如何用python统计单词的频率
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何用python统计单词的频率相关的知识,希望对你有一定的参考价值。
参考技术A代码:
passage="""Editor’s Note: Looking through VOA's listener mail, we came across a letter that asked a simple question. "What do Americans think about China?" We all care about the perceptions of others. It helps us better understand who we are. VOA Reporter Michael Lipin begins a series providing some answers to our listener's question. His assignment: present a clearer picture of what Americans think about their chief world rival, and what drives those perceptions.
Two common American attitudes toward China can be identified from the latest U.S. public opinion surveys published by Gallup and Pew Research Center in the past year.
First, most of the Americans surveyed have unfavorable opinions of China as a whole, but do not view the country as a threat toward the United States at the present time.
Second, most survey respondents expect China to pose an economic and military threat to the United States in the future, with more Americans worried about the perceived economic threat than the military one.
Most Americans view China unfavorably
To understand why most Americans appear to have negative feelings about China, analysts interviewed by VOA say a variety of factors should be considered. Primary among them is a lack of familiarity.
"Most Americans do not have a strong interest in foreign affairs, Chinese or otherwise," says Robert Daly, director of the Kissinger Institute on China and the United States at the Washington-based Wilson Center.
Many of those Americans also have never traveled to China, in part because of the distance and expense. "That means that like most human beings, they take short cuts to understanding China," Daly says.
Rather than make the effort to regularly consume a wide range of U.S. media reports about China, analysts say many Americans base their views on widely-publicized major events in China's recent history."""
passage=passage.replace(","," ").replace("."," ").replace(":"," ").replace("’","'").\\
replace('"'," ").replace("?"," ").replace("!"," ").replace("\\n"," ")#把标点改成空格
passagelist=passage.split(" ")#拆分成一个个单词
pc=passagelist.copy()#复制一份
for i in range(len(pc)):
pi=pc[i]#这一个字符串
if pi.count(" ")==len(pi):#如果全是空格
passagelist.remove(pi)#删除此项
worddict=
for j in range(len(passagelist)):
pj=passagelist[j]#这一个单词
if pj not in worddict:#如果未被统计到
worddict[pj]=1#增加单词统计,次数设为1
else:#如果统计过了
worddict[pj]+=1#次数增加1
output=""#按照字母表顺序,制表符
worddictlist=list(worddict.keys())#提取所有的单词
worddictlist.sort()#排序(但大小写会出现问题)
worddict2=
for k in worddictlist:
worddict2[k]=worddict[k]#排序好的字典
print("单次\\t\\t次数")
for m in worddict2:#遍历输出
tabs=(23-len(m))//8#根据单次长度输入,如果复制到表格,请把此行改为tabs=2
print("%s%s%d"%(m,"\\t"*tabs,worddict[m]))
注:加粗部分是您要统计的短文,请修改。我这里的输出效果是:
American 1
Americans 9
Center 2
China 10
China's 1
Chinese 1
Daly 2
Editor's 1
First 1
Gallup 1
His 1
Institute 1
It 1
Kissinger 1
Lipin 1
Looking 1
Many 1
Michael 1
Most 2
Note 1
Pew 1
Primary 1
Rather 1
Reporter 1
Research 1
Robert 1
S 2
Second 1
States 3
That 1
To 1
Two 1
U 2
United 3
VOA 2
VOA's 1
Washington-based1
We 1
What 1
Wilson 1
a 10
about 6
across 1
affairs 1
all 1
also 1
among 1
an 1
analysts 2
and 5
answers 1
appear 1
are 1
as 2
asked 1
assignment 1
at 2
attitudes 1
base 1
be 2
because 1
begins 1
beings 1
better 1
but 1
by 2
came 1
can 1
care 1
chief 1
clearer 1
common 1
considered 1
consume 1
country 1
cuts 1
director 1
distance 1
do 3
drives 1
economic 2
effort 1
events 1
expect 1
expense 1
factors 1
familiarity 1
feelings 1
foreign 1
from 1
future 1
have 4
helps 1
history 1
human 1
identified 1
in 5
interest 1
interviewed 1
is 1
lack 1
latest 1
letter 1
like 1
listener 1
listener's 1
mail 1
major 1
make 1
many 1
means 1
media 1
military 2
more 1
most 4
negative 1
never 1
not 2
of 10
on 2
one 1
opinion 1
opinions 1
or 1
others 1
otherwise 1
our 1
part 1
past 1
perceived 1
perceptions 2
picture 1
pose 1
present 2
providing 1
public 1
published 1
question 2
range 1
recent 1
regularly 1
reports 1
respondents 1
rival 1
say 2
says 2
series 1
short 1
should 1
simple 1
some 1
strong 1
survey 1
surveyed 1
surveys 1
take 1
than 2
that 2
the 16
their 2
them 1
they 1
think 2
those 2
threat 3
through 1
time 1
to 7
toward 2
traveled 1
understand 2
understanding 1
unfavorable 1
unfavorably 1
us 1
variety 1
view 2
views 1
we 2
what 2
who 1
whole 1
why 1
wide 1
widely-publicized1
with 1
world 1
worried 1
year 1
(应该是对齐的,到这就乱了)
注:目前难以解决的漏洞
1、大小写问题,无法分辨哪些必须大写哪些只是首字母大写
2、's问题,目前如果含有只能算为一个单词里的
3、排序问题,很难做到按照出现次数排序
如何用python统计一个txt文件中各个单词出现的次数
1、首先,定义一个变量,保存要统计的英文文章。

