nacos源码分析——raft如何选举
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了nacos源码分析——raft如何选举相关的知识,希望对你有一定的参考价值。
参考技术A 在上一篇文章 https://www.jianshu.com/p/b0cdaa64688e 说到了如果follower长时间收不到leader的心跳,就会发起leader选举。具体的过程是怎么样的呢?public static final String API_VOTE = UtilsAndCommons.NACOS_NAMING_CONTEXT + "/raft/vote";
收到请求的处理过程是:
发起投票的节点收集到回应之后就开始处理了:
public int majorityCount()
return peers.size() / 2 + 1;
超过半数,表示选举新的leader成功。
我们发现这的leader成功,并不会通知其他节点修改leader。最后是怎么变成一致的呢?
看起来是不是很简单啊。。。
每次发布新的内容的时候,term都会增加。而且follower的term也会增加,最终会同步为leader的term。
假如5个节点
节点1的term为4 为leader
节点2的term为4
节点3的term为4
节点4的term为3
节点5的term为3
节点1这个leader挂的情况下,
同样,节点3也是可以选举成功的。这个就看节点2,3谁先开始选举了,谁先,谁就是新的leader。
每次发起投票的时候都会给自己的term加1 ,是这里制造term的差异的:
这个是为了减少选举冲突。对方比自己的term大1,自己不放弃这一轮选举的话,自己发起选举,term会加1,其实term就一样大了,可能的结果就是两个都选举不成功。
local.term.addAndGet(PUBLISH_TERM_INCREASE_COUNT);
public static final int PUBLISH_TERM_INCREASE_COUNT = 100;
上面也看到了,每次发起投票都term都会加1,如果发布内容也是加一的话,内容落后的节点第二次发起投票的时候就是加2了,term居然高过内容最新的节点。这个时候就不对了。
100其实就是允许重新发起投票的次数,这个数字越大越安全,100这个数字已经足够大了,100轮投票都产生不了leader,这个概率可以忽略不计了。
假如一个节点只是和leader不通,和其他节点都是通的。刚开始的时候,他的term其实是最新的,所以它是可以成功选自己为leader的。
这个时候看起来就会有两个leader,其他节点认为旧的leader是ok的,所以不会重新投票选举。但是其他节点会受到这两个leader的心跳,只是对于第二个心跳会报错而已。。这种情况确实有点蛋疼,不过理论上很少发生这种情况的。
选举发生冲突,都失败的时候,等待下一轮选举的时间是15~20秒,感觉这个时间等得太久了。
而且随机的区间就是0-5000 ms,这个命中比较接近的数字还不小,搞不好下一轮还冲突。那就一共等30多秒了。。
public void resetLeaderDue()
leaderDueMs = GlobalExecutor.LEADER_TIMEOUT_MS + RandomUtils.nextLong(0, GlobalExecutor.RAMDOM_MS);
public static final long LEADER_TIMEOUT_MS = TimeUnit.SECONDS.toMillis(15L);
基于raft选举的流程的nacos源码分析
raft选举
raft选举算法是相对比较简单好理解的解决分布式系统中的一致性问题的算法,算法主要包括了选举和心跳两块。选举主要是选举leader,按照任期大小,来决定谁是leader。在选举中的角色有三个Follower、Candidate、Leader
