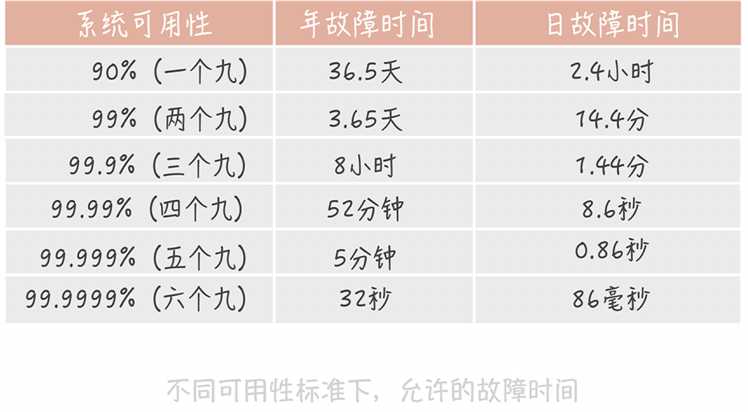
若服务器系统可用性达到99.99%,那么系统平均无故障时间约为多少
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了若服务器系统可用性达到99.99%,那么系统平均无故障时间约为多少相关的知识,希望对你有一定的参考价值。
参考技术A 0.9999*365*24*60 分钟 参考技术B 系统可用性与运行无故障时间没有什么直接关系。一般服务器出厂的无故障时间,可以参阅厂家相关内容的说明。
实际中,平均无故障时间完全跟你实际运行情况相关,没办法给出准确数据,只能依据自身的环境做出评估。本回答被提问者采纳 参考技术C 我用的小鸟云服务器,没有出过问题,性能挺稳定的。
高并发系统设计:系统设计目标②系统怎样做到高可用?
通常来讲,一个高并发大流量的系统,系统出现故障比系统性能低更损伤用户的使用体验。
可用性的度量
可用性是一个抽象的概念,你需要知道要如何来度量它,与之相关的概念是:MTBF和MTTR。
MTBF(Mean Time Between Failure)是平均故障间隔的意思,代表两次故障的间隔时间,也就是系统正常运转的平均时间。这个时间越长,系统稳定性越高。
MTTR(Mean Time To Repair)表示故障的平均恢复时间,也可以理解为平均故障时间。这个值越小,故障对于用户的影响越小。
高可用系统设计的思路
一个成熟系统的可用性需要从系统设计和系统运维两方面来做保障,两者共同作用,缺一不可。
1.系统设计
系统设计是我们做高可用系统设计时秉持的第一原则。在承担百万QPS的高并发系统中,集群中机器的数量成百上千台,单机的故障是常态,几乎每一天都有发生故障的可能。
在做系统设计的时候,要把发生故障作为一个重要的考虑点,预先考虑如何自动化地发现故障,发生故障之后要如何解决。当然了,我们还需要掌握一些具体的优化方法,比如故障转移、超时控制以及降级和限流。
①故障转移
一般来说,发生故障转移的节点可能有两种情况(如mysql的双主热备的两个主服务器):
- 在完全对等的节点之间做转移,也就是同级。
- 在不对等的节点之间,即系统中存在主节点也存在备节点。
举个例子,Nginx可以配置当某一个Tomcat出现大于500的请求的时候,重试请求另一个Tomcat节点,就像下面这样:
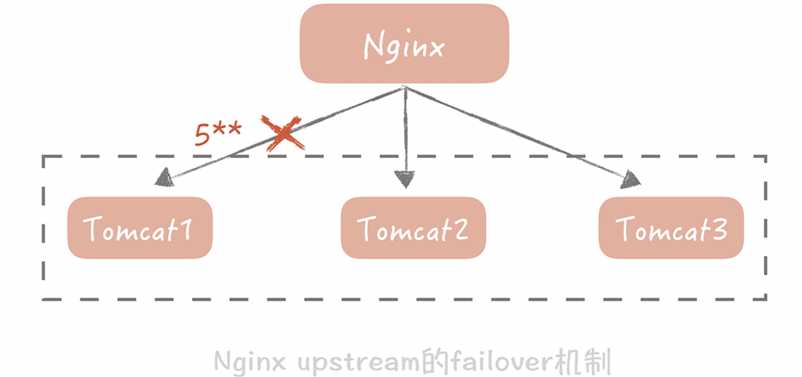
我们就需要在代码中控制如何检测主备机器是否故障,以及如何做主备切换,最广泛的故障检测机制是“心跳”。
②系统间调用超时的控制
复杂的高并发系统通常会有很多的系统模块组成,同时也会依赖很多的组件和服务,比如说缓存组件,队列服务等等。它们之间的调用最怕的就是延迟而非失败,因为失败通常是瞬时的,可以通过重试的方式解决。而一旦调用某一个模块或者服务发生比较大的延迟,调用方就会阻塞在这次调用上,它已经占用的资源得不到释放。当存在大量这种阻塞请求时,调用方就会因为用尽资源而挂掉。
举例:
