分子进化与系统发育
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分子进化与系统发育相关的知识,希望对你有一定的参考价值。
参考技术A 前言:统计学是一门用途极为广泛的学科,但有效的应用者却寥寥无几。对大多数人而言,传统的通往统计学知识之路被数学这堵令人望而生畏的高墙所阻挡。我们这里走的路就是避开这堵墙。
Efron & Tibshirani(1993)
分子水平进化方面有两门不同的学科:重建生物进化历史和研究进化的机制。近几十年来,这两门学科都取得了显著进展,主要是由于PCR和测序技术的飞速发展,使得大量DNA序列得以测定,大大加速了研究分子进化遗传学的研究速度。除此之外还有另一个原因就是数据分析的统计方法以及计算机技术的发展。
本书的目的是:为分子进化研究提供有用的统计方法,并以实际数据为例,说明如何运用这些方法。
第一章:进化的分子基础
1.1 生命的进化树
从达尔文开始,许多生物学家都想重建地球上所有生命的进化历史,并以系统树的形式描述这部历史。之前主要的研究途径有化石(零散且不完整)、形态学和生理学的比较(比较复杂,不能得出非常清晰的结论),随着分子生物学的进展,人们可以通过比较DNA来研究生物之间的进化关系。
DNA蕴藏的的信息量巨大,同时DNA的进化演变或多或少是有规律的,因此能用数学模型来描述其变化,并且可以比较亲缘关系较远的生物间的DNA。
形态性状的进化演变,即使在一段较短的进化时间,也是及其复杂的(体现在什么方面?)
系统学或分类学是生命科学中争议最多的领域之一。一些分类单元的定义常常带有主观性。相对而言,系统发育学的争论少一点,因为它主要研究的是有机体之间的进化关系,而分类的工作相对没那么重要。
分类应反映有机体的进化历史。
1.2 进化机制
进化的第一原因是基因突变(替代,indel,重组等)。然后通过遗传漂变或自然选择进行扩散,最终固定在物种中。
1.3 基因的结构与功能
从功能上看,基因分为两类:蛋白质编码基因和RNA编码基因。(补充基础知识而已,如蛋白质的编码方式等,密码子的简并性和偏好性)
1.4 DNA序列的突变:
转换、颠换、InDel、倒位、移码突变,提前终止突变等
同义突变,非同义突变和无义突变
短的插入缺失是由于DNA复制差错,长的插入和缺失要借助不等交换和转座。
基因转换会改变一个DNA片段,使其与另一个片段完全相同,但是不改变基因的拷贝数。,这是由于异源DNA的错配修复引起的。
1.5 密码子的使用频率:
原因:1、tRNA丰度不同导致的(高表达)
2、突变压。如不同基因组中GC含量不同,同时也影响了密码子的使用。突变压和净化选择共同影响了密码子的偏好性。
不同的物种,碱基替换模式是不同的,主要体现在GC含量的不同,这给系统发育研究带来了困难。
动植物中,GC含量变化范围很窄,特别是脊椎动物只在40~45% 之间浮动。基因组可根据GC含量的不同分为富GC区和贫GC区,有趣的是,在同质区,GC含量与第三个密码子的GC含量很接近。
密码子用法偏倚的统计测度:
使用密码子出现的绝对次数经常会出现不便之处,因为所检验的密码子总数不一定是相同的,因此密码子用法偏倚的更有用的测度是相对同义密码子使用频率(relative synonymous codon usage,RSCU),
RSCU=Xi / X_ave
Xi:编码该氨基酸低i个密码子的观测数
X_ave:所有编码该氨基酸的密码子的平均使用次数
第二章:氨基酸序列的进化演变
1977年,DNA快速测序法发明(sanger 一代测序)之前,多数分子进化研究是基于氨基酸序列数据的,如分子钟理论的提出,。
2.1 氨基酸差异和不同氨基酸的比例
对于长度相同的序列,通过比较他们差异的氨基酸数目就可以度量序列间的分歧程度,但是当他们之间有插入或者缺失的时候没计算氨基酸差异数是没有意义的,需要将插入缺失的部分排除掉再计算。其实一般都是用比例值表示,称为p值距离。
泊松矫正:
p(差异碱基比例)与t(分化时间)呈现非线性关系的原因有重复突变和选择压力等。
令r为一个特定位点每年的氨基酸替换率,并且假设所有位点的r都相同,t年后,每个位点氨基酸替代的平均数是rt。在一个给定点氨基酸替换数k(k=0,1,2,3,4,5,6...)的发生频率遵循泊松分布:
P(k;t)=e^ -r t * ((rt)^k) /k!
