应用 —— Python 处理PDF文件 给PDF文件添加书签合并PDF文件转化PPT文件为PDF文件
Posted 海绵小青年
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了应用 —— Python 处理PDF文件 给PDF文件添加书签合并PDF文件转化PPT文件为PDF文件相关的知识,希望对你有一定的参考价值。
一、本文内容
- 用python实现pdf文件书签的添加
- 用python实现ppt(或pptx)文件转pdf文件
- 用python实现合并多个pdf文件为一个文件
- 用python实现对txt目录文件排版的改变(未完成)
- 用python实现多个txt目录文件的合并(未完成)
二、具体功能实现
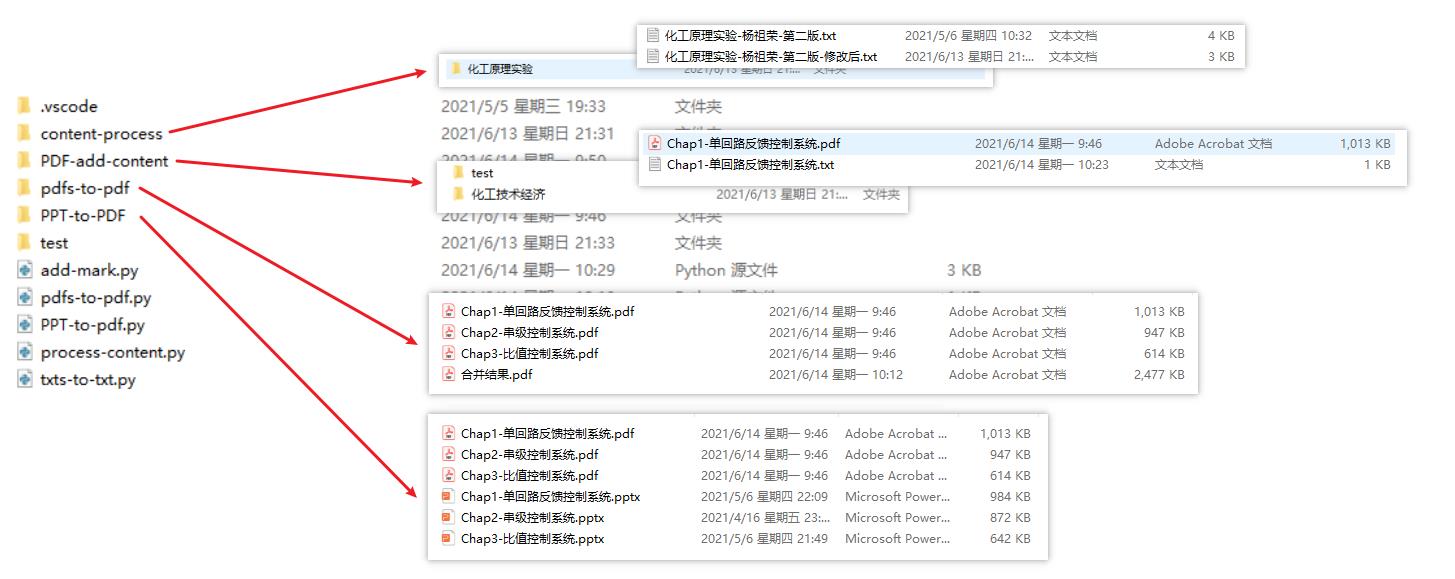
文件夹结构框图
function1:为PDF文件添加书签
- 所需python库:pyPDF2(自己安装)、os、tkinter
- 代码
# import
from PyPDF2 import PdfFileReader as pdf_read, PdfFileWriter as pdf_write
import os
from tkinter import filedialog
# file-path
fileinfo = []
temp = filedialog.askopenfilename(title='打开要添加目录的pdf文件', filetypes=[('PDF', '*.pdf'), ('All Files', '*')], initialdir=os.getcwd() + '\\\\old-pdf')
fullFilepath = temp.replace('/', '\\\\')
fileinfo.append(fullFilepath)
file_name = fullFilepath.split('\\\\')[-1]
fileinfo.append(file_name)
filepath = fullFilepath.replace(file_name, '')
fileinfo.append(filepath)
temp = filedialog.askopenfilename(title='打开对应的目录文件', filetypes=[('TXT', '*.txt'), ('All Files', '*')], initialdir=os.getcwd() + '\\\\old-pdf')
fullFilepath = temp.replace('/', '\\\\')
fileinfo.append(fullFilepath)
readFile = fileinfo[0]
content = fileinfo[3]
# read-content
with open(content, 'r', encoding='utf-8') as f:
directory_list = f.readlines()
# add-content
pdf_write = pdf_write()
with open(readFile, 'rb') as f:
pdf = pdf_read(readFile)
pages = pdf.getNumPages()
# 将测试用.pdf里面的内容拷贝到pdf_write这个pdf对象中
for i in range(pages):
page_1 = pdf.getPage(i)
pdf_write.addPage(page_1)
contentlist1 = []
contentlist2 = []
levelnum1 = 1
levelnum2 = 1
for item in directory_list:
newitem = item.split()
if int(newitem[0]) == 0:
offset = int(newitem[1])
else:
level = int(newitem[0])
title = newitem[1]
pagenum = int(newitem[2])
if level == 1:
parent1 = pdf_write.addBookmark('Chap '.format(levelnum1) + title, pagenum + offset)
contentlist1.append(parent1)
levelnum1 += 1
levelnum2 = 1
if level == 2:
parent2 = pdf_write.addBookmark(' - '.format(levelnum2) + title, pagenum + offset, contentlist1[-1])
contentlist2.append(parent2)
levelnum2 += 1
if level == 3:
pdf_write.addBookmark(title, pagenum + offset, contentlist2[-1])
with open(fileinfo[2] + fileinfo[1][0:-4] + '-带书签.pdf', 'wb+') as f:
pdf_write.write(f)
os.startfile(fileinfo[2])
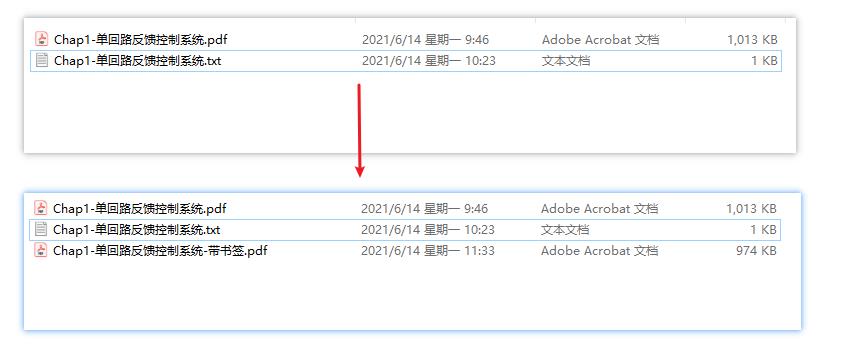
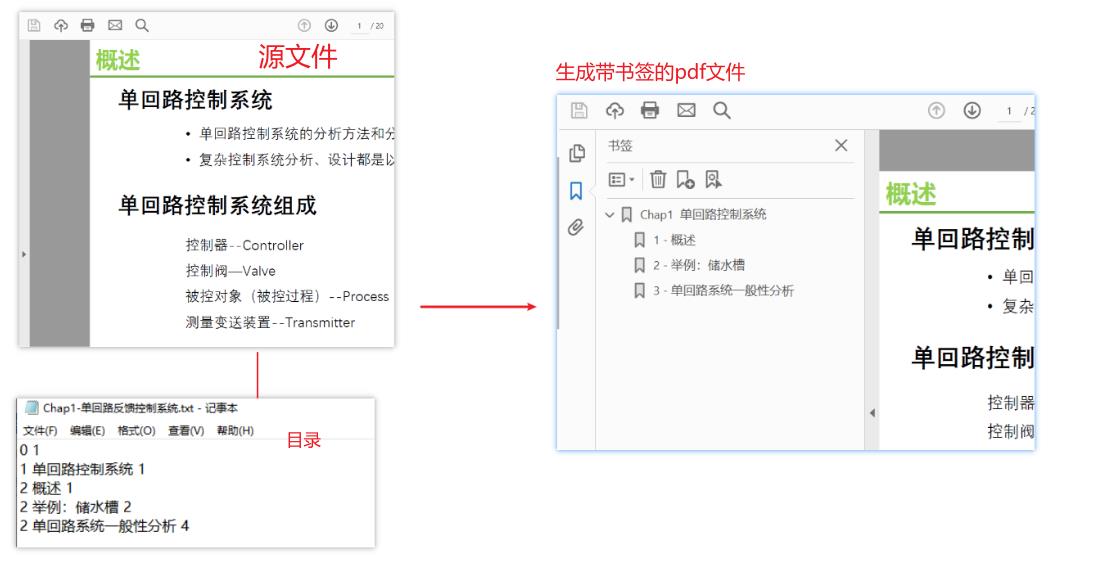
- 结果
- 注意事项

每一行第一个数字是标志位:
0是偏移量标志位,0后边的数字是偏移量,可以实负数、0、正数
因为有些pdf文件正文前边有封面、前言什么的。需要加个偏移量以保证对应书签能跳转到指定位置
偏移量可以通过多次生成带书签的pdf文件来实现,一次不对多试几次
1表示一级目录,一般是“章”级别
2表示二级目录,一般是“节”级别
3表示三级目录,一般是“节”下边的级别
目录格式排版:
首位写标志位 空格 写章节名称 空格 写章节所在页数 (回车换行)
...
(最后一行不要加回车,即不要留空白行)
function2:批量将PPT文件转化为PDF文件
- 所需python库:comtypes(自己安装)、tkinter、os
- 代码
import comtypes.client
from tkinter import filedialog
import os
def file_path():
# file-path
temp = filedialog.askdirectory()#(title='打开要处理的PPT文件', filetypes=[('All Files', '*')], initialdir=os.getcwd() + '\\\\old-pdf')
fullFilepath = temp.replace('/', '\\\\')
return fullFilepath
def init_powerpoint():
powerpoint = comtypes.client.CreateObject("Powerpoint.Application")
powerpoint.Visible = 1
return powerpoint
def ppt_to_pdf(powerpoint, inputFileName, outputFileName, formatType=32):
if outputFileName[-3:] == 'ppt':
outputFileName = outputFileName[0:-4] + ".pdf"