Leader: 处理所有客户端交互,数据或者日志复制等,一般一次只有一个Leader,是整个集群中的领导者,负责与follower之间的数据交互,数据复制,数据管理,数据写入等,leader中的数据是整个集群中的“标准数据”,他通过主动与follow交互来进行节点状态管理,数据同步操作。
Follower: 类似选民,完全被动。被leader管理。
Candidate候选人: 类似Proposer律师,可以被选为一个新的领导人。是一个中间状态,只有选举时才会出现,选举结束后,此状态要不变成leader,要不变成follower
选举规则
任何一个服务器都可以成为一个候选者Candidate,它向其他服务器Follower发出选举请求:
fellower按照传入的任期(任期越大,表名存活时间越长,每次心跳时,leader会将自己任期+1,来标示下一个任期的开始)来投票:投票规则:给任期越大的节点投票,并将自己的投票结果返回给发起的候选人。
候选人获取投票结果后,进行投票结果统计,选举结果只有总结果大于只要达到N/2 + 1 的大多数票,候选人还是可以成为Leader的。
心跳:
只有leader会定时发送心跳给除过自己的其他节点(注意不单单是follower),心跳主要维护集群的状态,任期。并进行数据同步。
具体的实现可以参看nacos中基于http协议实现的raft方式
nacos选举分析
其中nacos选举比较重要的两个东西一个是心跳,通过心跳同步整个集群的状态数据,主要是由leader向fellow发起心跳,来更新整个集群leader的变化,数据的同步处理。
选举是启动是进行进程,选举采用raft选举流程。
启动时启动选举线程和心跳线程
nacos raft(验证以上理论)
nacos选举流程如下:
1. 启动时,进行选举和心跳线程处理。源码如下(com.alibaba.nacos.naming.consistency.persistent.raft. RaftCore)中进行
代码如下:
其中心跳和选举都是定时执行,选举默认为500毫秒执行一次
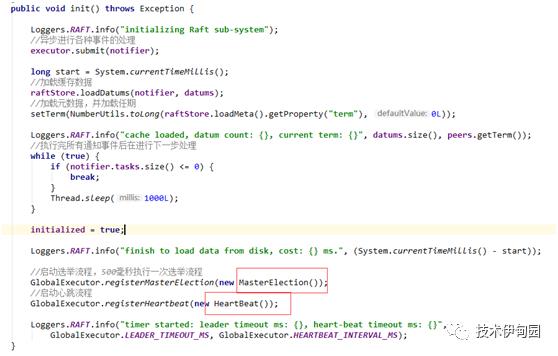
2.MasterElection选举线程
设置如果peers初始化时直接不进行选举,等待下次进行,到达下次选举间隔时,触发选举请求:
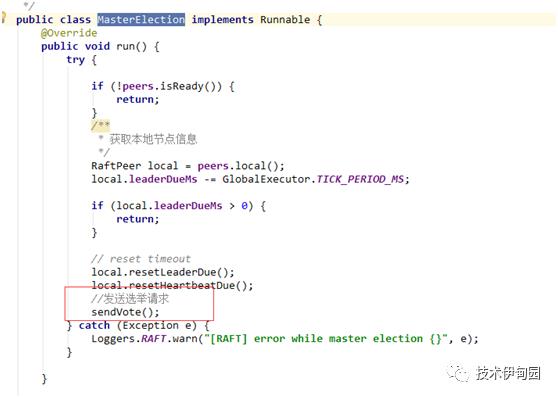
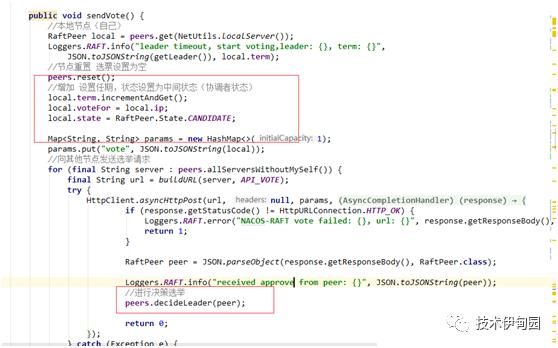
sendVote 发起选举逻辑如下:
1.设置自己的任期加1
2.设置自己自己选自己
3.将自己设置为候选人。
4.发起选举(给集群中每个节点的/v1/ns/raft/vote请求进行选举),节点返回选票结果后,执行选举方法
decideLeader:依据返回的结果进行leader选举:
1.将选票结果先保存。
2.统计得票最高的节点和票数
3.如果选票超过一半时,将此节点设置为leader节点,广播选举完成事件。
4.返回选举的leader
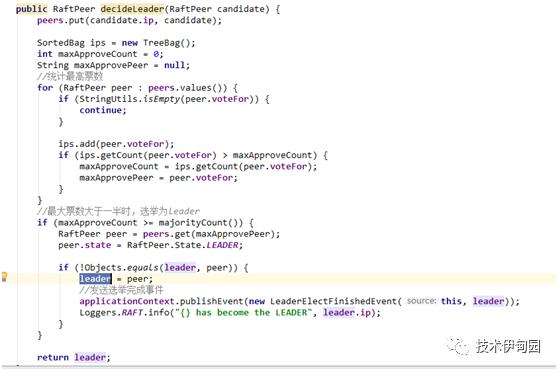
至此选举完成,选举出leader,如果选票未过半,则在下一个周期继续执行选举算法,直到选举出leader。
我们看一下选票时如何处理的(/v1/ns/raft/vote)处理流程:
具体代码如下:
/**
*
*投票逻辑:
* 如果发起选举的节点任期小于等于他本地任期是,如果没有参与投票,就投自己 如果参与过投票
* 将票投给之前投的人,这样就保证了谁先来就投谁,并且此方法是线程同步方法,保证了并发,
* 不会出现想,两个候选人过来后,投票结果不一致的情况。保证选举时,可以选举出来leader
*如果发起投票节点的任期大于本地节点时,本地节点设置为follower,将选票投给远程
* @param remote
