python 如何将数据写入某个csv文件的特定位置?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python 如何将数据写入某个csv文件的特定位置?相关的知识,希望对你有一定的参考价值。
我有两个csv文件,分别是a.csv和b.csv,
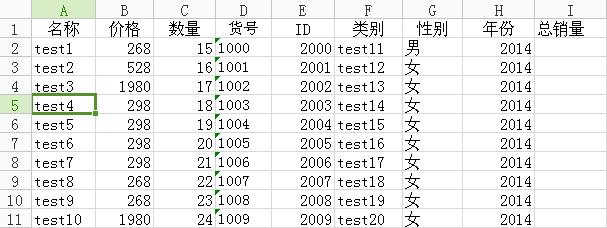
a.csv如图,文件链接:http://pan.baidu.com/s/1pJoIIvD
b.csv如图,文件链接:http://pan.baidu.com/s/1mgNuKis
这两个文件中的“ID”字段有些是相同的,如b.csv中的A4单元格与a.csv中的E4单元格是相同的,这样两个表格就产生了联系。
那么请问,如何将b.csv中的E4单元格内容“137”填入a.csv中I4单元格内呢?
#所以只要用python中的open函数打开就可以了。
#我把修改后的文件存为b_out.csv了
b_int=
for i in open('b.csv').readlines()[1:]:
j=i.split(',')
if len(j)>2:
b_int[j[0]]=j[4]
a_int=open('a.csv').readlines()
for i in range(1,len(a_int)):
a_int_=a_int[i].rstrip().split(',')
a_int_[-1]=b_int.get(a_int_[4],'0')
a_int[i]=','.join(a_int_)+'\\n'
open('b_out.csv','w').write(''.join(a_int)) 参考技术A 具体如下:
# _*_ coding:utf-8 _*_
#xiaohei.python.seo.call.me:)
#win+python2.7.x
import csv
csvfile = file('csvtest.csv', 'wb')
writer = csv.writer(csvfile)
writer.writerow(['id', 'url', 'keywords'])
data = [
('1', 'http://www.xiaoheiseo.com/', '小黑'),
('2', 'http://www.baidu.com/', '百度'),
('3', 'http://www.jd.com/', '京东')
]
writer.writerows(data)
csvfile.close() 参考技术B 直接vlookup不就好了吗。。。。为什么要写代码
如何将数据从 python 列表中的列和行写入 csv 文件?
【中文标题】如何将数据从 python 列表中的列和行写入 csv 文件?【英文标题】:How do I write data to csv file in columns and rows from a list in python? 【发布时间】:2011-11-23 15:14:53 【问题描述】:我有一个列表列表,我想将它们写入包含列和行的 csv 文件中。我曾尝试使用writerows,但这不是我想要的。我的列表示例如下:
[[1, 2], [2, 3], [4, 5]]
有了这个:
example = csv.writer(open('test.csv', 'wb'), delimiter=' ')
example.writerows([[1, 2], [2, 3], [4, 5]])
我在一个单元格中得到1 2,在一个单元格中得到2 3,等等。而不是在一个单元格中得到1,在下一个单元格中没有2。
我需要将此示例列表写入一个文件,因此当我使用 Excel 打开它时,每个元素都在其自己的单元格中。
我的输出应该是这样的:
1 2
2 3
4 5
不同单元格中的每个元素。
【问题讨论】:
“在一个单元格中”在 csv 世界中没有多大意义。无论如何,您的代码DOES 会按照您所说的去做。你是如何显示输出文件的?? 【参考方案1】:提供的示例使用csv 模块,非常棒!此外,您始终可以使用格式化字符串简单地写入文本文件,如以下试探性示例:
l = [[1, 2], [2, 3], [4, 5]]
out = open('out.csv', 'w')
for row in l:
for column in row:
out.write('%d;' % column)
out.write('\n')
out.close()
我使用; 作为分隔符,因为它最适用于 Excell(您的要求之一)。
希望对你有帮助!
