
扫码关注公众号
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了哪些搜索引擎完全支持布尔检索?相关的知识,希望对你有一定的参考价值。
所有的搜索引擎都完全支持布尔检索
布尔检索是最基础,也是使用最广泛的信息检索模型了。所谓布尔查询就是通过AND、OR、NOT等逻辑操作符将检索词连接起来的查询。比如:
那么,布尔检索时如何利用倒排索引进行查询的呢?我们还是先从词汇文档矩阵说起吧~
从词汇文档矩阵说起
我们先假设我们有一个词汇文档矩阵,如下所示:

当我进行布尔查询的时候,其实本质就是在为文档矩阵中的每行1和0组成的二进制数做布尔逻辑运算。
AND操作就是,相同的位同时为1,则结果为1,否则为0。李白 AND 杜甫最终得出的结果就是文档1和文档2。
OR操作就是,相同的位有一个位1,则结果为1,都为0结果才是0。杜甫 OR 白居易最终得出的结果就是所有的文档。
NOT操作就是先将NOT之后的内容取反,再进行AND操作。李白 NOT 苏轼最终得出的结果就是文档1和文档6。
我们可以发现使用词汇文档矩阵的话,进行布尔检索十分简单。但是我们在“搜索引擎概述之倒排索引”(回复“倒排索引”查看)中说过,词汇文档矩阵是稀疏的,极其浪费空间资源,使用这种结构存储大量的数据是不现实的。因此,我们要使用的是倒排索引。
倒排索引的布尔查询
那么在倒排索引中我们如何进行布尔查询呢?首先我们先将上边的词汇文档矩阵转换为倒排索引:

那么,如果我们进行:“李白 AND 白居易”的查询则会进行如下操作:
1. 在词典中定位“李白”
2. 返回其倒排记录:“1,2,6”
3. 在词典中定位“白居易”
4. 返回其倒排记录:“1,2,4,5,6”
5. 对另个倒排记录表求交集
最终的得到的结果就是“1,2”,也就是文档1和文档2。
同理,OR查询就是取并集,NOT查询就是从从第一个倒排记录中排除第二个倒排记录的内容。为了高效的完成交集,并集和排除操作,一般我们会要求倒排记录中的文档id是有序的。
下面我们以三种操作中比较复杂的求交集为例,来说一下布尔查询的算法实现。一种比较常见的倒排记录求交集的算法如下面伪代码所示:

