CUDA笔记(一)线程与数据量的关系
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CUDA笔记(一)线程与数据量的关系相关的知识,希望对你有一定的参考价值。
参考技术A或出于选择,为了要创建具有超高性能的执行配置,或出于需要,一个网格中的线程数量可能会小于数据集的大小。请思考一下包含 1000 个元素的数组和包含 250 个线程的网格(此处使用极小的规模以便于说明)。此网格中的每个线程将需使用 4 次。如要实现此操作,一种常用方法便是在核函数中使用 跨网格循环 。
在跨网格循环中,每个线程将在网格内使用 threadIdx + blockIdx*blockDim 计算自身唯一的索引,并对数组内该索引的元素执行相应运算,然后将网格中的线程数添加到索引并重复此操作,直至超出数组范围。例如,对于包含 500 个元素的数组和包含 250 个线程的网格,网格中索引为 20 的线程将执行如下操作:
CUDA 提供一个可给出网格中线程块数的特殊变量: gridDim.x 。然后计算网格中的总线程数,即网格中的线程块数乘以每个线程块中的线程数: gridDim.x * blockDim.x 。带着这样的想法来看看以下核函数中网格跨度循环的详细示例:
不同线程时间对比
n 2<<24
threadsPerBlock numberOfBlocks nanoseconds
256 1 136793984
256 16 117175743
256 32 117047986
128 1 148998083
128 16 148271881
128 32 126887351
cuda编程CUDA的运行方式以及gridblock结构关系
文章目录
1. CUDA基础知识
1.1 程序基本运行顺序
一般来说,一个cpu+gpu的程序运行如下所示:

1.2 grid与block
从GPU至线程的关系依次为:显卡(GPU)->网格(grid)->线程块(block)->线程(thread) 。从网格开始最大为3维,当然也可以1维了。
网格(grid):一个内核函数(kernel)就是一个网格,里面所有线程都在这个网格范围内,里面的线程共享全局内存空间线程块(block):一个网格可以包含很多个block,block之间可以通过“同步”和“共享内存”进行协作,block之间的区分通过“blockIdx”线程(thread):一个线程块可以包含很多个thread,thread之间区分通过threadIdx,当然如果block不一样,threadIdx肯定需要继续区分blockIdx/threadIdx:是dim3类型变量(整型),是索引线程的关键,对某个线程的索引:blockIdx.x/y/z,threadIdx.x/y/zgridDim/blockDim:也是dim3类型变量,是检查线程维数的关键,对某个线程所属的网格维数、线程块维数进行检测:gridDim.x/y/z,blockDim.x/y/z
1.3 dim类型定义
//定义参考
dim3 dd;//dd.x,dd.y,dd.z 默认为1
dim3 dd(2,3);//dd.x==2,dd.y==3,dd.z==1
//一般定义如下
dim3 grid(2,3);//就是定义一个网格,里面包含2*3*1个block
dim3 block(4,5);//就是定义一个线程块,里面包含4*5*1个thread
2. CUDA的第一个程序
下面程序是一个简单的GPU调用程序,注意一下几点:
BASE_CUDA_CHECK:为CUDA操作的验证,加上之后可以很方便的知道自己的程序在哪一行出错了。helloFromGPU:为在GPU中执行的程序。
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
#include <iostream>
#define BASE_CUDA_CHECK(condition) GPUAssert((condition), __FILE__, __LINE__);
inline void GPUAssert(cudaError_t code, const char *file, int line, bool abort = true)
if (code != cudaSuccess)
fprintf(stderr, "GPUassert: %s %s %d\\n", cudaGetErrorString(code), file, line);
if (abort)
exit(code);
__global__ void helloFromGPU()
printf("Hello World from GPU!\\n");
int main(int argc, char **argv)
//CPU端的打印输出
std::cout<<"Hello World from CPU!"<<std::endl;
// CUDA调用
helloFromGPU<<<1, 10>>>();
//CPU端的打印输出
std::cout<<"Hello World from CPU!"<<std::endl;
BASE_CUDA_CHECK(cudaDeviceReset());
return 0;
从输出可以看出,进入GPU后,CPU并不会等待GPU结束,而是CPU程序继续往下执行。
3. CUDA线程的组织结构——grid与block关系
CUDA使用多级索引的方式访问线程。
定位Block:第一级索引是(grid.xIdx, grid.yIdy),通过它我们就能找到了这个线程块的位置。定位thread:第二级索引(block.xIdx, block.yIdx, block.zIdx)来定位到指定的线程。
grid和block都是定义为dim3类型的变量,dim3可以看成是包含三个无符号整数(x,y,z)成员的结构体变量,在定义时,缺省值初始化为1。因此grid和block可以灵活地定义为1-dim,2-dim以及3-dim结构,对于图中结构(水平方向为x轴),定义的grid和block如下所示
dim3 grid(3, 2);
dim3 block(5, 3);
kernel_fun<<< grid, block >>>(prams...);
定义图解如下:

CUDA中每一个线程都有一个唯一的标识ID—ThreadIdx,这个ID随着Grid和Block的划分方式的不同而变化,这里给出Grid和Block不同划分方式下线程索引ID的计算公式。