2、接着,定义两个数组,保存文章中的单词,以及各单词的词频。
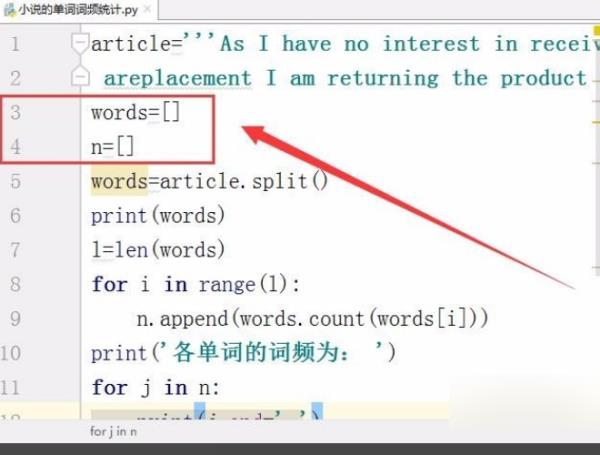
3、从文章中分割出所有的单词,保存在数组中。
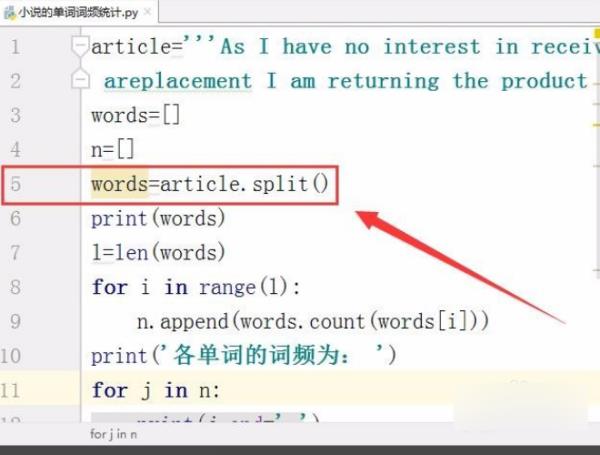
4、然后,计算文章中单词的总数,保存在变量中。

5、用for循环,统计文章中各单词的词频。

6、最后,输出文章中各单词的词频。
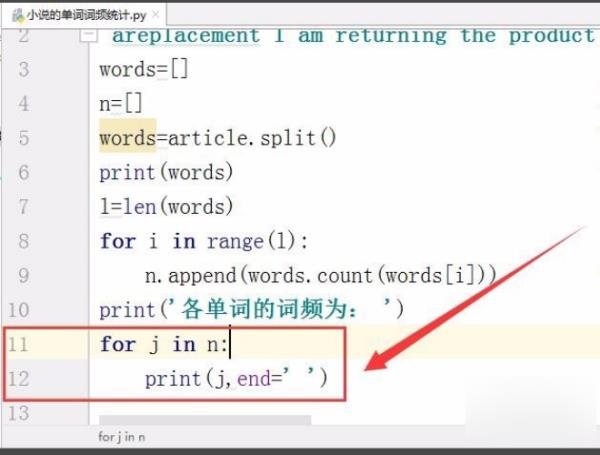
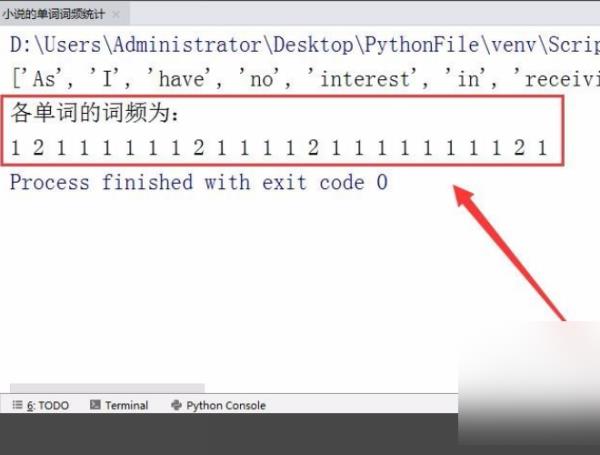
7、运行程序,电脑会自动统计输入文章中各单词的词频。
wth open("文件") as fr:
for line in fr:
lines = line.strip().split(" ") #假设单词与单词之间,空格做为分隔符
for word in lines:
if word not in content:
content[word] = 0
content[word] += 1
for word,val in content.items():
print '%s:%d\n"%(word,val)本回答被提问者采纳
以上是关于如何用python统计单词的频率的主要内容,如果未能解决你的问题,请参考以下文章
统计一段文章的单词频率,取出频率最高的5个单词和个数(python)