* @return
*/
public synchronizedRaftPeer receivedVote(RaftPeer remote) {
//判断请求的票据信息的主机是不是在所有点到点的列表中,如果没有说明没有资格选举
if (!peers.contains(remote)) {
throw new IllegalStateException("can not find peer: " + remote.ip);
}
//获取本地服务信息
RaftPeer local = peers.get(NetUtils.localServer());
//本地选票大于远程选票时,投票给本地服务,并告诉远程点,本次选举对象
if (remote.term.get() <= local.term.get()) {
String msg = "received illegitimate vote" +
", voter-term:" + remote.term + ", votee-term:" + local.term;
Loggers.RAFT.info(msg);
//选自己
if (StringUtils.isEmpty(local.voteFor)) {
local.voteFor = local.ip;
}
return local;
}
//如果远程对象大于本地对象时:
//设置leader处理时间
local.resetLeaderDue();
//本地状态设置为follower
local.state = RaftPeer.State.FOLLOWER;
//本地选票为远程IP
local.voteFor = remote.ip;
//同步本地任期为选举任期
local.term.set(remote.term.get());
Loggers.RAFT.info("vote {} as leader, term: {}", remote.ip, remote.term);
return local;
}
至此整个选举完成,如果本次选举未选择出leader,下一个周期继续选择直到完全选举出来。
此方法思考:如果同时有两以上候选人进行投票时,如果保证唯一:通过同步代码块保证同时只处理一个选票动作。
/**
*
* 投票逻辑:
* 如果发起选举的节点任期小于等于他本地任期是,如果没有参与投票,就投自己如果参与过投票
* 将票投给之前投的人,这样就保证了谁先来就投谁,并且此方法是线程同步方法,保证了并发,
* 不会出现想,两个候选人过来后,投票结果不一致的情况。保证选举时,可以选举出来leader
* 如果发起投票节点的任期大于本地节点时,本地节点设置为follower,将选票投给远程
nacos心跳
启动时,发送心跳,只有节点为leader时才会去向各个follower广播数据。处理流程如下:
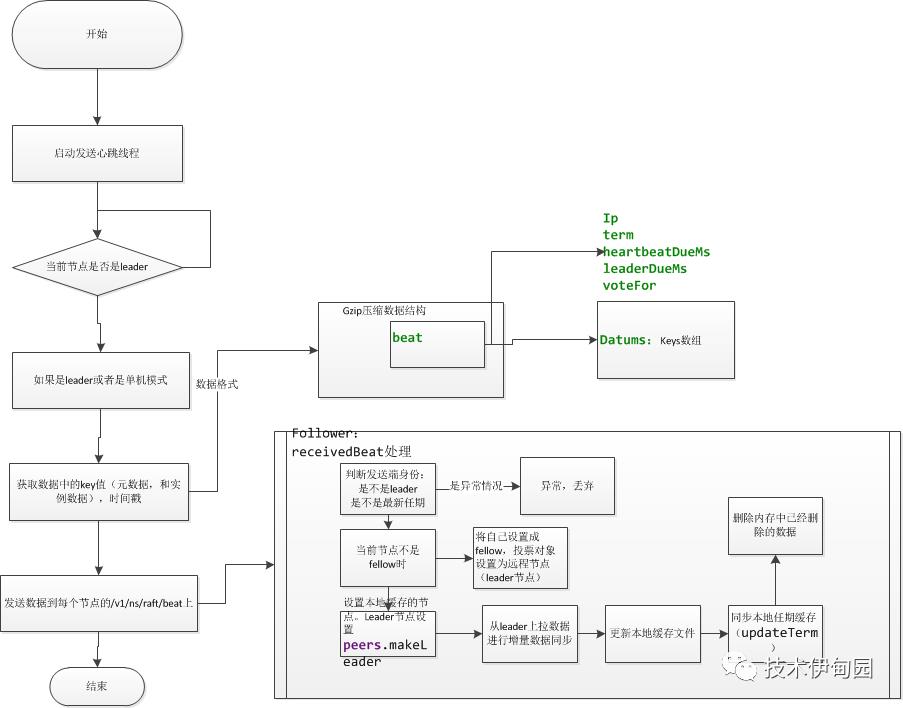
源码如下:
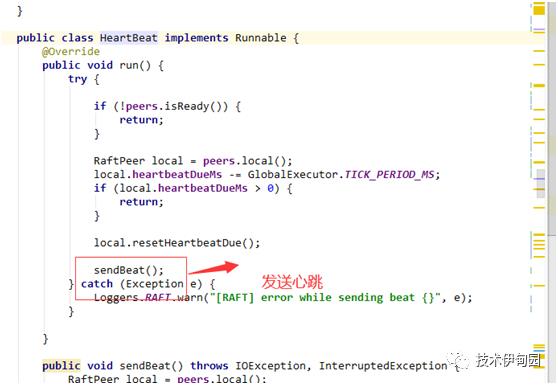
sendBeat如下:
public voidsendBeat()throwsIOException, InterruptedException {
RaftPeer local =peers.local();
//如果不是leader并且不是单机模式直接返回
if(local.state != RaftPeer.State.LEADER && !STANDALONE_MODE) {
return;
}
if(Loggers.RAFT.isDebugEnabled()) {
Loggers.RAFT.debug("[RAFT] send beat with {} keys.",datums.size());
}
local.resetLeaderDue();
// build data
JSONObject packet =newJSONObject();