我们的倒排记录是有序的。我们依次比对两个倒排记录中文档id的值。如果,如果两者id一样则输出该id,然后同时比对下一个文档id。如果两者id不一样,则较大的那个不变,之后去和较小的id的下一个id去做比对。这个算法的时间复杂度是O(x+y),也就是O(N),要远优于无序列表依次作比对的O(N²)。
优化
当我们去查询一种多个AND组成的查询时,其实本质上就是依次取交集。而且我们很容易知道,对于上边所述的算法来说,如果其中一个集合越短,那么计算可能就越快。因此一个启发式的优化方法就是,在取多个交集的时候,不是去依次的计算,而是先将倒排记录表按照长度从小到大排列,我们先合并最短的两个倒排记录表。这样所有的中间结果的大小都不会超过最短的倒排记录表。因为多个集合的交集元素个数,一定不会大于其中任何一个集合的元素个数。
如果两个倒排记录表的元素个数差距极大的时候(比如比较极端的:1和10000),我们就没必要依次去比较它们的元素了。采用对短列表中的全部元素分别在长列表中做二分查找的方式,可能会更快。
另外,使用跳表的方式去实现倒排记录表,也可以加快倒排记录表求交集的速度。但是,由于跳表是一种用空间换时间的数据结构,因此会占用更大的空间。同时,虽然现代计算机的cpu运算速度很快,但是磁盘的访问速度依旧很慢。在这样的前提下,如果是一个将所有索引数据都存在内存中的搜索引擎,使用跳表会加快速度;但如果是将索引数据存储在硬盘上的搜索引擎,反而可能会大大的降低速度。由于篇幅有限,我无法在这里详细的介绍跳表这种数据结构的实现。在未来的文章中我会单独介绍这种数据结构,到时候会再次深入的讨论这个问题。
布尔查询的缺点
布尔查询的本质只是查询了某些词汇在文档中的有无,但是却无法告诉用户哪些是更相关的,哪些是不那么相关的。也就是说,布尔查询本身无法按照相关度进行排序。
评价搜索引擎的最重要的两个指标就是正确率和召回率。
·正确率:返回的结果真正的和用户信息需求相关的文档所占的比率。
·召回率:所有和用户 信息需求真正相关的文档中检索系统返回的百分比。