【讨论】:
你有一个额外的;在每一行的末尾。一次写一个单元格很笨重。一种 ;在使用逗号作为小数点的语言环境中,ONLY 最适合 Excel。当他所需要的只是对他对csv.writer 的调用进行一些调整时,为什么要向 OP 展示这个 DIY 东西??
@John Machin:其他一些读者可能更喜欢这种方法。如果他已经在使用csv,我怀疑 OP 会回去做 DIY。但我认为 SO 是一个你可以学习新的做事方式并从中选择的地方。此外,通过字符串格式化操作,您还可以使用首选字段分隔符、行尾等。【参考方案2】:
>>> import csv
>>> with open('test.csv', 'wb') as f:
... wtr = csv.writer(f, delimiter= ' ')
... wtr.writerows( [[1, 2], [2, 3], [4, 5]])
...
>>> with open('test.csv', 'r') as f:
... for line in f:
... print line,
...
1 2 <<=== Exactly what you said that you wanted.
2 3
4 5
>>>
要获取它以便 Excel 可以合理地加载它,您需要使用逗号(csv 默认值)作为分隔符,除非您位于需要分号的区域(例如欧洲)。
【讨论】:
【参考方案3】:好吧,如果您正在写入 CSV 文件,那么为什么要使用空格作为分隔符? CSV 文件使用逗号或分号(在 Excel 中)作为单元格分隔符,因此如果您使用 delimiter=' ',您并没有真正生成 CSV 文件。您应该使用默认分隔符和方言简单地构造csv.writer。如果您想稍后将 CSV 文件读入 Excel,您可以明确指定 Excel 方言以明确您的意图(尽管此方言是默认方言):
example = csv.writer(open("test.csv", "wb"), dialect="excel")
【讨论】:
【参考方案4】:试试这些代码:
>>> import pyexcel as pe
>>> sheet = pe.Sheet(data)
>>> data=[[1, 2], [2, 3], [4, 5]]
>>> sheet
Sheet Name: pyexcel
+---+---+
| 1 | 2 |
+---+---+
| 2 | 3 |
+---+---+
| 4 | 5 |
+---+---+
>>> sheet.save_as("one.csv")
>>> b = [[126, 125, 123, 122, 123, 125, 128, 127, 128, 129, 130, 130, 128, 126, 124, 126, 126, 128, 129, 130, 130, 130, 130, 132, 132, 132, 132, 132, 132, 132, 132, 132, 132, 132, 132, 132, 132, 132, 132, 132, 132, 132, 132, 132, 132, 132, 132, 134, 134, 134, 134, 134, 134, 134, 134, 133, 134, 135, 134, 133, 133, 134, 135, 136], [135, 135, 136, 137, 137, 136, 134, 135, 135, 135, 134, 134, 133, 133, 133, 134, 134, 134, 133, 133, 132, 132, 132, 135, 135, 133, 133, 133, 133, 135, 135, 131, 135, 136, 134, 133, 136, 137, 136, 133, 134, 135, 136, 136, 135, 134, 133, 133, 134, 135, 136, 136, 136, 135, 134, 135, 138, 138, 135, 135, 138, 138, 135, 139], [137, 135, 136, 138, 139, 137, 135, 142, 139, 137, 139, 138, 136, 137, 141, 138, 138, 139, 139, 139, 139, 138, 138, 138, 138, 137, 137, 137, 137, 138, 138, 136, 137, 137, 137, 137, 137, 137, 138, 148, 144, 140, 138, 137, 138, 138, 138, 137, 137, 137, 137, 137, 138, 139, 140, 141, 141, 141, 141, 141, 141, 141, 141, 141], [141, 141, 141, 141, 141, 141, 141, 139, 139, 139, 140, 140, 141, 141, 141, 140, 140, 140, 140, 140, 141, 142, 143, 138, 138, 138, 139, 139, 140, 140, 140, 141, 140, 139, 139, 141, 141, 140, 139, 145, 137, 137, 145, 145, 137, 137, 144, 141, 139, 146, 134, 145, 140, 149, 144, 145, 142, 140, 141, 144, 145, 142, 139, 140]]
