MySQL数据库的警告问题,怎么解决
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL数据库的警告问题,怎么解决相关的知识,希望对你有一定的参考价值。
参考技术A测试环境中出现了一个异常的告警现象:一条告警通过 Thanos Ruler 的 HTTP 接口观察到持续处于 active 状态,但是从 AlertManager 这边看这条告警为已解决状态。按照 DMP 平台的设计,告警已解决指的是告警上设置的结束时间已经过了当前时间。一条发送至 AlertManager 的告警为已解决状态有三种可能:1. 手动解决了告警2. 告警只产生了一次,第二次计算告警规则时会发送一个已解决的告警3. AlertManager 接收到的告警会带着一个自动解决时间,如果还没到达自动解决时间,则将该时间重置为 24h 后首先,因为了解到测试环境没有手动解决过异常告警,排除第一条;其次,由于该告警持续处于 active 状态,所以不会是因为告警只产生了一次而接收到已解决状态的告警,排除第二条;最后,告警的告警的产生时间与自动解决时间相差不是 24h,排除第三条。那问题出在什么地方呢?
分析
下面我们开始分析这个问题。综合第一节的描述,初步的猜想是告警在到达 AlertManager 前的某些阶段的处理过程太长,导致告警到达 AlertManager 后就已经过了自动解决时间。我们从分析平台里一条告警的流转过程入手,找出告警在哪个处理阶段耗时过长。首先,一条告警的产生需要两方面的配合:
metric 数据
告警规则
将 metric 数据输入到告警规则进行计算,如果符合条件则产生告警。DMP 平台集成了 Thanos 的相关组件,数据的提供和计算则会分开,数据还是由 Prometheus Server 提供,而告警规则的计算则交由 Thanos Rule(下文简称 Ruler)处理。下图是 Ruler 组件在集群中所处的位置:
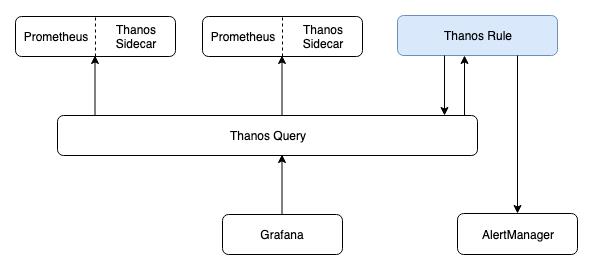
看来,想要弄清楚现告警的产生到 AlertManager 之间的过程,需要先弄清除 Ruler 的大致机制。官方文档对 Ruler 的介绍是:You can think of Rule as a simplified Prometheus that does not require a sidecar and does not scrape and do PromQL evaluation (no QueryAPI)。
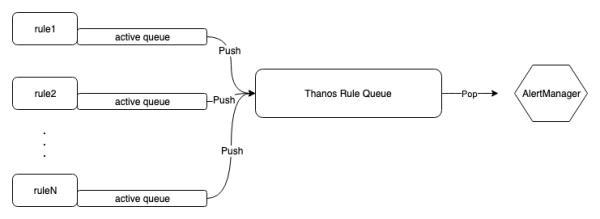
不难推测,Ruler 应该是在 Prometheus 上封装了一层,并提供一些额外的功能。通过翻阅资料大致了解,Ruler 使用 Prometheus 提供的库计算告警规则,并提供一些额外的功能。下面是 Ruler 中告警流转过程:
请点击输入图片描述
请点击输入图片描述
首先,图中每个告警规则 Rule 都有一个 active queue(下面简称本地队列),用来保存一个告警规则下的活跃告警。
其次,从本地队列中取出告警,发送至 AlertManager 前,会被放入 Thanos Rule Queue(下面简称缓冲队列),该缓冲队列有两个属性:
capacity(默认值为 10000):控制缓冲队列的大小,
maxBatchSize(默认值为 100):控制单次发送到 AlertManager 的最大告警数
了解了上述过程,再通过翻阅 Ruler 源码发现,一条告警在放入缓冲队列前,会为其设置一个默认的自动解决时间(当前时间 + 3m),这里是影响告警自动解决的开始时间,在这以后,有两个阶段可能影响告警的处理:1. 缓冲队列阶段2. 出缓冲队列到 AlertManager 阶段(网络延迟影响)由于测试环境是局域网环境,并且也没在环境上发现网络相关的问题,我们初步排除第二个阶段的影响,下面我们将注意力放在缓冲队列上。通过相关源码发现,告警在缓冲队列中的处理过程大致如下:如果本地队列中存在一条告警,其上次发送之间距离现在超过了 1m(默认值,可修改),则将该告警放入缓冲队列,并从缓冲队列中推送最多 maxBatchSize 个告警发送至 AlertManager。反之,如果所有本地队列中的告警,在最近 1m 内都有发送过,那么就不会推送缓冲队列中的告警。也就是说,如果在一段时间内,产生了大量重复的告警,缓冲队列的推送频率会下降。队列的生产方太多,消费方太少,该队列中的告警就会产生堆积的现象。因此我们不难猜测,问题原因很可能是是缓冲队列推送频率变低的情况下,单次推送的告警数量太少,导致缓冲队列堆积。下面我们通过两个方面验证上述猜想:首先通过日志可以得到队列在大约 20000s 内推送了大约 2000 次,即平均 10s 推送一次。结合缓冲队列的具体属性,一条存在于队列中的告警大约需要 (capacity/maxBatchSize)*10s = 16m,AlertManager 在接收到告警后早已超过了默认的自动解决时间(3m)。其次,Ruler 提供了 3 个 metric 的值来监控缓冲队列的运行情况:
thanos_alert_queue_alerts_dropped_total
thanos_alert_queue_alerts_pushed_total