if outputFileName[-4:] == 'pptx':
outputFileName = outputFileName[0:-5] + ".pdf"
deck = powerpoint.Presentations.Open(inputFileName)
deck.SaveAs(outputFileName, 32) # formatType = 32 for ppt to pdf
deck.Close()
def convert_ppt_to_pdf(powerpoint, folder):
files = os.listdir(folder)
pptfiles = [f for f in files if f.endswith((".ppt", ".pptx"))]
for pptfile in pptfiles:
fullpath = os.path.join(cwd, pptfile)
ppt_to_pdf(powerpoint, fullpath, fullpath)
if __name__ == "__main__":
powerpoint = init_powerpoint()
cwd = file_path()
convert_ppt_to_pdf(powerpoint, cwd)
powerpoint.Quit()
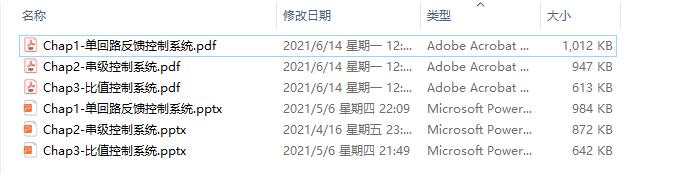
- 结果
function3:将一个文件夹下所有PDF文件合并为一个
- 所需python库:pyPDF2(自己安装)、tkinter、os
- 代码
import PyPDF2
from tkinter import filedialog
import os
def file_path():
# file-path
temp = filedialog.askdirectory()
fullFilepath = temp.replace('/', '\\\\')
return fullFilepath
def convert_pdfs_to_pdf(folder):
merger = PyPDF2.PdfFileMerger()
files = os.listdir(folder)
for pdf in files:
merger.append(PyPDF2.PdfFileReader(folder + "\\\\" + pdf))
merger.write(folder + "\\\\" + '合并结果.pdf')
if __name__ == "__main__":
cwd = file_path()
convert_pdfs_to_pdf(cwd)
- 结果

function4:更改目录格式
- PyPDF2(自己安装)、os、tkinter、re
- 代码
# import
from PyPDF2 import PdfFileReader as pdf_read, PdfFileWriter as pdf_write
import os
from tkinter import filedialog
import re
# file-path
fileinfo = []
temp = filedialog.askopenfilename(title='打开要处理的txt目录文件', filetypes=[('TXT', '*.txt'), ('All Files', '*')], initialdir=os.getcwd() + '\\\\process-content' )
fullFilepath = temp.replace('/', '\\\\')
fileinfo.append(fullFilepath) #0
