zookeeper集群
Posted 陈如水
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了zookeeper集群相关的知识,希望对你有一定的参考价值。
zk当做微服务注册中心,相当于是Eureka server.
1)将自己注册到zk上;
2)从注册中心上获取服务的地址。这就是服务注册与发现过程。
/**
* @Author crs
* @Description 使用zookeeper实现服务注册,zookeeper当做注册中心。
* 1)当项目启动成功后,将当前项目的ip地址和端口号注册到zk;
* 2) 引入zookeeper的依赖
* @Date 2022/08/30/15:23
* @Version 1.0
*/
@Component
public class ZkRegister implements ApplicationRunner
//注册中心地址
public static String zkConnection="*.*.*.*:2181";
private static int TIMEOUT = 5000;
@Override
public void run(ApplicationArguments args) throws Exception
ZooKeeper zooKeeper = new ZooKeeper(zkConnection, TIMEOUT, new Watcher()
@Override
public void process(WatchedEvent watchedEvent)
Event.KeeperState state = watchedEvent.getState();
if (state == Event.KeeperState.SyncConnected)
System.out.println("已经连接上zk");
);
角色介绍
ZooKeeper中包含Leader、Follower和Observer三个角色;
(1)Zookeeper:一个领导者(Leader),多个跟随者(Follower)组成的集群。
(2)Zookeepe集群中只要有半数以上节点存活,Zookeeper集群就能正常服务。所以zookeeper适合安装奇数台服务器。
(3)全局数据一致:每个server保存一份相同的数据副本,client无论连接到哪个Server,数据都是一致的。
(4)更新请求顺序执行,来自同一个client的更新请求按其发送顺序依次执行,即先进先出。
(5)数据更新原子性,一次数据更新要么成功,要么失败。
(6)实时性,在一定时间范围内,client能读到最新数据。
Leader:
Zookeeper集群工作的核心
事务请求(写操作)的唯一调度和处理者,保证集群事务处理的顺序性;
集群内部各个服务器的调度者。
对于create,setData,delete等有写操作的请求,则需要统一转发给leader处理,leader需要决定编号、执行操作,这个过程称为一个事务。
Follower:
处理客户端非事务(读操作)请求,转发事务请求给 Leader;
参与集群Leader选举投票。
此外,针对访问量比较大的zookeeper集群,还可新增观察者角色。
Observer:
观察者角色,观察Zookeeper集群的最新状态变化并将这些状态同步过来,其对于非事务请求可以进行独立处理,对于事务请求,则会转发给Leader服务器进行处理。
不会参与任何形式的投票只提供非事务服务,通常用于在不影响集群事务处理能力的前提下提升集群的非事务处理能力。
Zk的管理界面 上去看看注册信息
微服务状态,方法名。
Zk管理界面:服务调用关系
服务管理平台有没有?
服务提供者和服务消费者的身份标识是什么? 肯定不一样。
ZooKeeper 是分布式应用程序的分布式开源协调服务。
ZooKeeper 数据保存在内存中,这意味着 ZooKeeper 可以实现高吞吐量和低延迟数字。
数据模型和分层命名空间:
ZooKeeper提供的命名空间,很像标准文件系统。名称是由斜杠 (/) 分隔的一系列路径元素。ZooKeeper 命名空间中的每个节点都由路径标识。
路径名称,路径url。
分层命名空间的结构是什么样的?
ZooKeeper 命名空间中的每个节点都可以拥有与其关联的数据以及子节点。每次znode的数据更改时,版本号都会增加。
ZooKeeper支持watch的概念。客户端可以在znode上设置监视。
ZooKeeper 的集群结构。
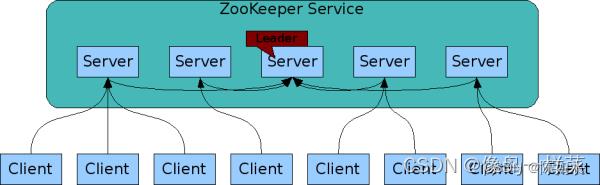
集群特点:
1,zookeeper集群拥有一主(Leader)多从(Follower),主节点提供读写,其他节点提供查询。(一主多从)
2,集群中只要有过半的节点存活,Zookeeper 集群就能正常提供服务。
3,顺序一致性 ——来自客户端的更新将按照它们发送的顺序执行。
4,统一视图 ——客户端不管连接到哪个server,看到的数据都是一致的(包括客户端连接产生的session也会统一视图)。
5,原子性 ——更新要么成功要么失败,没有中间状态。
6,可靠性 ——应用更新后,它将从那时起持续存在,直到客户端覆盖更新(数据的持久化)。
7,及时性——系统的客户视图保证在一定的时间范围内是最新的(数据的最终一致性)。
8,扩展性:通过引入observer角色,增加集群的读写能力。观察者:在不影响写入性能的情况下扩展 ZooKeeper。
以上是关于zookeeper集群的主要内容,如果未能解决你的问题,请参考以下文章