- grid划分成1维,block划分为1维
int threadId = blockIdx.x *blockDim.x + threadIdx.x;
- grid划分成1维,block划分为2维
int threadId = blockIdx.x * blockDim.x * blockDim.y+ threadIdx.y * blockDim.x + threadIdx.x;
- grid划分成1维,block划分为3维
int threadId = blockIdx.x * blockDim.x * blockDim.y * blockDim.z
+ threadIdx.z * blockDim.y * blockDim.x
+ threadIdx.y * blockDim.x + threadIdx.x;
- grid划分成2维,block划分为1维
int blockId = blockIdx.y * gridDim.x + blockIdx.x;
int threadId = blockId * blockDim.x + threadIdx.x;
- grid划分成2维,block划分为2维
int blockId = blockIdx.x + blockIdx.y * gridDim.x;
int threadId = blockId * (blockDim.x * blockDim.y)
+ (threadIdx.y * blockDim.x) + threadIdx.x;
- grid划分成2维,block划分为3维
int blockId = blockIdx.x + blockIdx.y * gridDim.x;
int threadId = blockId * (blockDim.x * blockDim.y * blockDim.z)
+ (threadIdx.z * (blockDim.x * blockDim.y))
+ (threadIdx.y * blockDim.x) + threadIdx.x;
- grid划分成3维,block划分为1维
int blockId = blockIdx.x + blockIdx.y * gridDim.x
+ gridDim.x * gridDim.y * blockIdx.z;
int threadId = blockId * blockDim.x + threadIdx.x;
- grid划分成3维,block划分为2维
int blockId = blockIdx.x + blockIdx.y * gridDim.x
+ gridDim.x * gridDim.y * blockIdx.z;
int threadId = blockId * (blockDim.x * blockDim.y)
+ (threadIdx.y * blockDim.x) + threadIdx.x;
- grid划分成3维,block划分为3维
int blockId = blockIdx.x + blockIdx.y * gridDim.x
+ gridDim.x * gridDim.y * blockIdx.z;
int threadId = blockId * (blockDim.x * blockDim.y * blockDim.z)
+ (threadIdx.z * (blockDim.x * blockDim.y))
+ (threadIdx.y * blockDim.x) + threadIdx.x;
下面的程序是认识grid和block很好的程序,可以自己尝试改变参数调节。
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
#include <iostream>
#define BASE_CUDA_CHECK(condition) GPUAssert((condition), __FILE__, __LINE__);
inline void GPUAssert(cudaError_t code, const char *file, int line, bool abort = true)
if (code != cudaSuccess)
fprintf(stderr, "GPUassert: %s %s %d\\n", cudaGetErrorString(code), file, line);
if (abort)
exit(code);
__global__ void checkIndex(void)
printf("threadIdx:(%d, %d, %d)\\n", threadIdx.x, threadIdx.y, threadIdx.z);
printf("blockIdx:(%d, %d, %d)\\n", blockIdx.x, blockIdx.y, blockIdx.z);
printf("blockDim:(%d, %d, %d)\\n", blockDim.x, blockDim.y, blockDim.z);
printf("gridDim:(%d, %d, %d)\\n", gridDim.x, gridDim.y, gridDim.z);
int main(int argc, char **argv)
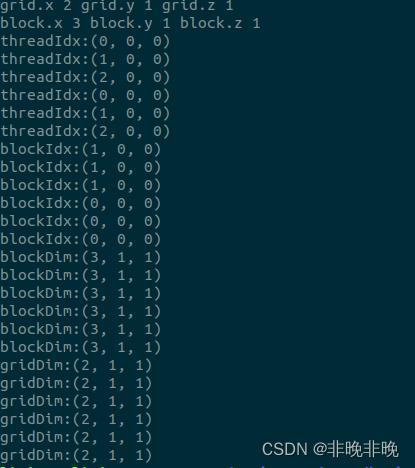
int nElem = 6;//定义总计算量
dim3 block(3);// 定义grid和block
dim3 grid((nElem + block.x - 1) / block.x);// 定义grid和block
printf("grid.x %d grid.y %d grid.z %d\\n", grid.x, grid.y, grid.z);// CPU端检测维度
printf("block.x %d block.y %d block.z %d\\n", block.x, block.y, block.z);
checkIndex<<<grid, block>>>();// GPU端检测维度
BASE_CUDA_CHECK(cudaDeviceReset());// 恢复GPU
return 0;
输出如下,因为GPU之间是并行执行的,所以它们的输出顺序也是不固定的。
以上是关于CUDA笔记(一)线程与数据量的关系的主要内容,如果未能解决你的问题,请参考以下文章