packet.put("peer", local);
JSONArray array =newJSONArray();
if(switchDomain.isSendBeatOnly()) {
Loggers.RAFT.info("[SEND-BEAT-ONLY] {}", String.valueOf(switchDomain.isSendBeatOnly()))
}
if(!switchDomain.isSendBeatOnly()) {
for(Datum datum :datums.values()) {
JSONObject element =newJSONObject();
if(KeyBuilder.matchServiceMetaKey(datum.key)) {
element.put("key", KeyBuilder.briefServiceMetaKey(datum.key));
}else if(KeyBuilder.matchInstanceListKey(datum.key)) {
element.put("key", KeyBuilder.briefInstanceListkey(datum.key));
}
element.put("timestamp", datum.timestamp);
array.add(element);
}
}
packet.put("datums", array);
// broadcast
Map<String, String> params =newHashMap<String, String>(1);
params.put("beat", JSON.toJSONString(packet));
String content = JSON.toJSONString(params);
ByteArrayOutputStream out =newByteArrayOutputStream();
GZIPOutputStream gzip =newGZIPOutputStream(out);
gzip.write(content.getBytes(StandardCharsets.UTF_8));
gzip.close();
byte[] compressedBytes = out.toByteArray();
String compressedContent =newString(compressedBytes, StandardCharsets.UTF_8);
if(Loggers.RAFT.isDebugEnabled()) {
Loggers.RAFT.debug("raw beat data size: {}, size of compressed data: {}",
content.length(), compressedContent.length());
}
//发送心跳
for (final String server : peers.allServersWithoutMySelf()) {
try {
final String url = buildURL(server, API_BEAT);
if (Loggers.RAFT.isDebugEnabled()) {
Loggers.RAFT.debug("send beat to server " + server);
}
HttpClient.asyncHttpPostLarge(url, null, compressedBytes, newAsyncCompletionHandler<Integer>() {
@Override
publicInteger onCompleted(Response response)throwsException {
if(response.getStatusCode() != HttpURLConnection.HTTP_OK) {