比如说如果每次查询,我都将所有的文档返回,召回率必然是100%(所有的文档中必然包含所有的相关文档),但是正确率就会很低很低(100万文档中只有1万文档真的和需求相关)。而如果我每次只返回一条数据,而且保证这条数据百分之百和用户需求相关,那么正确率就是百分之百(共返回1篇文档,有1篇和用户信息相关,因此是百分之百) ,但召回率很低(1万篇相关文档之返回1篇)。
使用布尔查询在实际应用中会遇到这样的问题:
如果我要查一篇名字为“Semantic information retrieval research based on co-occurrence analysis”的文章,如果我将所有的空格都识别为AND,这时就只会返回标题为这篇文章的文档,用户无法获得任何其他相关信息。此时正确率很高,但召回率很低。同样,如果我将所有的空格都识别为OR,这时我虽然会获得相关信息了,但是很可能很多相关信息只和information有关,但这并不是我想要的。因此此时虽然召回率很高,但是正确率很低。布尔检索在召回率的问题上很容易走两个极端,很难达到理想的均衡状态。
然而在检索引擎几十年的发展中,已经有很多方案在完善这些问题,或者说在增强布尔查询的能力。而另一方面,也有了一些新的检索模型或技术(如,自由文本查询)来解决这些问题。
追问那near,with的运算符也是全部搜索引擎适用?
参考技术A 很抱歉,这个问题我们无法回答,对于这个问题我没有办法解决不敢给轻易给你方法和建议,请咨询相关人员给你正确解答,祝您生活愉快。移动互联网时代搜索引擎依然是重要流量来源以及流量分发渠道,虽然比PC互联网时代权重有所降低。
各大电商淘宝、京东80-90%交易额也是由用户app内搜索、网站内搜索产生,个性化推荐系统本身也和搜索
引擎无论技术还是产品方方面面都与搜索引擎有着关联,我们每天也都和搜索引擎打着交道,搜索知识、
搜索问题、搜索新闻、了解世界,搜索引擎价值巨大,作为一个技术人应该了解他并不断深入了解他。
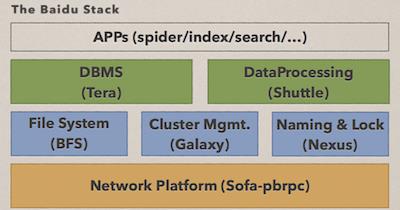
百度第三代搜索引擎架构
当我们使用搜索引擎检索信息时,输入想要查找检索词,点击回车,搜索引擎在1s左右时间返回十篇