因此,在某一位点氨基酸不变的概率是p(0,t)=e ^ rt
如果多肽链长度为n,不变氨基酸的期望值为ne ^(-rt)
进化三部曲,从互联网大脑发育看产业互联网的未来
导言:从互联网的左右大脑发育看,产业互联网可以看做互联网的下半场,但从互联网大脑的长远发育看,互联网依然处于大脑尚未发育成熟的婴儿时期,未来还需要漫长的时间发育。参考互联网右大脑的发育历程,可以判断产业互联网需要在1.如何形成机器社交网络和2.如何与人类社交网络结合,等两个方面做艰苦的努力。
21世纪是科技大爆发的时代,几乎每两年就会涌现出新的科技热点,从web2.0,社交网络,物联网,云计算、到大数据、工业4.0、边缘计算、云机器人、人工智能,2018年年末,随着腾讯提出要大力开拓互联网发展的下半场,“产业互联网”成为产业界新的热点。
11月1日,在腾讯合作伙伴大会召开前夕,马化腾按照传统写了一封公开信,其中最为核心的主旨,就是宣布腾讯要从消费互联网切换到和产业互联网并轨。作为在中国和世界范围影响巨大的科技公司,这一动向对于互联网和科技未来有着怎样的影响?产业互联网的本质是什么?未来将如何发展?
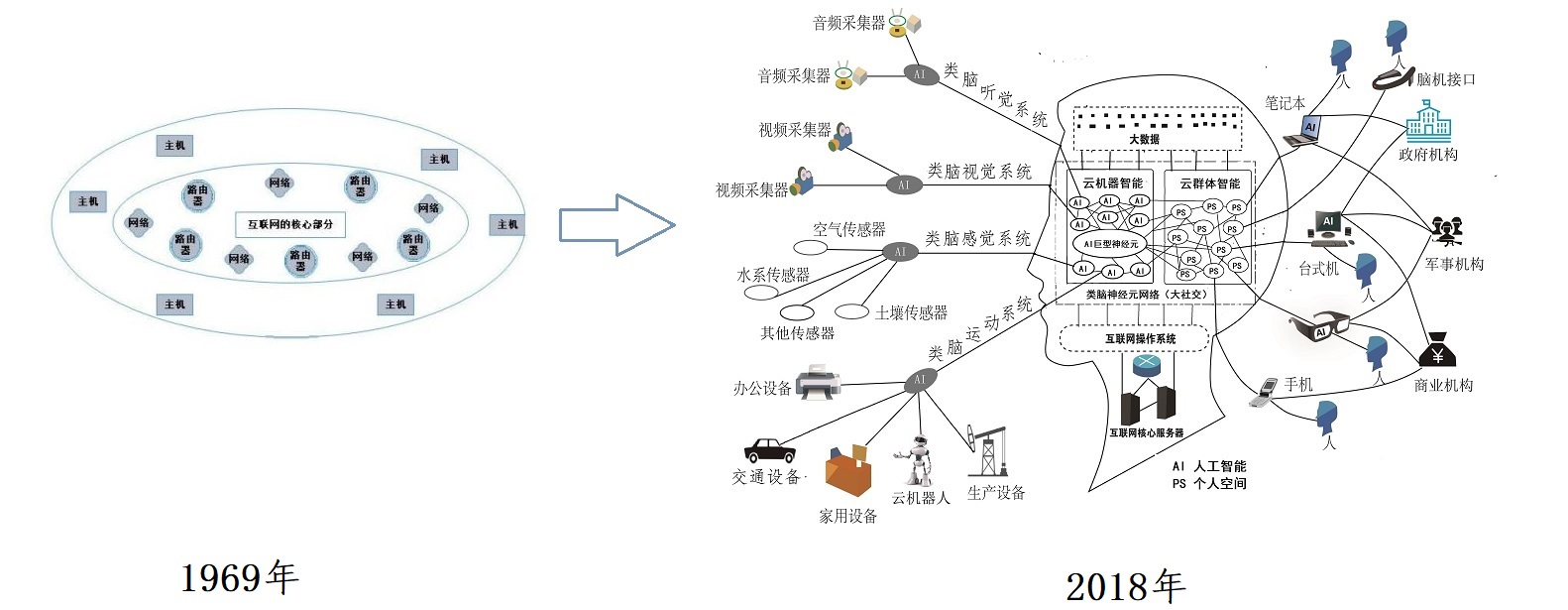
我们在互联网大脑模型的构建和研究中提到【参考1】,互联网在经历了50年的发展,最大的变化是从1969年的网状结构进化成为2018年的类脑架构,这个变化是世界范围科学家和企业家共同推动的产物,同时也反过来影响科技和商业的决策。
互联网的这个类脑巨系统结构并不是在一开始就成熟和完善的,而是经过50年的时间才初见雏形。因此从互联网发育的角度看产业互联网的产生,发展和未来趋势应该会更为明晰。