Loggers.RAFT.error("NACOS-RAFT beat failed: {}, peer: {}",
response.getResponseBody(),server);
MetricsMonitor.getLeaderSendBeatFailedException().increment();
return1;
}
peers.update(JSON.parseObject(response.getResponseBody(), RaftPeer.class));
if(Loggers.RAFT.isDebugEnabled()) {
Loggers.RAFT.debug("receive beat response from: {}",url);
}
return0;
}
@Override
public voidonThrowable(Throwable t) {
Loggers.RAFT.error("NACOS-RAFT error while sending heart-beat to peer: {} {}",server, t);
MetricsMonitor.getLeaderSendBeatFailedException().increment();
}
});
}catch(Exception e) {
Loggers.RAFT.error("error while sending heart-beat to peer: {} {}", server, e);
MetricsMonitor.getLeaderSendBeatFailedException().increment();
}
}
}
}
各个节点收到心跳处理如下:
判断发送心跳的是不是leader,当前节点任期是不是符合条件
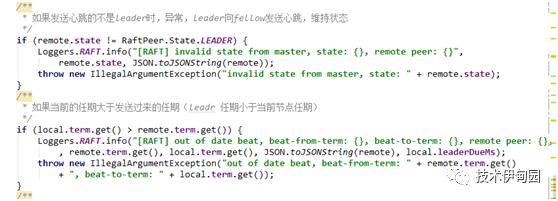
当前节点节点如果不是fellow直接将其设置为follower,为什么会有这个判断:就是节点都在系统在启动,还未选出leader时,大家的状态都是候选人,一个节点被选举出来后,第一次发心跳时,就会出现此节点上的状态不是follower,就将其设置为fellow 选举结束了

3.设置本地集群节点中的leader:
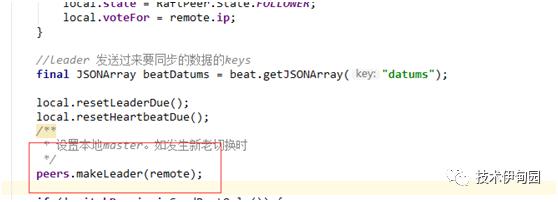
此方法主要是设置本节点上的各个节点的状态,防止缓存里面的节点不一致。逻辑如下:
同步设置本地缓存中的leader为远程的发起心跳的leader,
防止出现两个leader情况
* 流程如下:
* 1.获取本地所有出除发送心跳的leader节点还是leader的节点
此问题会在leader切换时发生。
* 2.调用leader节点的/v1/ns/raft/peer获取此点的最新状态
* 3.如果leader异常了:则将缓存中的leader状态设置为fellow,
* 4.如果节点没有异常,则直接更新此节点的状态
* 5.更新远程leader状态
public RaftPeer makeLeader(RaftPeer candidate) {
/**
* 当前的leader不是远程的发送的leader时,进行leader切换。
* 出现这种情况是:大多数fellow已经选举出了leader
* 但是此节点还未收到选举没有在本节点推举出新leader还是原来的老leader
* 这是进行leader切换以活的leader为准,保证集群中的leader的唯一性,防止出现leader不一致
*
*/
if (!Objects.equals(leader, candidate)) {
leader = candidate;
applicationContext.publishEvent(new MakeLeaderEvent(this, leader));