文档。使用他对于有一定互联网经验人来说相当方便,但其背后发生了哪些事情,是不是如前台返回这样
简洁优雅呢,下面杉枫带着大家一起一看究竟。
输入搜索词后,这时搜索引擎会进行联想词推荐、相关搜索推荐。
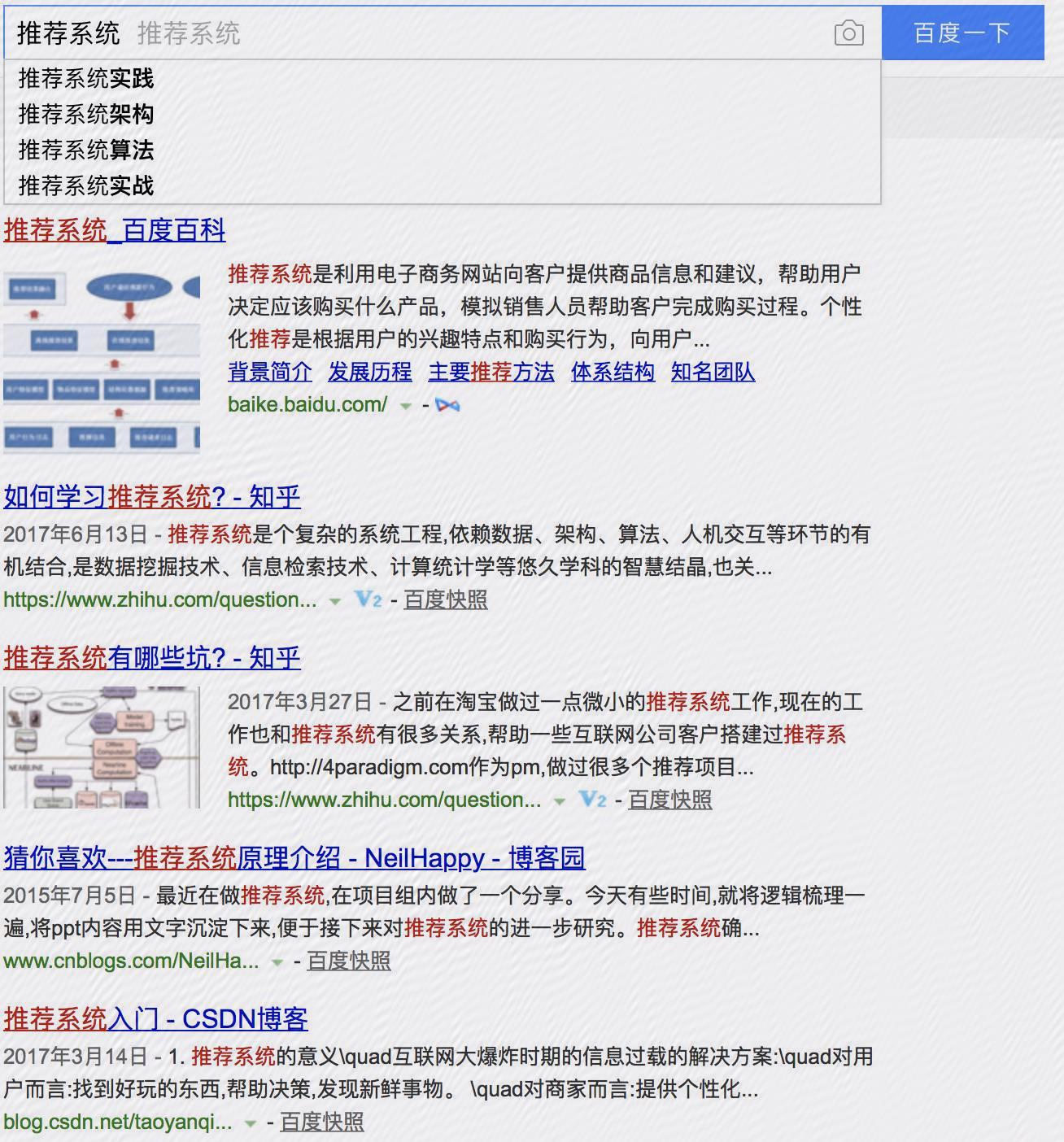
搜索联想词目的是让搜索更加准确,推荐补全选项是搜索很多并且基于输入词前缀匹配补全,这样能
更精准满足用户检索需求,极大提升用户体验,在通用搜索引擎,以及电商淘宝、京东等电商搜索是标配。
搜素词还要进行分词,分词是搜索准确前提条件,试想如果你搜索“严守一把手机关了”分词成“严守、
严守一、一把、一把手、把手、手机、机关、关了”,这样就很难搜索到想要内容了,分词要识别人物
名称。这种情况属于分词中的歧义,是分词中比较难处理问题,需要不断优化算法以及进行定时人工干
预分词,来使分词准确。
再有就是新词发现,随着社会发展以及互联网快速发展,网民会不断创建词来表达新的含义事物,
因为有研究发现新词带来的分词问题是歧义的10倍左右,所以它是分词面临的最大挑战。“老铁”、“神马”、
“怼”等等需要分词系统要能不断及时对新词进行识别,准确分词。
搜索词短语识别,对于检索词要进行短语判断,如是短语类型检索,给出和搜索短语相关词多,
并且词之间顺序位置要近,形成短语关系为打分权重一个重要依据。
搜索同义词替换,有些时候搜索内容在搜索引擎收录不多,为了满足用户搜索需求,可以将搜索词
进行同义词近义词替换,可以见搜索引擎研究杂记在微信搜索“卓越网”实例,因“卓越网”数据在微信中
不多,微信将“卓越”替换成“优秀”进行搜索文章召回,虽然体验也没有特别好,但终究给用户更多选择。
怎么找到同义词也是好问题。方法一可以通过词典,金山、网易来寻找同义词别名建立同义词库,
再有就是百科中同义,又名等抽取同义词,还可以通过多个搜索词指向同一结果,说明它们有一定几率
是同义词。以及其他方法,后边会写一篇专门做同义词词库提取。
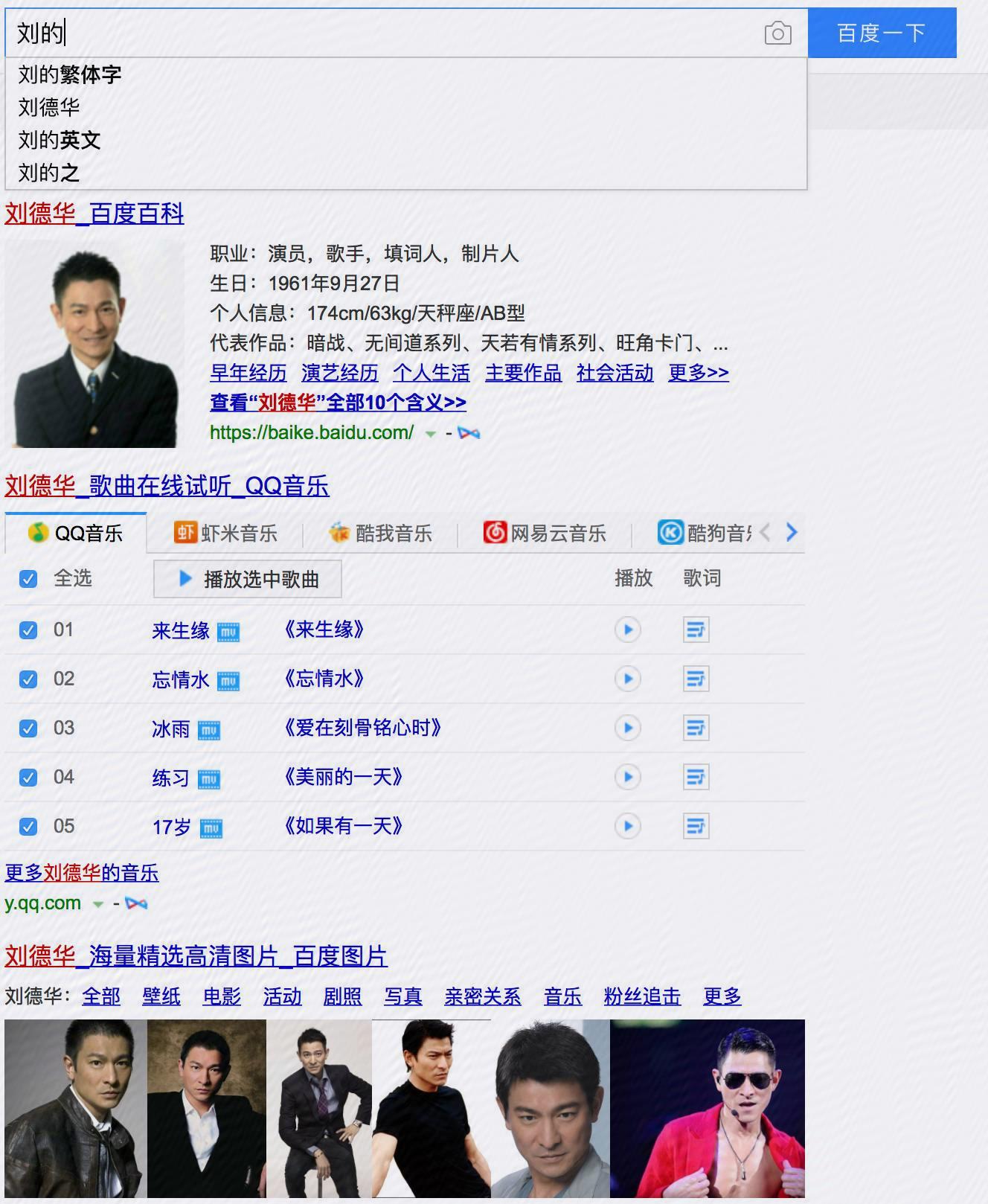
搜索词纠错,输入“刘的华”要能推荐出“刘德华”,“2084”要能推荐出“2048”,“我的后半生”要能推荐
