如何进行变量筛选和特征选择(三)?交叉验证
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何进行变量筛选和特征选择(三)?交叉验证相关的知识,希望对你有一定的参考价值。
参考技术A 交叉验证是机器学习中常用的一种验证和选择模型的方法,常用的交叉验证方法是K折交叉验证。将原始数据分成K组(一般是均分),将每个子集分别作一次验证集,其余的K-1组子集数据作为训练集,这样会得到K个模型,k个模型的验证误差的均值即作为模型的总体验证误差,取多次验证的平均值作为验证结果,误差小的模型则为最优模型。k一般大于等于2,一般而言 k=10 (作为一个经验参数)算是相当足够了。采用的R包是bestglm,主要函数是bestglm()。
结合一个二元Logistic回归的例子,分享如何运用R软件实现10折交叉验证。
搭建完模型,运用predict()得到预测概率,保存测试集的预测概率。
函数中IC = "CV"表示采用交叉验证,CVArgs 表示交叉验证的参数,k=10表示分成10份,REP=1是每次一份作为测试集,family=binomial 表示因变量为二项分布。该函数是利用最优子集回归的原理,对于不同数量的特征,都用k折交叉验证法求一个验证误差,最后比较验证误差与特征数量的关系,选取最优变量。
将返回结果的cv列作图,可以看到在模型变量个数为3的时候,验证误差变得很小,之后随着变量个数增加,误差变化不大。利用coef()函数可查看最优变量。
根据筛选的最优变量,搭建模型,运用predict()得到预测概率。
根据ROC曲线面积对比两个模型在测试集上的预测性能,检验P值>0.05,且AUC均接近于1,说明两模型预测性能一致且很好,但交叉验证得到的模型变量为3个,模型简洁,在实际运用中效率更高,因此可选择交叉验证的模型作为最优模型。
在构建模型做变量筛选方法比较多,在前面推文中给大家介绍了2个,可以翻看一下
如何进行高维变量筛选和特征选择(一)?Lasso回归
如何进行变量筛选和特征选择(二)?最优子集回归
以上就是本次跟大家分享的内容,觉得有用的话点赞、转发哦~
scikit-learn交叉验证及其用于參数选择模型选择特征选择的样例
内容概要?
- 训练集/測试集切割用于模型验证的缺点
- K折交叉验证是怎样克服之前的不足
- 交叉验证怎样用于选择调节參数、选择模型、选择特征
- 改善交叉验证
1. 模型验证回想?
进行模型验证的一个重要目的是要选出一个最合适的模型,对于监督学习而言,我们希望模型对于未知数据的泛化能力强,所以就须要模型验证这一过程来体现不同的模型对于未知数据的表现效果。
最先我们用训练精确度(用所有数据进行训练和測试)来衡量模型的表现,这样的方法会导致模型过拟合;为了解决这一问题,我们将所有数据分成训练集和測试集两部分,我们用训练集进行模型训练。得到的模型再用測试集来衡量模型的预測表现能力,这样的度量方式叫測试精确度,这样的方式能够有效避免过拟合。
測试精确度的一个缺点是其样本精确度是一个高方差预计(high variance estimate),所以该样本精确度会依赖不同的測试集。其表现效果不尽同样。
高方差预计的样例?
以下我们使用iris数据来说明利用測试精确度来衡量模型表现的方差非常高。
from sklearn.datasets import load_iris
from sklearn.cross_validation import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn import metrics
# read in the iris data
iris = load_iris()
X = iris.data
y = iris.target
for i in xrange(1,5):
print "random_state is ", i,", and accuracy score is:"
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=i)
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(X_train, y_train)
y_pred = knn.predict(X_test)
print metrics.accuracy_score(y_test, y_pred)
以上測试准确率能够看出,不同的训练集、測试集切割的方法导致其准确率不同。而交叉验证的基本思想是:将数据集进行一系列切割。生成一组不同的训练測试集,然后分别训练模型并计算測试准确率,最后对结果进行平均处理。这样来有效减少測试准确率的差异。
2. K折交叉验证?
- 将数据集平均切割成K个等份
- 使用1份数据作为測试数据,其余作为训练数据
- 计算測试准确率
- 使用不同的測试集。反复2、3步骤
- 对測试准确率做平均。作为对未知数据预測准确率的预计
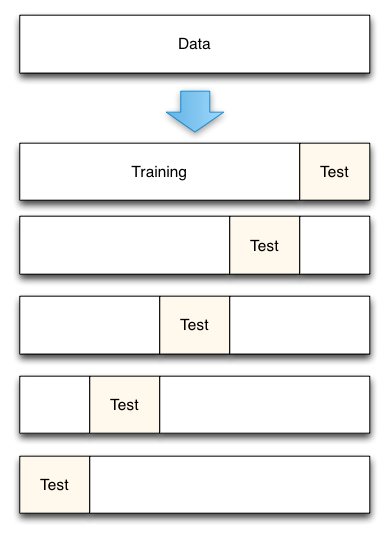
# 以下代码演示了K-fold交叉验证是怎样进行数据切割的
# simulate splitting a dataset of 25 observations into 5 folds
from sklearn.cross_validation import KFold
kf = KFold(25, n_folds=5, shuffle=False)
# print the contents of each training and testing set
print ‘{} {:^61} {}‘.format(‘Iteration‘, ‘Training set observations‘, ‘Testing set observations‘)
for iteration, data in enumerate(kf, start=1):
print ‘{:^9} {} {:^25}‘.format(iteration, data[0], data[1])
3. 使用交叉验证的建议?