>>> s2 = pe.Sheet(b)
>>> s2
Sheet Name: pyexcel
+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+
| 126 | 125 | 123 | 122 | 123 | 125 | 128 | 127 | 128 | 129 | 130 | 130 | 128 | 126 | 124 | 126 | 126 | 128 | 129 | 130 | 130 | 130 | 130 | 132 | 132 | 132 | 132 | 132 | 132 | 132 | 132 | 132 | 132 | 132 | 132 | 132 | 132 | 132 | 132 | 132 | 132 | 132 | 132 | 132 | 132 | 132 | 132 | 134 | 134 | 134 | 134 | 134 | 134 | 134 | 134 | 133 | 134 | 135 | 134 | 133 | 133 | 134 | 135 | 136 |
+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+
| 135 | 135 | 136 | 137 | 137 | 136 | 134 | 135 | 135 | 135 | 134 | 134 | 133 | 133 | 133 | 134 | 134 | 134 | 133 | 133 | 132 | 132 | 132 | 135 | 135 | 133 | 133 | 133 | 133 | 135 | 135 | 131 | 135 | 136 | 134 | 133 | 136 | 137 | 136 | 133 | 134 | 135 | 136 | 136 | 135 | 134 | 133 | 133 | 134 | 135 | 136 | 136 | 136 | 135 | 134 | 135 | 138 | 138 | 135 | 135 | 138 | 138 | 135 | 139 |
+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+
| 137 | 135 | 136 | 138 | 139 | 137 | 135 | 142 | 139 | 137 | 139 | 138 | 136 | 137 | 141 | 138 | 138 | 139 | 139 | 139 | 139 | 138 | 138 | 138 | 138 | 137 | 137 | 137 | 137 | 138 | 138 | 136 | 137 | 137 | 137 | 137 | 137 | 137 | 138 | 148 | 144 | 140 | 138 | 137 | 138 | 138 | 138 | 137 | 137 | 137 | 137 | 137 | 138 | 139 | 140 | 141 | 141 | 141 | 141 | 141 | 141 | 141 | 141 | 141 |
+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+
| 141 | 141 | 141 | 141 | 141 | 141 | 141 | 139 | 139 | 139 | 140 | 140 | 141 | 141 | 141 | 140 | 140 | 140 | 140 | 140 | 141 | 142 | 143 | 138 | 138 | 138 | 139 | 139 | 140 | 140 | 140 | 141 | 140 | 139 | 139 | 141 | 141 | 140 | 139 | 145 | 137 | 137 | 145 | 145 | 137 | 137 | 144 | 141 | 139 | 146 | 134 | 145 | 140 | 149 | 144 | 145 | 142 | 140 | 141 | 144 | 145 | 142 | 139 | 140 |
+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+-----+
>>> s2[0,0]
126
>>> s2.save_as("two.csv")
【讨论】:
【参考方案5】:import pandas as pd
header=['a','b','v']
df=pd.DataFrame(columns=header)
for i in range(len(doc_list)):
d_id=(test_data.filenames[i]).split('\\')
doc_id.append(d_id[len(d_id)-1])
df['a']=doc_id
print(df.head())
df[column_names_to_be_updated]=np.asanyarray(data)
print(df.head())
df.to_csv('output.csv')
使用 pandas 数据框,我们可以写入 csv。 首先根据您在 csv 中存储的需要创建一个数据框。 然后使用 pd.DataFrame.to_csv() API 创建数据帧的 csv。
【讨论】:
以上是关于python 如何将数据写入某个csv文件的特定位置?的主要内容,如果未能解决你的问题,请参考以下文章