Loggers.RAFT.info("{} has become the LEADER, local: {}, leader: {}",
leader.ip, JSON.toJSONString(local()), JSON.toJSONString(leader));
}
for (final RaftPeer peer : peers.values()) {
Map<String, String> params = new HashMap<>(1);
/**
* 上面情况都是集群leader与本地节点缓存leader不一致时,新老leader发生切换时。
* 当前条件满足情况如下
* 1。如果本节点缓存集群数据中的leader不是远程节点(不是集群里的leader时)
*
*/
if (!Objects.equals(peer, candidate) && peer.state == RaftPeer.State.LEADER) {
try {
//从老leader获取当前信息
String url = RaftCore.buildURL(peer.ip, RaftCore.API_GET_PEER);
HttpClient.asyncHttpGet(url, null, params, new AsyncCompletionHandler<Integer>() {
@Override
public Integer onCompleted(Response response) throws Exception {
//如果失败,说明老leader挂了,直接将老leader设置为fellow状态
if (response.getStatusCode() != HttpURLConnection.HTTP_OK) {
Loggers.RAFT.error("[NACOS-RAFT] get peer failed: {}, peer: {}",
response.getResponseBody(), peer.ip);
peer.state = RaftPeer.State.FOLLOWER;
return 1;
}
//重新设置远程节点的状态和信息
update(JSON.parseObject(response.getResponseBody(), RaftPeer.class));
return 0;
}
});
} catch (Exception e) {
peer.state = RaftPeer.State.FOLLOWER;
Loggers.RAFT.error("[NACOS-RAFT] error while getting peer from peer: {}", peer.ip);
}
}
}
//更新本地缓存中的leader节点return update(candidate);
4.从leader拉取数据进行数据同步
1.按事件戳判断是否有改变,和传入的key找出leader有本地没有的数据
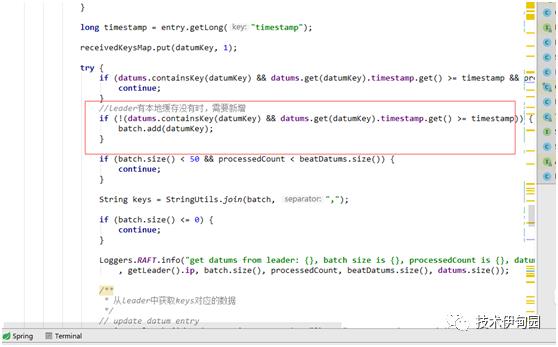
2.从leader上拉取增量数据:调用 leader的 remoteIp /v1/ns/raft/datum获取数据
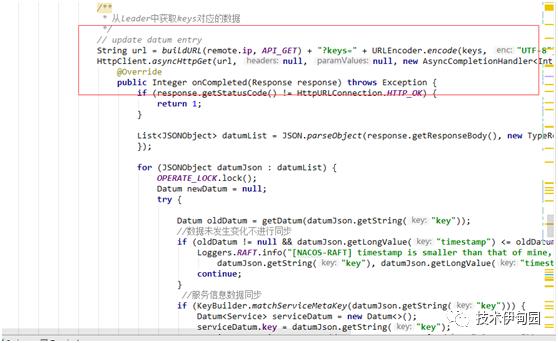
3.写入节点缓存文件,并更新节点的任期
4.删除掉leader没有,本节点里面还有的数据。
至此心跳同步完成。
raft是解决分布式系统解决一致性性问题的比较简单的方法,比paxos更容易理解和简单,今天只是简单的依据源码分析的方式进行对raft的流程进行了拆解。就当自己学习的成果,后续会持续的介绍几个比较有意思的一致性算法比如:gossip,paxos等主流算法。
吐槽一下微信这个编辑器和word兼容太不好用了,word文档粘贴过来格式全部变化了!哎!!!
以上是关于nacos源码分析——raft如何选举的主要内容,如果未能解决你的问题,请参考以下文章