file_name = fullFilepath.split('\\\\')[-1]
fileinfo.append(file_name) #1
filepath = fullFilepath.replace(file_name, '')
fileinfo.append(filepath) #2
# read-content
with open(fileinfo[0], 'r', encoding='utf-8') as f:
directory_list = f.readlines()
# process-content
new_directory_list = []
finall_directory_list = []
level1 = ['第一章', '第二章', '第三章', '第四章', '第五章', '第六章', '第七章', '第八章', '第九章', '第十章', '第十一章', '第十二章', '第十三章', '第十四章', '第十五章', '第十六章', '第十七章', '第十八章', '第十九章', '第二十章']
level2 = ['第一节', '第二节', '第三节', '第四节', '第五节', '第六节', '第七节', '第八节', '第九节', '第十节', '第十一节', '第十二节', '第十三节', '第十四节', '第十五节', '第十六节', '第十七节', '第十八节', '第十九节', '第二十节']
level3 = ['一、', '二、', '三、', '四、', '五、']
for item in directory_list:
item = item.replace('\\n', '')
for i in range(len(level1)):
if level1[i] in item:
temp = item.replace(level1[i], '1 ')
for i in range(len(level2)):
if level2[i] in item:
temp = item.replace(level2[i], '2 ')
for i in range(len(level3)):
if level3[i] in item:
temp = item.replace(level3[i], '3 ')
new_directory_list.append(temp)
for item in new_directory_list:
list = re.findall(r'\\d+', item)
item = item.replace(list[-1], ' ' + list[-1])
finall_directory_list.append(item)
with open(fileinfo[2] + fileinfo[1][0:-4] + '-修改后.txt', 'w') as f:
for item in finall_directory_list:
f.write(item)
f.write('\\n')
os.startfile(fileinfo[2])
- 结果


文件目录过长的话不必一个一个打出来,可以用电脑版QQ的图片文字提取
注意排版:
章节章节名称章节页码(回车) 注:章节和章节名称和目录之间不能有空格
两个章节之间需要留有空行
转换形式:
第一章 → 1
第一节 → 2
一、 → 3
暂不支持其他目录格式的转换,如果需要可以自行对目录修改
注意:目录里面没有偏移量这部分,可以在生成的更改格式后的txt文件中加上偏移量有关描述
function5:合并多个txt目录文件
暂无
以上是关于应用 —— Python 处理PDF文件 给PDF文件添加书签合并PDF文件转化PPT文件为PDF文件的主要内容,如果未能解决你的问题,请参考以下文章