- K=10是一个一般的建议
- 假设对于分类问题。应该使用分层抽样(stratified sampling)来生成数据。保证正负例的比例在训练集和測试集中的比例同样
from sklearn.cross_validation import cross_val_score
knn = KNeighborsClassifier(n_neighbors=5)
# 这里的cross_val_score将交叉验证的整个过程连接起来,不用再进行手动的切割数据
# cv參数用于规定将原始数据分成多少份
scores = cross_val_score(knn, X, y, cv=10, scoring=‘accuracy‘)
print scores
# use average accuracy as an estimate of out-of-sample accuracy
# 对十次迭代计算平均的測试准确率
print scores.mean()
# search for an optimal value of K for KNN model
k_range = range(1,31)
k_scores = []
for k in k_range:
knn = KNeighborsClassifier(n_neighbors=k)
scores = cross_val_score(knn, X, y, cv=10, scoring=‘accuracy‘)
k_scores.append(scores.mean())
print k_scores
import matplotlib.pyplot as plt
%matplotlib inline
plt.plot(k_range, k_scores)
plt.xlabel("Value of K for KNN")
plt.ylabel("Cross validated accuracy")
上面的样例显示了偏置-方差的折中,K较小的情况时偏置较低。方差较高。K较高的情况时。偏置较高,方差较低;最佳的模型參数取在中间位置,该情况下,使得偏置和方差得以平衡,模型针对于非样本数据的泛化能力是最佳的。
4.2 用于模型选择?
交叉验证也能够帮助我们进行模型选择,下面是一组样例,分别使用iris数据,KNN和logistic回归模型进行模型的比較和选择。
# 10-fold cross-validation with the best KNN model
knn = KNeighborsClassifier(n_neighbors=20)
print cross_val_score(knn, X, y, cv=10, scoring=‘accuracy‘).mean()
# 10-fold cross-validation with logistic regression
from sklearn.linear_model import LogisticRegression
logreg = LogisticRegression()
print cross_val_score(logreg, X, y, cv=10, scoring=‘accuracy‘).mean()
4.3 用于特征选择?
以下我们使用advertising数据,通过交叉验证来进行特征的选择,对照不同的特征组合对于模型的预測效果。
import pandas as pd
import numpy as np
from sklearn.linear_model import LinearRegression
# read in the advertising dataset
data = pd.read_csv(‘http://www-bcf.usc.edu/~gareth/ISL/Advertising.csv‘, index_col=0)
# create a Python list of three feature names
feature_cols = [‘TV‘, ‘Radio‘, ‘Newspaper‘]
# use the list to select a subset of the DataFrame (X)
X = data[feature_cols]
# select the Sales column as the response (y)
y = data.Sales
# 10-fold cv with all features
lm = LinearRegression()
scores = cross_val_score(lm, X, y, cv=10, scoring=‘mean_squared_error‘)
print scores
这里要注意的是,上面的scores都是负数,为什么均方误差会出现负数的情况呢?由于这里的mean_squared_error是一种损失函数,优化的目标的使其最小化。而分类准确率是一种奖励函数,优化的目标是使其最大化。
# fix the sign of MSE scores
mse_scores = -scores
print mse_scores
# convert from MSE to RMSE
rmse_scores = np.sqrt(mse_scores)
print rmse_scores
# calculate the average RMSE
print rmse_scores.mean()
# 10-fold cross-validation with two features (excluding Newspaper)
feature_cols = [‘TV‘, ‘Radio‘]
X = data[feature_cols]
print np.sqrt(-cross_val_score(lm, X, y, cv=10, scoring=‘mean_squared_error‘)).mean()
因为不增加Newspaper这一个特征得到的分数较小(1.68 < 1.69)。所以,使用全部特征得到的模型是一个更好的模型。
參考资料?
- scikit-learn documentation: Cross-validation, Model evaluation
- scikit-learn issue on GitHub: MSE is negative when returned by cross_val_score
- Scott Fortmann-Roe: Accurately Measuring Model Prediction Error
- Harvard CS109: Cross-Validation: The Right and Wrong Way
- Journal of Cheminformatics: Cross-validation pitfalls when selecting and assessing regression and classification models
以上是关于如何进行变量筛选和特征选择(三)?交叉验证的主要内容,如果未能解决你的问题,请参考以下文章