出“我的前半生”,等等因为搜索引擎面向全部用户,很多用户不能熟练使用搜索引擎以及输入法,搜索
词纠错必不可少。
上边是列举出搜索词分词、搜索联想、搜索纠错等一系列过程基本上完成对于搜索词处理。
搜索引擎本身是个分布式系统,用户点击搜索提交搜索词后,搜索引擎收到搜索词后,在多个节点
根据倒排索引进行召回,会根据用户输入进行分词后召回,召回逻辑根据分词、同义词、短语多个维度
进行召回,召回还要包含交集关系(比如搜索“推荐系统架构”)那么包含在“推荐系统”、“架构”两个词倒
排索引下文档取交集。
用户检索内容的分词,少词下文档有几千,多的几万、几十万、几百万,这时取哪些文章进行召回
就很关键,因为磁盘IO很慢不可能实现对于几百万文章全部召回。这时就需要做两种选择,一种是离线
排序根据PageRank、网站权重、作者权重等多个维度离线打分来标识文章质量对文章进行离线排序,
搜索引擎实时召回文章时就只需几百几千个进行召回,几百、几千文章召回很好实现的,性能也没有问
题。一种是离线进行一定排序,搜索引擎实时召回实时根据F-IDF、BM25、其他特征进行打分高分存入
带返回结果集合,设置超时时间到了超时时间停止进行召回,对已存在召回集进行返回。
短语召回集要召回,包含多个词并且多个词在文章中位置近的权重高。
多于召回数据要根据TF-IDF、BM25、用户曝光后点击、跳出率等等多个特征进行打分排序,排序后
进行返回,当下搜索引擎特征因素会有上百甚至几百,但核心目的是为了找到最满足用户需求文章进行返回。
想做推荐引擎想要做好推荐引擎必须研究搜索引擎,因为他俩有千丝万缕关系,研究好了一个对于做
另一个有很多启发。
这篇是篇原理,后边会分享下百度第三代搜索引擎架构,第二代搜索引擎架构有hadoop开源存储引
擎加上c++搜索引擎构成,更新数据需要2-3周实时性差,第三代搜索引擎全部由c++开发打造,抓取更新
数据能到分钟级,性能提升三个数量级是质的飞跃,敬请期待!
微信扫码关注:
扫码关注公众号
以上是关于哪些搜索引擎完全支持布尔检索?的主要内容,如果未能解决你的问题,请参考以下文章