python软文格式转换问题
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python软文格式转换问题相关的知识,希望对你有一定的参考价值。
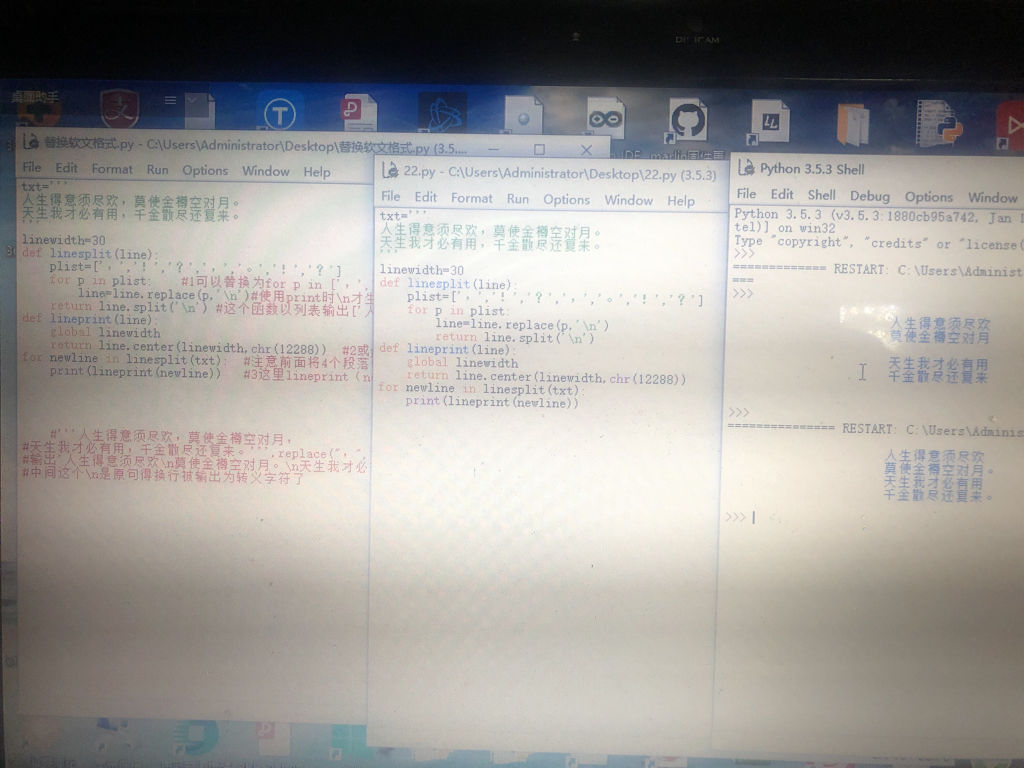
老师们帮我看下啊,左右两个一模一样的程序,为什么右边的输出比左边的多两个句号啊,到底哪里出问题了啊
unicodestring = u"Hello world"
# 将Unicode转化为普通Python字符串:"encode"
utf8string = unicodestring.encode("utf-8")
asciistring = unicodestring.encode("ascii")
isostring = unicodestring.encode("ISO-8859-1")
utf16string = unicodestring.encode("utf-16")
# 将普通Python字符串转化为Unicode:"decode"
plainstring1 = unicode(utf8string, "utf-8")
plainstring2 = unicode(asciistring, "ascii")
plainstring3 = unicode(isostring, "ISO-8859-1")
plainstring4 = unicode(utf16string, "utf-16")
assert plainstring1 == plainstring2 == plainstring3 == plainstring4 参考技术A 这个图看起来太麻烦了,你贴代码不行么。还有,这种情况,你检查下句号是不是都是中文的,说不定你第二份代码识别的是英文的句号呢。
Python:如何将 Markdown 格式的文本转换为文本
【中文标题】Python:如何将 Markdown 格式的文本转换为文本【英文标题】:Python : How to convert markdown formatted text to text 【发布时间】:2010-10-20 04:41:50 【问题描述】:我需要将 markdown 文本转换为纯文本格式以在我的网站中显示摘要。我想要python中的代码。
【问题讨论】:
不是 python,但你可以将它传递给 pandoc:pandoc --to=plain 留下一些格式(标题取消划线),但不多。
【参考方案1】:
Markdown 和 BeautifulSoup(现在称为 beautifulsoup4)模块将帮助您完成您所描述的工作。
将markdown 转换为HTML 后,您可以使用HTML 解析器去除纯文本。
您的代码可能如下所示:
from bs4 import BeautifulSoup
from markdown import markdown
html = markdown(some_html_string)
text = ''.join(BeautifulSoup(html).findAll(text=True))
【讨论】:
好像转换成html..我需要转换成纯文本..像***,在主页问题摘要中,它删除了格式 感谢 coonj.. 很高兴了解 BeatifulSoup 从 Markdown 到 HTML 来回转换太多了,下面有一个很好的选择,只坚持 Markdown。【参考方案2】:尽管这是一个非常古老的问题,但我想提出一个我最近提出的解决方案。这个既不使用 BeautifulSoup,也没有转换为 html 和返回的开销。
markdown 模块核心类 Markdown 有一个属性 output_formats,它是不可配置的,但可以像 python 中的几乎任何东西一样进行修补。此属性是将输出格式名称映射到渲染函数的字典。默认情况下,它有两种输出格式,'html' 和 'xhtml' 对应。稍加帮助,它可能有一个易于编写的明文渲染功能:
from markdown import Markdown
from io import StringIO
def unmark_element(element, stream=None):
if stream is None:
stream = StringIO()
if element.text:
stream.write(element.text)
for sub in element:
unmark_element(sub, stream)
if element.tail:
stream.write(element.tail)
return stream.getvalue()
# patching Markdown
Markdown.output_formats["plain"] = unmark_element
__md = Markdown(output_format="plain")
__md.stripTopLevelTags = False
def unmark(text):
return __md.convert(text)
unmark 函数将 markdown 文本作为输入,并返回所有删除的 markdown 字符。
【讨论】:
看起来很棒,非常感谢您花时间添加答案,即使问题已经很老了。非常感谢!【参考方案3】:这类似于 Jason 的回答,但正确处理 cmets。
import markdown # pip install markdown
from bs4 import BeautifulSoup # pip install beautifulsoup4
def md_to_text(md):
html = markdown.markdown(md)
soup = BeautifulSoup(html, features='html.parser')
return soup.get_text()
def example():
md = '**A** [B](http://example.com) <!-- C -->'
text = md_to_text(md)
print(text)
# Output: A B
【讨论】:
【参考方案4】:评论并删除它,因为我终于认为我在这里看到了问题:将您的降价文本转换为 HTML 并从文本中删除 HTML 可能更容易。我不知道有什么可以有效地从文本中删除降价,但是有很多 HTML 到纯文本的解决方案。
【讨论】:
非常感谢 Markdown 是“基本上是纯文本”。如果很难剥离,不妨使用 Word。【参考方案5】:我是在寻找执行 s.c. 的方法时来到这里的。 GitLab Releases 通过API call。我希望这与原始提问者的用例相匹配。
我以这种方式将markdown解码为纯文本(包括\n等形式的空格):
with open("release_note.md", 'r') as file:
release_note = file.read()
description = bytes(release_note, 'utf-8')
return description.decode("utf-8")
【讨论】:
以上是关于python软文格式转换问题的主要内容,如果未能解决你的问题,请参考以下文章