模块之间通过RPC框架来调用,超时时间是默认的30秒。平时系统运行得非常稳定,可是一旦遇到比较大的流量,RPC服务端出现一定数量慢请求的时候,RPC客户端线程就会大量阻塞在这些慢请求上长达30秒,造成RPC客户端用尽调用线程而挂掉。后面我们在故障复盘的时候发现这个问题后,调整了RPC,数据库,缓存以及调用第三方服务的超时时间,这样在出现慢请求的时候可以触发超时,就不会造成整体系统雪崩。
超时时间短了,会造成大量的超时错误,对用户体验产生影响;超时时间长了,又起不到作用。建议你通过收集系统之间的调用日志,统计比如说99%的响应时间是怎样的,然后依据这个时间来指定超时时间。如果没有调用的日志,那么你只能按照经验值来指定超时时间。不过,无论你使用哪种方式,超时时间都不是一成不变的,需要在后面的系统维护过程中不断地修改。
超时控制实际上就是不让请求一直保持,而是在经过一定时间之后让请求失败,释放资源给接下来的请求使用。这对于用户来说是有损的,但是却是必要的,因为它牺牲了少量的请求却保证了整体系统的可用性。
③降级
降级是为了保证核心服务的稳定而牺牲非核心服务的做法。比方说我们发一条微博会先经过反垃圾服务检测,检测内容是否是广告,通过后才会完成诸如写数据库等逻辑。
反垃圾的检测是一个相对比较重的操作,因为涉及到非常多的策略匹配,在日常流量下虽然会比较耗时却还能正常响应。但是当并发较高的情况下,它就有可能成为瓶颈,而且它也不是发布微博的主体流程,所以我们可以暂时关闭反垃圾服务检测,这样就可以保证主体的流程更加稳定。
④限流
比如对于Web应用,我限制单机只能处理每秒1000次的请求,超过的部分直接返回错误给客户端。虽然这种做法损害了用户的使用体验,但是它是在极端并发下的无奈之举,是短暂的行为,因此是可以接受的。
2.系统运维
从灰度发布、故障演练两个方面来考虑如何提升系统的可用性。
①灰度发布
在业务平稳运行过程中,系统是很少发生故障的,90%的故障是发生在上线变更阶段的。比如你上了一个新的功能,由于设计方案的问题,数据库的慢请求数翻了一倍,导致系统请求被拖慢而产生故障。
如果没有变更,数据库怎么会无缘无故地产生那么多的慢请求呢?因此,为了提升系统的可用性,重视变更管理尤为重要。而除了提供必要回滚方案,以便在出现问题时快速回滚恢复之外,另一个主要的手段就是灰度发布。
灰度发布指的是系统的变更不是一次性地推到线上的,而是按照一定比例逐步推进的。一般情况下,灰度发布是以机器维度进行的。比方说,我们先在10%的机器上进行变更,同时观察Dashboard上的系统性能指标以及错误日志。如果运行了一段时间之后系统指标比较平稳并且没有出现大量的错误日志,那么再推动全量变更。灰度发布给了开发和运维同学绝佳的机会,让他们能在线上流量上观察变更带来的影响,是保证系统高可用的重要关卡。
②故障演练
故障演练指的是对系统进行一些破坏性的手段,观察在出现局部故障时,整体的系统表现是怎样的,从而发现系统中存在的,潜在的可用性问题。
一个复杂的高并发系统依赖了太多的组件,比方说磁盘,数据库,网卡等,这些组件随时随地都可能会发生故障。建议你另外搭建一套和线上部署结构一模一样的线下系统,然后在这套系统上做故障演练,从而避免对生产系统造成影响。
以上是关于若服务器系统可用性达到99.99%,那么系统平均无故障时间约为多少的主要内容,如果未能解决你的问题,请参考以下文章