从1969年,互联网通过TCP/IP协议实现计算机的通讯,通过个人电脑实现互联网的普及,通过万维网实现数据,信息和知识的共享化。在经历了30年的基础建设后,21世纪初,伴随着腾讯、阿里巴巴、Facebook的诞生,这些科技企业将不同领域的人类通过社交网络链接起来,到2018年已经发展成为链接超过40亿人类用户的世界科技巨头。
从特征上看,这时的社交网络主要应用在人类消费、娱乐、工作、生活、学习和研究,从而依托社交网络形成的类脑神经元架构形成了互联网的右大脑,由于这时的互联网主要应用与生活消费领域,因此这种互联网右脑架构可以看做是消费互联网的基础。

在科技不断将人类卷入到互联网大脑模型的同时,互联网的左大脑-云机器智能也在积蓄着力量,等待爆发的那一天。
其中2008年移动通讯和光纤技术开始启动,推动互联网神经纤维的发育;2009年物联网和传感器发展,推动互联网感觉神经系统发育;2012年,工业4.0,工业互联网爆发;推动互联网运动神经系统发育,2013年以后,边缘计算,雾计算等推动了互联网神经末梢的发育,
2015年人工智能开始爆发,云计算与人工智能的结合使得互联网的中枢神经系统得到进一步发展,其中包括2018年产生的阿里ET大脑,360安全大脑,腾讯超级大脑,华为EI智能体。
当这些技术基础完成后,互联网的神经系统开始更多把机器人、无人机、智能汽车、工厂制造设备,家庭生活设备,城市基础设施等智能设备连接起来。这样互联网的左大脑-云机器智能开始正式登上历史舞台。