thanos_alert_queue_alerts_popped_total
通过观察 thanos_alert_queue_alerts_dropped_total 的值,看到存在告警丢失的总数,也能佐证了缓冲队列在某些时刻存在已满的情况。
解决通过以上的分析,我们基本确定了问题的根源:Ruler 组件内置的缓冲队列堆积造成了告警发送的延迟。针对这个问题,我们选择调整队列的 maxBatchSize 值。下面介绍一下这个值如何设置的思路。由于每计算一次告警规则就会尝试推送一次缓冲队列,我们通过估计一个告警数量的最大值,得到 maxBatchSize 可以设置的最小值。假设你的业务系统需要监控的实体数量分别为 x1、x2、x3、...、xn,实体上的告警规则数量分别有 y1、y2、y3、...、yn,那么一次能产生的告警数量最多是(x1 * y2 + x2 * y2 + x3 * y3 + ... + xn * yn),最多推送(y1 + y2 + y3 + ... + yn)次,所以要使缓冲队列不堆积,maxBatchSize 应该满足:maxBatchSize >= (x1 * y2 + x2 * y2 + x3 * y3 + ... + xn * yn) / (y1 + y2 + y3 + ... + yn),假设 x = max(x1,x2, ...,xn), 将不等式右边适当放大后为 x,即 maxBatchSize 的最小值为 x。也就是说,可以将 maxBatchSize 设置为系统中数量最大的那一类监控实体,对于 DMP 平台,一般来说是 mysql 实例。
注意事项
上面的计算过程只是提供一个参考思路,如果最终计算出该值过大,很有可能对 AlertManager 造成压力,因而失去缓冲队列的作用,所以还是需要结合实际情况,具体分析。因为 DMP 将 Ruler 集成到了自己的组件中,所以可以比较方便地对这个值进行修改。如果是依照官方文档的介绍使用的 Ruler 组件,那么需要对源码文件进行定制化修改。
里面有异常
zabbix监控mysql5.6版本出不了图,怎么办?这里有解决办法!!!
问题:今天我把本地的zabbix对mysql监控的部署系统转到云主机上,发现出现下图的情况(搭建过程可参考http://blog.51cto.com/xiaozhagn/2059430)

然而我在云服务器zabbix上在获取的数据的时出现以下警告,(所监控的数据库版本是mysql5.6.x):
#zabbix_get -s 10.100.10.10 -k mysql.status[Com_insert]
Warning: Using a password on the command line interface can be insecure.
7
可以发现问题就是出现在这里,这可急死我了,咋办呢,然后我把zabbix监控mySQL出现的警告, 在google、百度找了很多解决办法,也试了很多,包括以下的内容:
1、使用mysql_config_editor进行无密码操作。
2、修改my.conf配置文件,将mysqladmin用户名密码写入配置文件。
Cat /usr/my.cnf
[mysqladmin]
user=zabbix
password=xiaozhang
3、修改my.conf配置文件,将client用户名密码写入配置文件。
[client]
user=zabbix
password=xiaozhang
4、也试过在zabbix服务端寻找过滤返回值的操作。
最后发现,以上是的方法都是没起作用,那个警告一直存在
解决办法以及思路:
后来想到,整个问题的所在,是因为使用mysqladmin命令是出现了警告,而导致zabbix服务端获取不了监控数据信息。所以,我们可以忽略这个警告信息,把它扔到垃圾箱就好。
进入,zabbix客户端的mysql监控脚本
#vim /usr/local/zabbix/scripts/chk_mysql.sh
在status后添加2 > /dev/null,全部添加
Uptime)
result=`/usr/bin/mysqladmin -u$MYSQL_USER -h$MYSQL_HOST -S $MYSQL_SOCK status 2 > /dev/null |cut -f2 -d":"|cut -f1 -d"T"`
echo $result
;;
Com_update)
result=`/usr/bin/mysqladmin -u$MYSQL_USER -h$MYSQL_HOST -p${MYSQL_PWD} -S $MYSQL_SOCK extended-status 2 > /dev/null |grep -w "Com_update"|cut -d"|" -f3`
echo $result
;;
添加完后,重启zabbix客户端
#service zabbix_agentd restart
在zabbix服务端重新获取数据,可以发现警告不见了
#zabbix_get -s 10.100.10.10 -k mysql.status[Com_insert]
7
我们再刷新一下zabbix中的mysql的监控项,发现已经可以启用了,如图所示:

问题解决,已经可以出数据了,个人分享的解决办法,希望能帮到大家。
以上是关于MySQL数据库的警告问题,怎么解决的主要内容,如果未能解决你的问题,请参考以下文章