺序排列的,并且我使用这种技术删除了重复项(在定义 __eq__ 时忽略publication_date),我是否知道保留哪个以及丢弃哪个?【参考方案4】:
它很容易成为朋友:-
a = [5,6,7,32,32,32,32,32,32,32,32]
a = list(set(a))
打印(一)
[5,6,7,32]
就是这样! :)
【讨论】:
无法对包含对象的列表执行此操作。【参考方案5】:如果您想保留原始订单,请使用它:
seen =
new_list = [seen.setdefault(x, x) for x in my_list if x not in seen]
如果您不关心订购,请使用它:
new_list = list(set(my_list))
【讨论】:
【参考方案6】:为此需要__hash__ 和__eq__。
需要__hash__ 才能将对象添加到集合中,因为python's sets are implemented as hashtables。默认情况下,像数字、字符串和元组这样的不可变对象是可散列的。
但是,由于鸽巢原理,哈希冲突(两个不同的对象哈希到相同的值)是不可避免的。所以,两个对象不能只用它们的哈希来区分,用户必须指定自己的__eq__函数。因此,用户提供的实际哈希函数并不重要,但最好尽量避免哈希冲突以提高性能(请参阅What's a correct and good way to implement __hash__()?)。
【讨论】:
【参考方案7】:我最近使用了下面的代码。它与其他答案类似,因为它遍历列表并记录它所看到的内容,然后删除它已经看到的任何项目,但它不会创建重复列表,而是只是从原始列表中删除项目。
seen =
for obj in objList:
if obj["key-property"] in seen.keys():
objList.remove(obj)
else:
seen[obj["key-property"]] = 1
【讨论】:
这仅在 objList 包含可比较的对象时才有效(即实现 eq 方法)。有关详细信息,请参阅 ***.com/a/11456817/290588 创建去重列表适用于未实现 eq 的对象。【参考方案8】:如果您不能(或不会)为对象定义 __eq__,您可以使用 dict-comprehension 来达到相同的目的:
unique = list(item.attribute:item for item in mylist.values())
请注意,这将包含给定键的 last 实例,例如
对于mylist = [Item(attribute=1, tag='first'), Item(attribute=1, tag='second'), Item(attribute=2, tag='third')],你会得到[Item(attribute=1, tag='second'), Item(attribute=2, tag='third')]。您可以使用mylist[::-1] 解决此问题(如果存在完整列表)。
【讨论】:
以上是关于python中删除列表中的重复内容的主要内容,如果未能解决你的问题,请参考以下文章