与互联网右大脑主要应用在消费领域不同,互联网的左大脑将主要应用与工业、农业、航空、能源、建筑,电力,城市建设等产业领域,因此产业互联网的爆发也就成为科技发展的必然阶段。它也可以看做互联网左大脑发育的另一个名称。
从互联网右大脑的发育看,产业互联网的发展还将面临两个重要的发展台阶:
第一是如何通过统一的机器社交网络将遍布世界的数百亿传感器,智能设备链接起来,目前这一进程依然面临着巨大的困难。
第二是如何将互联网的左大脑和右大脑有效的链接在一起,使得人类智慧和机器智慧有机的结合起来,形成统一大社交网络,一个实现人与人,人与物,物与物信息交互的类脑神经元网络。
这两步的实现与过去20年科技的积累将构成产业互联网的进化三部曲。
从互联网的左右大脑发育看,产业互联网可以看做互联网的下半场,但从互联网大脑的长远发育看,互联网依然处于大脑尚未发育成熟的婴儿时期,在未来,它还有诸多功能等待成熟,会从三个方面继续发育,并最终形成一个自然界从未有过的超级智能体。
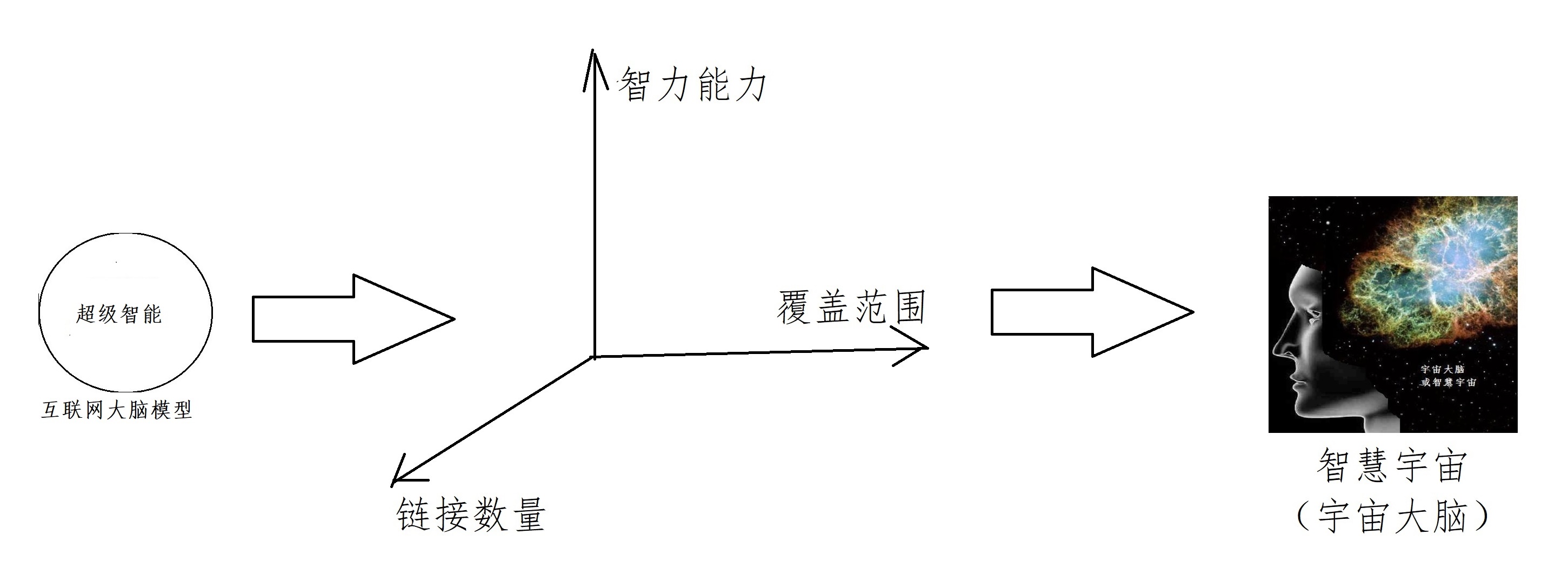
这三个方面分别是:
1.在人类群体智慧和智能设备的机器智能的推动下,互联网大脑智能将持续提升,
2。通过互联网大脑的神经末梢的链接,将更多人类社会和自然世界的元素关联起来
3.通过互联网大脑架构的发育,覆盖范围不断扩大,从美洲到非洲,从地球到火星,从太阳系到银行系。
作者:刘锋 互联网进化论作者,计算机博士
参考1:关于互联网的大脑模型请参阅《”大脑“爆发背后是50年互联网架构重大变革》。http://blog.sciencenet.cn/blog-39263-1136902.html
以上是关于分子进化与系统发育的主要内容,如果未能解决你的问题,请参考以下文章